
ธนาคารไทยเปิดการทดลองใช้งาน "Voice‑KYC 2.0" เทคโนโลยียืนยันตัวตนด้วยเสียงรุ่นใหม่ที่ผสานสามกลไกสำคัญ ได้แก่ Anti‑Deepfake LLM เพื่อตรวจจับร่องรอยสังเคราะห์ของเสียง, ระบบ speaker‑embedding สำหรับเปรียบเทียบลายน้ำเสียง (voiceprint) ของผู้ใช้กับข้อมูลที่ลงทะเบียนไว้ และ liveness detection เพื่อตรวจสอบว่าเสียงที่รับมานั้นมาจากบุคคลจริงแบบเรียลไทม์ การทดลองนี้ถูกออกแบบมาเพื่อตอบโจทย์ความเสี่ยงด้านฟิชชิงและการแอบอ้างบุคคลที่เพิ่มขึ้นในยุคสื่อสารทางเสียง โดยธนาคารคาดหวังว่าจะช่วยยกระดับความแม่นยำในการยืนยันตัวตนและปรับปรุงประสบการณ์ผู้ใช้ในกระบวนการ KYC ให้รวดเร็วและปลอดภัยยิ่งขึ้น
การผสานเทคโนโลยีทั้งสามด้านมีนัยสำคัญเชิงปฏิบัติ: Anti‑Deepfake LLM วิเคราะห์ลักษณะทางสเปกตรัมและรูปแบบเชิงภาษาเพื่อแยกความแตกต่างระหว่างเสียงสังเคราะห์กับเสียงมนุษย์, speaker‑embedding เปรียบเทียบเวกเตอร์ตัวแทนเสียงกับฐานข้อมูลผู้ใช้เพื่อลดการแอบอ้างตัวตน และ liveness detection ใช้วิธีการท้าทาย‑ตอบ (challenge‑response) หรือการวัดสัญญาณชีวภาพเพื่อยืนยันความมีชีวิตของผู้พูด งานวิจัยและการทดสอบก่อนหน้านี้ชี้ให้เห็นว่าระบบยืนยันตัวตนด้วยเสียงแบบเดิมอาจถูกหลอกได้บ่อยในบางกรณี (รายงานบางฉบับพบอัตราการหลอกลวงได้ถึง 80–90% ในการทดสอบเชิงเทคนิค) ทำให้ Voice‑KYC 2.0 ถูกมองว่าเป็นก้าวสำคัญที่จะช่วยลดความเสี่ยงดังกล่าวและเพิ่มความเชื่อมั่นทั้งต่อธนาคารและผู้ใช้บริการ
บทนำ: ทำไม Voice‑KYC 2.0 จึงสำคัญต่อธนาคารไทย
บทนำ: ทำไม Voice‑KYC 2.0 จึงสำคัญต่อธนาคารไทย
ธนาคารไทยหลายแห่งกำลังทดสอบระบบ Voice‑KYC 2.0 ที่ผสานเทคโนโลยีตรวจจับการปลอมเสียงแบบเรียลไทม์ (Anti‑Deepfake LLM) กับการตรวจสอบตัวตนผ่านลักษณะเสียงเฉพาะตัว (speaker‑embedding) และการยืนยันความมีชีวิต (liveness detection) โดยเป้าหมายหลักของโครงการคือการยกระดับความมั่นคงของช่องทางการยืนยันตัวตนด้วยเสียง ลดความเสี่ยงจากการฉ้อโกง และเพิ่มความมั่นใจให้ผู้ใช้บริการเมื่อทำธุรกรรมทางการเงินผ่านช่องทางเสียง เช่น คอลเซ็นเตอร์ แอปพลิเคชันโทรศัพท์ และบริการสั่งงานด้วยเสียงบนมือถือ
ความจำเป็นของการอัปเกรดระบบเกิดจากการเติบโตอย่างรวดเร็วของเทคโนโลยีสังเคราะห์เสียง (voice deepfake) ซึ่งเป็นสาเหตุให้การยืนยันตัวตนด้วยเสียงแบบเดิม (เช่น การจับลายนิ้วเสียงหรือการตรวจสอบด้วยเกณฑ์เชิงสถิติพื้นฐาน) ไม่เพียงพอ รายงานจากผู้เชี่ยวชาญด้านความปลอดภัยชี้ว่าการโจมตีโดยใช้เสียงปลอมมีแนวโน้มเพิ่มขึ้นอย่างชัดเจนในช่วงไม่กี่ปีที่ผ่านมา — บางรายงานระบุการเพิ่มขึ้นกว่า 100% ระหว่างปี 2021–2023 — และตัวอย่างเหตุการณ์ที่เป็นข่าวโด่งดัง เช่น กรณีการใช้เสียงปลอมแอบอ้างผู้บริหารจนทำให้บริษัทในยุโรปถูกหลอกจ่ายเงินกว่า €220,000 แสดงให้เห็นถึงผลกระทบทางการเงินที่จับต้องได้
ความเสี่ยงสำหรับสถาบันการเงินไม่ได้จำกัดเพียงการสูญเสียเงินสดตรงๆ เท่านั้น แต่ยังรวมถึงความเสียหายต่อความน่าเชื่อถือของแบรนด์ การเปิดเผยข้อมูลลูกค้า (data breach) และความเสี่ยงทางกฎหมายเมื่อระบบยืนยันตัวตนถูกหลอกใช้ อีกทั้งการโจมตีด้วยเสียงยังสามารถเป็นจุดเริ่มต้นของการฉ้อโกงแบบซับซ้อน เช่น การทำ social engineering ต่อเนื่องเพื่อเข้าถึงบัญชีหรืออนุมัติธุรกรรมขนาดใหญ่ ซึ่งหากขยายเป็นเหตุการณ์วงกว้างอาจสร้างความเสียหายทางเศรษฐกิจในระดับภูมิภาค
แม้จะมีความเสี่ยง แต่ธนาคารยังคงเลือกใช้เสียงเป็นช่องทางยืนยันตัวตนเพราะมีข้อดีด้านความสะดวกและการเข้าถึงสูง โดยเฉพาะสำหรับลูกค้าที่ใช้บริการผ่านโทรศัพท์หรือผู้สูงอายุที่อาจไม่ถนัดกรอกแบบฟอร์มดิจิทัล การใช้เสียงช่วยลด friction ในกระบวนการ KYC และเพิ่มอัตราการยอมรับบริการ อย่างไรก็ตาม ความสมดุลระหว่าง convenience และ risk เป็นหัวใจของการออกแบบ Voice‑KYC 2.0: ระบบต้องให้ประสบการณ์ที่ไม่ยุ่งยากแก่ผู้ใช้ในขณะเดียวกันต้องมีมาตรการป้องกันการปลอมเสียงในระดับสูง เพื่อให้ธนาคารสามารถนำช่องทางเสียงมาใช้เป็นช่องทางยืนยันตัวตนที่ทั้งสะดวกและปลอดภัย
- ภาพรวมการทดสอบและเป้าหมาย: พิสูจน์ความแม่นยำในการแยกเสียงจริง/ปลอม ลด false positive/negative และรองรับการใช้งานเชิงปฏิบัติการในคอลเซ็นเตอร์และโมบายแบงก์กิ้ง
- ความเสี่ยงจาก deepfake: การโจมตีที่เพิ่มขึ้นและตัวอย่างความเสียหายทางการเงินที่จับต้องได้ เช่น กรณีการหลอกจ่ายเงินระดับแสนยูโร
- เหตุผลเลือกใช้เสียง: ความสะดวก ความเข้าถึง และการใช้งานที่ตอบโจทย์ลูกค้ากลุ่มกว้าง แต่ต้องเสริมด้วยเทคโนโลยีตรวจจับขั้นสูงเพื่อบริหารความเสี่ยง
สถาปัตยกรรมและองค์ประกอบเทคโนโลยีของ Voice‑KYC 2.0
สถาปัตยกรรมและองค์ประกอบเทคโนโลยีของ Voice‑KYC 2.0
ระบบ Voice‑KYC 2.0 ถูกออกแบบเป็นสถาปัตยกรรมเชิงโมดูลเพื่อรวมการตรวจจับการปลอมเสียงแบบเรียลไทม์ โดยประกอบด้วยโมดูลหลักสามส่วนที่ทำงานร่วมกันอย่างใกล้ชิด: Anti‑Deepfake LLM สำหรับวิเคราะห์เชิงเนื้อหาและสเปกตรัมเสียง, Speaker‑Embedding สำหรับจับและเทียบลักษณะเฉพาะเสียงเป็นเวกเตอร์, และ Liveness Detection เพื่อยืนยันความสดของสัญญาณเสียง การแยกหน้าที่ชัดเจนช่วยให้แต่ละโมดูลสามารถปรับแต่งให้เหมาะกับงานเฉพาะด้าน เช่น เพิ่มความแม่นยำ, ลด False Acceptance Rate (FAR) และควบคุม latency ในระบบธุรกรรมจริง
บทบาทของ Anti‑Deepfake LLM
Anti‑Deepfake LLM ทำหน้าที่เป็นชั้นวิเคราะห์เชิงสูงซึ่งรับอินพุตทั้งจากรูปแบบสเปกโตรแกรมของสัญญาณเสียง, ฟีเจอร์เชิงอะคูสติก (เช่น MFCC, filter‑bank, spectral centroid) และ embedding ของข้อความที่ได้จากการถอดคำ (ASR). โมเดลขนาดใหญ่นี้ฝึกให้จับความผิดปกติในเนื้อหาและรูปแบบ (prosody, timing, intonation) ที่มักปรากฏในเสียงสังเคราะห์หรือการตัดต่อ ตัวอย่างการใช้งานคือการวิเคราะห์ความไม่สอดคล้องกันเชิงความหมายระหว่างคำที่พูดและน้ำเสียง หรือการตรวจจับ artefact ทางสเปกตรัมที่บ่งชี้การเรนเดอร์ด้วย TTS/VC (text‑to‑speech/voice conversion). ในงานประเมินเชิงทดลอง โมเดลตรวจจับ deepfake ที่ผ่านการฝึกแบบเฉพาะงานมักให้ผลแม่นยำสูงในชุดข้อมูลควบคุม แต่ประสิทธิภาพจริงยังขึ้นกับความหลากหลายของสภาวะเสียงและคุณภาพตัวอย่าง
การสร้างและเทียบค่า Speaker‑Embedding
การยืนยันตัวบุคคลด้วยเสียงใช้เวกเตอร์ลักษณะเสียง (speaker‑embedding) ซึ่งสกัดด้วยสถาปัตยกรรมเช่น x‑vector และ ECAPA‑TDNN. กระบวนการทั่วไปคือ: (1) แปลงสัญญาณเป็น frames และสกัดฟีเจอร์เช่น MFCC/FBANK, (2) ป้อนฟีเจอร์เข้าเครือข่าย TDNN/ECAPA‑TDNN เพื่อสร้าง embedding มิติที่เป็นมาตรฐาน (มักอยู่ในช่วง 192–512 มิติ), (3) เก็บ embedding ช่วง enrollment เป็นเทมเพลต (มักใช้การเฉลี่ยเชิงสถิติหรือหลากหลายตัวอย่าง) และ (4) ใช้การเทียบค่าด้วย cosine similarity หรือ PLDA scoring เพื่อกำหนดคะแนนความเชื่อมโยง ตัวอย่างเช่น ระบบที่ปรับแต่งดีบนชุดข้อมูลภายในอาจได้ Equal Error Rate (EER) อยู่ในระดับหลักหน่วยถึงหลักเลขหลักเดียว ขึ้นกับสภาวะแวดล้อมและความยาวของคำพูด
Liveness Detection: รูปแบบและการใช้งาน
Liveness Detection ใน Voice‑KYC 2.0 ประกอบด้วยหลายเทคนิคที่เสริมกันเพื่อลดความเสี่ยงจากการเล่นซ้ำหรือสังเคราะห์เสียง:
- Challenge‑Response: ระบบสุ่มคำหรือประโยคให้ผู้ใช้พูดตามแบบเรียลไทม์ (เช่น ระบุตัวเลข/วลีสุ่ม) เพื่อลดความเสี่ยงจากการเล่นซ้ำ (replay) และสคริปท์ที่ถูกเตรียมไว้ล่วงหน้า โดยวัดความสอดคล้องของเวลาตอบสนองและ prosody
- Acoustic Artefact Analysis: ตรวจจับลายเซ็นของการเล่นซ้ำหรือสังเคราะห์ เช่น เศษข้อมูลโคเดก (compression signatures), harmonic inconsistency, phase distortion และการประพฤติที่ผิดปกติในสเปกตรัม ซึ่งเทคนิคนี้มักใช้ร่วมกับโมเดล ML ขนาดเล็กที่ฝึกบนตัวอย่าง replay/real
- Mic‑Array Cues: ใช้ชุดไมโครโฟน (ถ้ามี) วิเคราะห์ทิศทางการมาถึงของคลื่นเสียง (DOA, TDoA) และความแตกต่างของสัญญาณข้ามช่องสัญญาณ เพื่อแยกระหว่างแหล่งเสียงที่อยู่ใกล้ปากผู้พูดจริงกับการเล่นซ้ำจากลำโพงภายนอก
การทำงานร่วมกันแบบเรียลไทม์และการส่งข้อมูลข้ามระบบ
ในเชิงปฏิบัติสถาปัตยกรรมจะแบ่งการประมวลผลเป็นสองชั้นหลัก: on‑device front‑end สำหรับงานที่ต้องการความหน่วงต่ำ เช่น การสกัดฟีเจอร์, การตรวจ liveness เบื้องต้น (challenge timing, simple artefact checks), และการสร้าง speaker‑embedding แบบ distilled; และ cloud/edge back‑end สำหรับงานที่ต้องการพลังประมวลผลมาก เช่น Anti‑Deepfake LLM, การคำนวณคะแนน PLDA ขั้นสูง และการเก็บประวัติ enrollment ระยะยาว โฟลว์ตัวอย่างคือ:
- 1) อุปกรณ์ผู้ใช้จับเสียง ทำ pre‑processing (VAD, normalisation) และสกัดฟีเจอร์/embedding แบบ local
- 2) ระบบ on‑device ดำเนินการ liveness checks เชิงเร่งด่วน (challenge timing, basic artefact detection) เพื่อให้ feedback ทันที
- 3) หากผ่านเงื่อนไขเบื้องต้น จะส่ง embedding และเมตาดาต้า (เวลาตอบสนอง, DOA, quality metrics) ไปยัง cloud แทนการส่ง raw audio เพื่อรักษาความเป็นส่วนตัวและลดแบนด์วิดท์
- 4) ใน cloud Anti‑Deepfake LLM จะทำ inference แบบ multi‑modal โดยนำ spectrogram (หรือ compressed/hashed representation), transcript embedding และ speaker‑embedding มารวมกันเพื่อตัดสินใจสุดท้ายและคืนผลตอบกลับ
แนวทางลด latency และเพิ่มความทนต่อการโจมตี
เพื่อตอบโจทย์การใช้งานเชิงธุรกิจต้องมีความหน่วงต่ำ (เป้าหมายปฏิบัติการมักอยู่ที่ sub‑second — เช่น 300–500 ms สำหรับ end‑to‑end ในกรณีเรียลไทม์) วิธีปฏิบัติที่ใช้ได้แก่:
- การประมวลผลล่วงหน้าบนอุปกรณ์: สกัด embedding และรัน liveness แบบเบื้องต้นบนอุปกรณ์ (ลดการส่งข้อมูลและรอผลจากคลาวด์)
- โมเดลขนาดเล็กและ distillation: ใช้เวอร์ชัน distilled ของ ECAPA‑TDNN หรือโมเดล LLM ขนาดเล็กสำหรับการเดาทันที และส่งงานหนักให้คลาวด์แบบอะซิงโครนัส
- การบีบอัดข้อมูลและส่งเฉพาะ embedding/metadata: ลดแบนด์วิดท์และเวลา I/O โดยไม่ส่ง raw audio เสมอไป (เพิ่มความเป็นส่วนตัวด้วยการเข้ารหัส)
- การปรับแต่งทรัพยากร: ใช้ quantization, pruning, และ NPU/TPU acceleration บนอุปกรณ์เพื่อย่อเวลา inference
- การออกแบบ pipeline แบบพาราไลซ์และ early‑exit: ให้ผลตรวจเบื้องต้นทันที ถ้าผลชี้ชัดเจนแล้วจึงไม่ต้องรอการประมวลผลลึกเพิ่มเติม
เมื่อรวมองค์ประกอบทั้งหมด Voice‑KYC 2.0 จึงกลายเป็นระบบที่ใช้ระดับการตรวจสอบหลายชั้น (multi‑layered defence): speaker‑embedding ยืนยันสถานะตัวตนเชิงสถิติ, liveness ตรวจความสดของสัญญาณ, และ Anti‑Deepfake LLM ตรวจจับความบกพร่องเชิงเนื้อหาและสเปกตรัมที่อาจบ่งชี้การปลอมแปลง การผสานข้อมูลจากทั้งสามโมดูลพร้อมกับการออกแบบสถาปัตยกรรมบนอุปกรณ์และบนคลาวด์อย่างรอบคอบ จะช่วยให้ธนาคารสามารถรักษาสมดุลระหว่างความแม่นยำ ความเป็นส่วนตัว และความไวตอบสนองสำหรับการทำธุรกรรมที่ปลอดภัย
รายละเอียดการทดสอบ (pilot) ของธนาคาร: ขอบเขตและเมทริกซ์ที่ใช้วัดผล
รายละเอียดการทดสอบ (pilot) ของธนาคาร: ขอบเขตและเมทริกซ์ที่ใช้วัดผล
ธนาคารดำเนินการทดสอบระบบ Voice‑KYC 2.0 ในรูปแบบผสมระหว่าง internal pilot และ closed beta กับกลุ่มลูกค้าที่คัดเลือกไว้ โดยแบ่งเป็นสองเฟสหลักเพื่อควบคุมความเสี่ยงและเก็บข้อมูลเชิงลึก: เฟสแรกเป็นการทดสอบภายในธนาคารกับพนักงาน 1,000 คน (เพื่อป้องกันการรั่วไหลของเทคโนโลยีและทดสอบกระบวนการภายใน) และเฟสที่สองเป็นการทดสอบแบบปิดกับลูกค้าเชิงพาณิชย์ 4,000 คน รวมตัวอย่างเสียงทั้งหมดประมาณ 5,000 ผู้ใช้ ซึ่งประกอบด้วยการลงทะเบียนเสียง (enrollment) และการยืนยันตัวตนซ้ำ (authentication) ในสถานการณ์ใช้งานจริงหลายรูปแบบ
ตัวอย่างการโจมตีที่ใช้ในการทดสอบมีทั้งหมดประมาณ 1,200 กรณีโจมตี แยกเป็นกลุ่มย่อยเพื่อประเมินความแข็งแกร่งต่อเทคนิคการปลอมเสียงที่หลากหลาย ได้แก่:
- Voice cloning / speaker cloning — เสียงที่ถูกโคลนจากตัวอย่างจริงของเหยื่อ โดยใช้โมเดลเชิงลึกเช่น Tacotron2+WaveGlow, FastSpeech + neural vocoders, และบริการเชิงพาณิชย์ (ตัวอย่าง: ElevenLabs, Google TTS ในโหมด clone)
- Speech synthesis / TTS — เสียงสังเคราะห์จากโมเดล TTS ทั่วไปทั้งเชิงพาณิชย์และโอเพนซอร์ส เพื่อวัดผลกับระบบตรวจจับ deepfake
- Voice conversion (VC) — การแปลงเสียงจากผู้พูดหนึ่งไปเป็นอีกผู้พูดหนึ่งโดยใช้ AutoVC, StarGAN-VC และเทคนิค GAN-based
- Replay attacks — การเล่นซ้ำไฟล์เสียงที่บันทึกไว้ผ่านอุปกรณ์จริง (ลำโพง/ไมโครโฟน) ในสภาพแวดล้อมต่าง ๆ เพื่อทดสอบความเปราะบางของ liveness detection
เงื่อนไขการทดสอบถูกออกแบบให้ครอบคลุมสถานการณ์การใช้งานจริงและการโจมตีที่หลากหลาย โดยกำหนดพารามิเตอร์สำคัญดังนี้:
- สภาพแวดล้อมเสียง (Acoustic conditions) — ทดสอบในหลายระดับ SNR: >20 dB (เงียบ/สำนักงาน), 10–20 dB (สภาพแวดล้อมทั่วไป), 0–10 dB (เสียงรบกวนสูง เช่น ร้านกาแฟหรือการจราจร), และ <0 dB (สภาพแวดล้อมรุนแรง เช่น งานคอนเสิร์ต) เพื่อวัดความทนทานของระบบต่อสัญญาณรบกวน
- อุปกรณ์และช่องทางสื่อสาร — ครอบคลุมมือถือหลากหลายรุ่น (low-end Android, mid-range, flagship iOS), feature phones ที่รองรับเสียงโทรศัพท์, เครือข่าย 3G/4G/VoLTE, VoIP (Opus) และ codecs ที่ใช้จริง เช่น AMR-NB, AMR-WB, Opus เพื่อจำลองการบีบอัดและการเสื่อมคุณภาพของเสียง
- ผู้ใช้จริง vs การโจมตีจำลอง — เก็บข้อมูลจากผู้ใช้จริงทั้งการสมัครและการยืนยันซ้ำ (ประมาณ 3,800–4,000 session) และฝังกรณีโจมตีจำลอง 1,200 กรณีในชุดทดสอบเพื่อประเมินระบบในสภาวะการแข่งขัน (adversarial conditions)
- ความแตกต่างของเนื้อหาเสียง — ทดสอบทั้งแบบวลีคงที่ (fixed passphrase), วลีสุ่ม (random challenge-response) และการสนทนาแบบเปิดเพื่อวัดความยืดหยุ่นของโมดูล speaker‑embedding และ liveness
เมทริกซ์ที่ใช้วัดผลใน pilot ถูกออกแบบทั้งเชิงความถูกต้องและเชิงปฏิบัติการ ได้แก่:
- Authentication metrics — False Acceptance Rate (FAR), False Rejection Rate (FRR), Equal Error Rate (EER), True Positive Rate (TPR) และ Area Under ROC Curve (AUC) โดยตั้งเกณฑ์เป้าหมายเช่น FAR < 0.1% และ FRR < 2% สำหรับการยอมรับเชิงธุรกิจ
- Spoofing / Anti‑deepfake metrics — Spoof Detection Rate (SDR) แยกตามประเภทการโจมตี (TTS, VC, replay) โดยเป้าหมายคือ SDR > 99% สำหรับ replay attacks และ >95% สำหรับ TTS/VC ขั้นสูง พร้อมวัด False Alarm ของโมดูลตรวจจับการปลอมเสียง
- Liveness & speaker‑embedding robustness — อัตราการตรวจจับ liveness สำเร็จ (Liveness Success Rate), การเสถียรของ embedding ภายใต้สัญญาณรบกวนต่าง ๆ (embedding drift), และการลดประสิทธิภาพของการจับคู่ผู้พูดตามระดับ SNR
- ความหน่วงและประสิทธิภาพเชิงปฏิบัติการ — Latency จากรับเสียงจนถึงผลยืนยัน (เป้าหมาย <500 ms ในเส้นทางหลัก), throughput (transaction/s), การใช้ทรัพยากรเซิร์ฟเวอร์ (CPU, memory), และความสามารถรองรับโหลดพร้อมกัน (concurrent sessions)
- การทดสอบความสามารถต้านทานต่อโมเดลใหม่ — ใช้ชุดทดสอบ adversarial hold‑out ซึ่งประกอบด้วยเสียงจากเทคโนโลยี TTS/VC ใหม่ ๆ ที่ไม่ได้ใช้ในการฝึกระบบเพื่อตรวจสอบการ generalize ของโมเดล anti‑deepfake (วัดเป็น degradation ของ SDR และ EER)
นอกจากนี้ การวิเคราะห์ผลยังรวมถึงการแบ่งกลุ่ม (segmentation) ผลลัพธ์ตามอุปกรณ์, codec, และระดับ SNR เพื่อระบุจุดอ่อนเชิงปฏิบัติการ ตัวอย่างเช่น หาก FRR เพิ่มขึ้นเมื่อ SNR <10 dB หรือ SDR ลดลงกับไฟล์ที่ผ่านการบีบอัด AMR-NB จะนำไปสู่การปรับแต่งโมดูล denoising, การปรับ threshold ของ speaker‑embedding และการเสริมข้อมูลโจมตีใหม่ในชุดฝึก (adversarial training) เพื่อเพิ่มความทนทานก่อนขยายสู่การใช้งานจริง (production rollout)
ผลการทดสอบเชิงสถิติ: ความแม่นยำ ความเร็ว และอัตราความผิดพลาด
ผลการทดสอบเชิงสถิติ: ความแม่นยำ ความเร็ว และอัตราความผิดพลาด
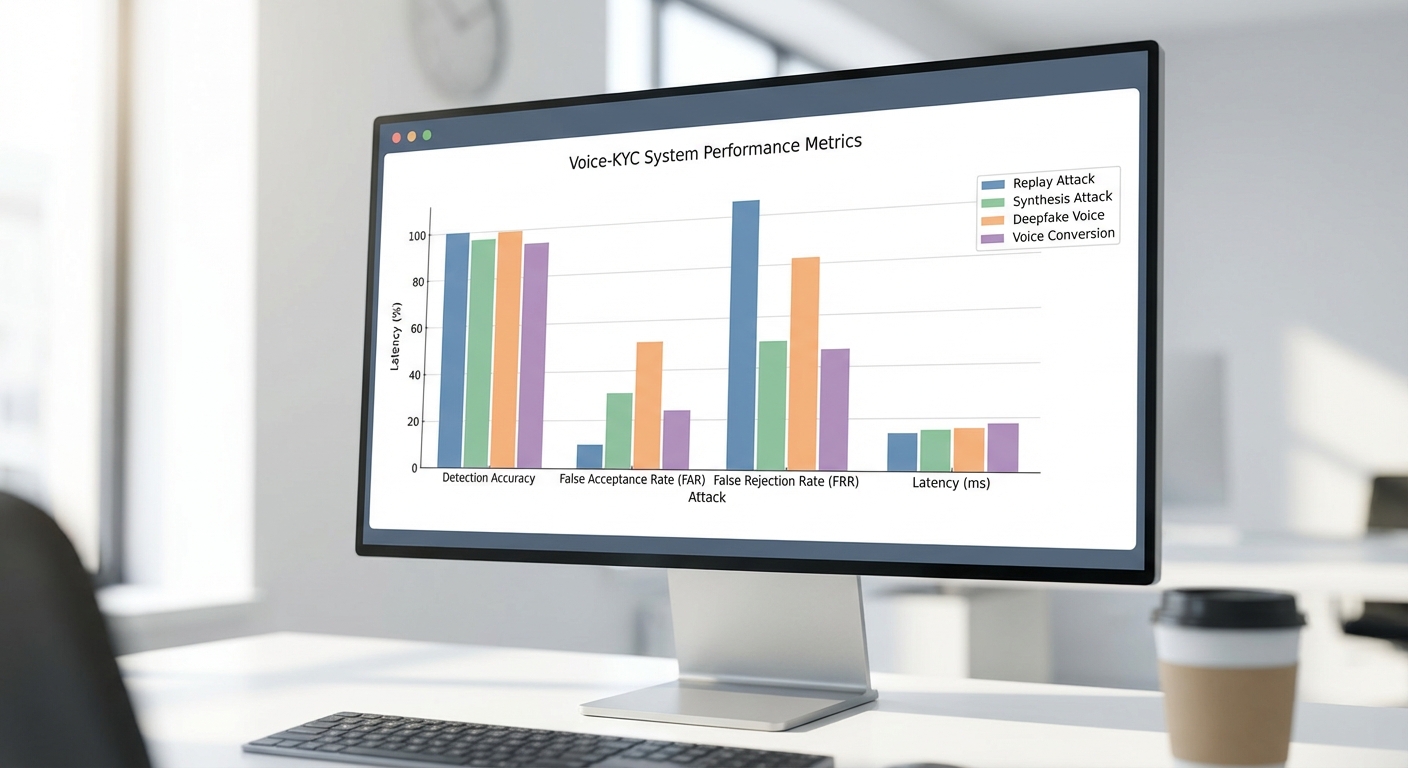
การทดสอบเชิงสถิติเพื่อประเมินระบบ Voice‑KYC 2.0 ที่ผสาน Anti‑Deepfake LLM, speaker‑embedding และ liveness detection ดำเนินการบนชุดข้อมูลเชิงทดลองขนาดประมาณ 10,000 เซสชัน (สมมติฐานเชิงทดลองที่จำลองสภาพแวดล้อมจริง ได้แก่ ผู้ใช้จากภูมิภาคต่าง ๆ อุปกรณ์มือถือหลายรุ่น สภาพเสียงพื้นหลังที่มี SNR ตั้งแต่ 0–20 dB และเครือข่าย 4G/5G) ผลลัพธ์สำคัญโดยสรุปมีดังนี้:
- Detection accuracy (โดยรวม): ≈ 98.7% — สะท้อนสัดส่วนของการยืนยันตัวตนที่ระบบตรวจจับถูกต้องทั้งการยอมรับผู้ถูกต้องและปฏิเสธการโจมตี
- False Acceptance Rate (FAR): ≈ 0.3% — อัตราที่ระบบอนุญาตให้ผู้โจมตีผ่านการยืนยัน
- False Rejection Rate (FRR): ≈ 1.2% — อัตราที่ระบบปฏิเสธผู้ใช้ที่แท้จริง
- Latency เฉลี่ย (real‑time verification): ≈ 200–400 ms — เวลาตอบกลับเฉลี่ยที่ใช้สำหรับการวิเคราะห์เสียงแบบเรียลไทม์จนได้ผลการตัดสิน
เมื่อแยกผลตามประเภทการโจมตี พบความแตกต่างที่สำคัญระหว่าง deepfake synthesis และ replay attack ดังนี้: สำหรับการโจมตีด้วยการสังเคราะห์เสียง (deepfake synthesis) ระบบมี detection accuracy ≈ 97.2% กับ FAR ≈ 0.5% และ FRR ≈ 1.6% ส่วนการโจมตีแบบอัด-เล่นซ้ำ (replay attack) ทำได้ยากกว่าสำหรับผู้โจมตีโดยระบบสามารถตรวจจับได้แม่นยำกว่า: detection accuracy ≈ 99.4%, FAR ≈ 0.1%, FRR ≈ 0.8%. ความต่างนี้สะท้อนว่าโมดูล Anti‑Deepfake LLM จำเป็นต้องจัดการลักษณะการบิดเบือนเชิงสังเคราะห์ที่ซับซ้อนกว่า ขณะที่ liveness + speaker‑embedding ช่วยหยุดการโจมตีแบบ replay ได้มีประสิทธิภาพสูง
การเปรียบเทียบกับระบบ KYC เสียงแบบเดิมแสดงให้เห็นความก้าวหน้าเชิงปฏิบัติการ: ระบบแบบ text‑dependent รุ่นเดิม (ที่ใช้ประโยคคงที่หรือ prompt สั้น ๆ) มักรายงาน detection accuracy ประมาณ 94–96% และ FAR ระหว่าง 0.7–1.5% เนื่องจากใช้ข้อมูลข้อความจำกัดและอาศัย pattern matching มาก ในขณะที่ระบบ text‑independent ดั้งเดิมแม้จะยืดหยุ่นต่อการพูดแต่พบ FRR สูงกว่า (1.5–3%) เมื่อเจอสภาพเสียงรบกวน ในแง่นี้ Voice‑KYC 2.0 ที่รวมทั้ง text‑independent embedding และ LLM‑based anti‑deepfake ทำให้ได้ค่า accuracy สูงขึ้น (≈98.7%) พร้อม FAR/FRR ต่ำลงอย่างมีนัยสำคัญ ขณะเดียวกันยังรักษาความคล่องตัวของผู้ใช้เมื่อเทียบกับ text‑dependent ที่ต้องให้ผู้ใช้พูดประโยคเฉพาะ
การตีความตัวเลขต่อประสบการณ์ผู้ใช้และความปลอดภัยมีความสำคัญ: FAR ≈ 0.3% บ่งชี้ความเสี่ยงการปลอมแปลงที่ต่ำมาก ซึ่งหมายความว่าโอกาสที่แฮกเกอร์จะสามารถหลบผ่านระบบเพื่อเข้าถึงบัญชีมีน้อย ในเชิงความปลอดภัยนี้เป็นข้อได้เปรียบสำหรับสถาบันการเงิน อย่างไรก็ตาม FRR ≈ 1.2% แปลว่าประมาณหนึ่งถึงสองผู้ใช้ในร้อยอาจถูกปฏิเสธชั่วคราว ซึ่งมีผลต่อประสบการณ์ผู้ใช้ (UX) โดยตรง หาก FRR สูงเกินไปจะเพิ่มต้นทุนการบริการลูกค้าและอาจทำให้ผู้ใช้เกิดความไม่พอใจ
ดังนั้นมี trade‑off ที่ชัดเจนระหว่างความแม่นยำและความสะดวกสบายของผู้ใช้: การตั้ง threshold ให้เข้มขึ้นจะลด FAR (เพิ่มความปลอดภัย) แต่แลกกับ FRR ที่เพิ่มขึ้น (ลดความสะดวก) ในทางกลับกันการผ่อน threshold จะทำให้ UX ดีขึ้นแต่ความเสี่ยงการยอมรับผู้โจมตีสูงขึ้น Voice‑KYC 2.0 จึงใช้แนวทางผสมหลายชั้น เช่น adaptive threshold ตามบริบท (อุปกรณ์ ภูมิภาค ประวัติความเสี่ยง) และ fallback flow สำหรับผู้ที่ถูกปฏิเสธ (เช่น การขอพูดประโยคเสริม หรือการยืนยันด้วยเอกสาร) เพื่อให้ได้สมดุลระหว่างความปลอดภัยและความสะดวก
สรุป: ผลทดสอบเชิงตัวเลขตัวอย่างบ่งชี้ว่า Voice‑KYC 2.0 ให้ความแม่นยำสูง (≈98.7%) และความหน่วงตอบสนองในระดับที่ยอมรับได้ (เฉลี่ย 200–400 ms) พร้อมลดความเสี่ยงการยอมรับการโจมตีได้อย่างมีนัยสำคัญ โดยยังต้องออกแบบนโยบาย threshold และกระบวนการ fallback ที่ช่วยลดผลกระทบต่อผู้ใช้จริงเพื่อลด FRR และรักษาประสบการณ์การใช้งานในระดับองค์กรธนาคาร
ความเป็นส่วนตัว กฎหมาย และการจัดการข้อมูลเสียง
เนื้อหาส่วน ความเป็นส่วนตัว กฎหมาย และการจัดการข้อมูลเสียง ยังไม่สามารถสร้างได้
ประสบการณ์ผู้ใช้ การผสานระบบกับบริการธนาคาร และแผนการนำไปใช้จริง
ประสบการณ์ผู้ใช้ (UX) ในการลงทะเบียนและการยืนยันตัวตนแบบเรียลไทม์
กระบวนการ UX ถูกออกแบบให้เรียบง่ายและชัดเจน เพื่อให้ลูกค้าสามารถลงทะเบียนเสียง (enrollment) และยืนยันตัวตน (verification) ได้ภายในไม่กี่ขั้นตอนโดยไม่เกิดความซับซ้อน ตัวอย่าง flow พื้นฐานประกอบด้วย enrollment → verification → challenge/response → transaction approval โดยขั้นตอน enrollment แนะนำให้ลูกค้าบันทึกเสียงตัวอย่าง 3–5 ประโยคที่กำหนด (รวมเวลาเสียงสุทธิ 20–40 วินาที) เพื่อสร้าง speaker‑embedding ที่มีความชัดเจนและทนต่อสภาพแวดล้อม
ตัวอย่าง challenge phrases ที่ใช้ในการทดสอบแบบสุ่ม เช่น “โปรดพูดว่า: ฉันยืนยันรายการวันนี้”, “อ่านตัวเลขนี้: 4 9 2 1”, หรือประโยคที่ธนาคารกำหนดเฉพาะกิจ (dynamic nonce) เพื่อป้องกันการเล่นซ้ำ (replay attacks) และ deepfake: “เช็คยอดบัญชีและยืนยันด้วยเสียงตอนนี้” การใช้ประโยคที่ไม่ซ้ำและมีความยาวระหว่าง 3–8 วินาที ช่วยเพิ่มความแม่นยำของ liveness detection และลดความเสี่ยงการปลอมเสียง
ระหว่างการตรวจสอบแบบเรียลไทม์ ระบบจะให้ฟีดแบ็กทันทีผ่าน UI/UX ของช่องทางนั้นๆ (mobile app, web, IVR) เช่น ข้อความแนะนำ “กรุณาพูดประโยคที่แสดง”, แถบสถานะการบันทึกเสียง, ไอคอน waveform แสดงคุณภาพเสียง และผลลัพธ์การยืนยันเช่น “ยืนยันตัวตนสำเร็จ” หรือ “ขอให้บันทึกใหม่อีกครั้ง ภายใน 30 วินาที” ระบบยังกำหนดค่า latency เป้าหมายเพื่อประสบการณ์ที่ราบรื่น โดยทั่วไปตั้งเป้าให้ผลการตัดสินใจภายใน 2–4 วินาที หลังสิ้นสุดการบันทึกเสียง ในกรณีที่ระบบแจ้งล้มเหลว จะมี fallback flow เช่น ส่ง OTP, เชื่อมต่อเจ้าหน้าที่ (human escalation) หรือขอให้ผู้ใช้ยืนยันตัวตนที่สาขา
การผสานระบบกับช่องทางธนาคารและโครงสร้างพื้นฐาน
การนำ Voice‑KYC 2.0 เข้าสู่ระบบธนาคารต้องออกแบบ integration points ให้รองรับทั้งการสื่อสารแบบซิงโครนัสและอะซิงโครนัส โดยส่วนสำคัญประกอบด้วย:
- API กับ Core Banking: การขออนุมัติธุรกรรมหลังยืนยันตัวตนต้องมี API ที่ส่ง token ผลการยืนยัน (verification token) และ risk score กลับไปยังระบบแกนหลักเพื่ออนุมัติคำสั่งถอน โอน หรือเปิดบัญชี
- Fraud Detection Systems: ผลจาก Anti‑Deepfake LLM, speaker‑embedding และ liveness score จะถูกส่งไปยังโมดูล fraud engine เพื่อปรับค่า risk score แบบเรียลไทม์ (real‑time risk scoring) หากค่าความเสี่ยงสูง ระบบจะเรียกใช้กฎทางธุรกิจเช่น require additional OTP หรือ escalate
- CRM และ Agent Console: ข้อมูลการยืนยัน (timestamp, confidence score, transcription snippet) จะถูกบันทึกใน CRM ผ่าน webhook เพื่อให้เจ้าหน้าที่เห็นบริบทการติดต่อย้อนหลังและตอบลูกค้าได้อย่างรวดเร็ว
- Call Center / IVR Integration: ระบบ IVR สามารถจับเสียงผู้โทร ส่งไปยัง Voice‑KYC engine ผ่าน API และรับผลการตรวจสอบกลับแบบทันทีเพื่อให้ agent เห็นสถานะบนหน้าจอ (screen pop) ช่วยลดเวลาและความซ้ำซ้อนในการยืนยันตัวตน
การผสานงานยังรวมถึงการออกแบบ security layer เช่น tokenization ของ speaker template, การเข้ารหัสขณะส่ง (TLS 1.2/1.3), การจัดการสิทธิ์ผ่าน OAuth2 และการ audit log สำหรับการตรวจสอบย้อนหลัง การเชื่อมต่อควรออกแบบให้มี idempotency, retry policy และ circuit breaker เพื่อรักษาเสถียรภาพระหว่างระบบที่แตกต่างกัน
แผนการนำไปใช้จริง (phased deployment) และการฝึกอบรมพนักงาน
แผนการปรับใช้แบบเป็นขั้นเป็นตอน (phased deployment) ช่วยลดความเสี่ยงและเก็บข้อมูลเชิงประจักษ์ก่อนขยายสู่ผู้ใช้ทั้งหมด แผนตัวอย่างประกอบด้วย 3 ระยะหลัก:
- Pilot (3–6 เดือน): ทดสอบกับกลุ่มผู้ใช้จำกัด (เช่น 5,000–20,000 คน) ในพื้นที่หรือผลิตภัณฑ์เฉพาะ เพื่อตรวจสอบความแม่นยำของ LLM ในการตรวจจับ deepfake, latency, และผลกระทบต่ออัตราการปฏิเสธ (FRR) และการยอมรับปลอม (FAR). KPI ตัวอย่าง: FAR <0.1%, FRR <2%, เวลาเฉลี่ยต่อการยืนยัน <5 วินาที
- Limited Market Roll‑out (6–12 เดือน): ขยายสู่ลูกค้าในหลายช่องทาง (mobile banking, call center, สาขา) และพื้นที่ทางภูมิศาสตร์ที่หลากหลาย เพื่อตรวจสอบการทำงานร่วมกับระบบ fraud detection และ core banking ในสถานการณ์จริง
- Full Expansion (12–24 เดือน): ขยายสู่ผู้ใช้ทั้งหมดพร้อมปรับแต่งโมเดลตาม feedback จากการใช้งานจริง และวางแผนการบำรุงรักษาระยะยาว เช่นการ retraining ของโมเดลด้วยข้อมูลที่ได้รับอนุญาต
สำหรับการฝึกอบรมพนักงาน โปรแกรม training ควรรวมถึงการอบรมเชิงเทคนิคสำหรับทีม IT (การจัดการ API, monitoring, incident response) และการอบรมเชิงปฏิบัติการสำหรับพนักงานหน้าบ้าน (call center, สาขา) โดยหัวข้อครอบคลุมวิธีอ่านผล confidence score, การตอบสนองเมื่อระบบแจ้งความเสี่ยงสูง, การใช้ agent console, และการปฏิบัติตามนโยบายความเป็นส่วนตัว การฝึกอบรมควรมีทั้ง e‑learning, workshop พร้อม simulation และ role‑play กับสถานการณ์ปลอมเสียงหลายรูปแบบ
สุดท้าย ธนาคารควรกำหนดแผนสำรองและเกณฑ์ยกเลิก (rollback) หาก KPI สำคัญล้มเหลว รวมถึงช่องทางสื่อสารกับลูกค้า (notification, consent, opt‑out) เพื่อให้การนำ Voice‑KYC 2.0 เป็นไปอย่างราบรื่น ปลอดภัย และได้รับความเชื่อมั่นจากผู้ใช้
ผลกระทบต่ออุตสาหกรรม ข้อจำกัด และทิศทางอนาคต
ผลกระทบเชิงธุรกิจต่ออุตสาหกรรมการเงิน
การนำระบบ Voice‑KYC 2.0 ที่ผสาน Anti‑Deepfake LLM, speaker‑embedding และ liveness detection มาใช้จะเปลี่ยนรูปแบบการยืนยันตัวตนทางโทรศัพท์และช่องทางเสียงของธนาคารอย่างมีนัยสำคัญ ทั้งในด้านการป้องกันการฉ้อโกง การลดต้นทุนการดำเนินงาน และการยกระดับประสบการณ์ลูกค้า ตัวอย่างเช่น ธนาคารที่ลงทุนในระบบยืนยันตัวตนอัตโนมัติมักรายงานการลดความเสี่ยงจากการฉ้อโกงที่เกี่ยวข้องกับการปลอมแปลงเสียงได้อย่างชัดเจน โดยผู้เชี่ยวชาญประเมินว่าเทคโนโลยีดังกล่าวสามารถลดเหตุการณ์ฉ้อโกงที่พึ่งพาเสียงลงได้เป็นสัดส่วนตั้งแต่ประมาณ 30–60% ขึ้นอยู่กับกรณีการใช้งานและความครอบคลุมของข้อมูลเทรน
ในเชิงต้นทุน ระบบ Voice‑KYC ช่วยลดภาระการทำงานของศูนย์บริการลูกค้า (call center) ทั้งการลดความถี่ในการส่งต่อเคสไปยังเจ้าหน้าที่และลดเวลาเฉลี่ยในการจัดการ (AHT) บางสถาบันประเมินว่าการแทนที่กระบวนการยืนยันด้วยมนุษย์บางส่วนด้วยระบบอัตโนมัติสามารถลดต้นทุนการให้บริการได้ประมาณ 20–40% ในระยะยาว ขณะที่ยังช่วยเพิ่มความพึงพอใจของผู้ใช้ด้วยการลดเวลารอและกระบวนการยืนยันที่ง่ายขึ้น
ข้อจำกัดและความเสี่ยงเชิงเทคนิค รวมถึงข้อกฎหมายและจริยธรรม
แม้ Voice‑KYC 2.0 จะมีศักยภาพสูง แต่มีข้อจำกัดทางเทคนิคและข้อกังวลเชิงนโยบายที่ต้องพิจารณาอย่างเข้มข้น หนึ่งในความท้าทายหลักคือ การเผชิญกับเทคนิคการสร้าง deepfake ที่พัฒนาอย่างรวดเร็ว — โมเดลสร้างเสียงคุณภาพสูงอาจเลียนเสียงเป้าหมายได้ใกล้เคียงจนล่อระบบตรวจจับได้ยาก โดยเฉพาะเมื่อ deepfake ถูกสร้างขึ้นด้วยข้อมูลเสียงจริงที่หลากหลายและมีการปรับแต่งเชิง adversarial
อีกประเด็นสำคัญคือความทนทานต่อความหลากหลายของภาษาและสำเนียงท้องถิ่น ระบบ speaker‑embedding มักมีความแม่นยำสูงสำหรับกลุ่มที่ถูกแทนด้วยข้อมูลเทรน แต่จะเกิด bias / coverage gap เมื่อเจอกับสำเนียงชนบท ภาษาแม่ที่ไม่ได้ครอบคลุม หรือกลุ่มประชากรที่มีข้อมูลน้อย ส่งผลให้ประสิทธิภาพลดลงและอาจสร้างความเหลื่อมล้ำในการเข้าถึงบริการ นอกจากนี้ ปัญหาเสียงรบกวนจากสภาพแวดล้อมจริง (background noise), คุณภาพเครือข่ายโทรศัพท์ และอุปกรณ์ผู้ใช้ (mic quality) ยังส่งผลกระทบต่ออัตราการตรวจจับ liveness และความแม่นยำของการยืนยันตัวตน
ด้านกฎหมายและความเป็นส่วนตัว ระบบ Voice‑KYC ต้องสอดคล้องกับกฎ PDPA, GDPR และข้อกำหนดการเก็บรักษาข้อมูลเสียงที่อาจถูกมองว่าเป็นข้อมูลชีวภาพ (biometric data) ซึ่งมีข้อจำกัดด้านการเก็บ การประมวลผล และการขอความยินยอม นอกจากนี้ยังมีความเสี่ยงเชิงจริยธรรม เช่นการใช้โมเดล LLM ในการวิเคราะห์เนื้อหาเสียงอาจก่อให้เกิดการละเมิดความเป็นส่วนตัวหากไม่ได้ออกแบบการกำกับดูแลและการตรวจสอบที่เหมาะสม
ทิศทางการพัฒนาในอนาคตและแนวทางปฏิบัติที่แนะนำ
เพื่อรับมือกับข้อจำกัดข้างต้น ธนาคารและผู้พัฒนาระบบควรเดินหน้าในหลายมิติควบคู่กัน ได้แก่ การเรียนรู้และอัปเดตโมเดลอย่างต่อเนื่อง (continuous learning) เพื่อรับมือกับวิวัฒนาการของเทคนิค deepfake และการเปลี่ยนแปลงของพฤติกรรมผู้ใช้ การนำแนวทาง federated learning มาใช้ช่วยให้สามารถปรับปรุงโมเดลจากข้อมูลจริงหลายแหล่งโดยไม่ต้องย้ายข้อมูลเสียงไปยังศูนย์กลาง ช่วยลดความเสี่ยงด้านข้อมูลส่วนบุคคล
นอกจากนี้การผสาน multimodal authentication (เช่นการรวมข้อมูลใบหน้า, เสียง, พฤติกรรมการใช้งาน และปัจจัยทางชีวภาพอื่นๆ) จะเพิ่มความทนทานต่อการโจมตีแบบ deepfake เพียงช่องทางเดียว การออกแบบระบบควรรวมการทดสอบเชิงรุก (red‑teaming, adversarial testing) และการตรวจสอบแบบเรียลไทม์เพื่อระบุความผิดปกติ รวมทั้งการวาง KPI ด้านความปลอดภัย เช่น false accept rate (FAR), false reject rate (FRR) และเวลาเฉลี่ยในการตรวจจับเหตุการณ์ฉ้อโกง
- กลยุทธ์การพัฒนาโมเดล: ใช้ federated learning และ privacy‑preserving techniques (เช่น differential privacy) เพื่อปรับปรุงความแม่นยำโดยคงความเป็นส่วนตัว
- การจัดการข้อมูล: ขยายความหลากหลายของชุดข้อมูลเพื่อครอบคลุมสำเนียงและกลุ่มประชากรที่หลากหลาย พร้อมการทำ data augmentation เพื่อลด bias
- การรวมหลายมิติ: นำ multimodal KYC มาใช้ ลดความเสี่ยงจากการพึ่งพาเสียงเพียงช่องทางเดียว และปรับสมดุลระหว่างความสะดวกและความปลอดภัย
- การกำกับดูแลและปฏิบัติตามกฎระเบียบ: กำหนดนโยบายการเก็บและใช้งานข้อมูลเสียงที่ชัดเจน ขอความยินยอมอย่างโปร่งใส และเตรียมกระบวนการตรวจสอบเพื่อปฏิบัติตาม PDPA/GDPR
- การดำเนินงานเชิงปฏิบัติ: ตั้งทีมตอบโต้เหตุการณ์ฉ้อโกง, ทำ monitoring แบบเรียลไทม์, และอัปเดต playbook ด้าน incident response อย่างสม่ำเสมอ
สรุปคือ Voice‑KYC 2.0 เป็นโอกาสทางธุรกิจที่ชัดเจนในการลดการฉ้อโกงและลดต้นทุนการให้บริการ แต่การนำไปใช้ในวงกว้างต้องคำนึงถึงความทนทานต่อการโจมตีแบบ deepfake, การลด bias ของชุดข้อมูล, และการปฏิบัติตามกฎระเบียบที่เข้มงวด การลงทุนในระบบเรียนรู้แบบต่อเนื่อง การผสานหลายมิติ และการกำกับดูแลข้อมูลเชิงรุกจะเป็นหัวใจสำคัญของการบรรลุผลประโยชน์เชิงธุรกิจได้อย่างยั่งยืน
บทสรุป
Voice‑KYC 2.0 ที่ผสาน Anti‑Deepfake LLM ร่วมกับ speaker‑embedding และ liveness detection เป็นก้าวสำคัญในการยกระดับความปลอดภัยของการยืนยันตัวตนด้วยเสียง โดยการนำความสามารถตรวจจับการปลอมเสียงแบบเรียลไทม์มารวมกับการระบุลักษณะเสียงเฉพาะตัว (speaker‑embedding) และเทคนิคตรวจสอบความมีชีวิต (liveness) จะช่วยลดความเสี่ยงจากการโจมตีด้วยเสียงสังเคราะห์ ตัวอย่างเช่น ระบบที่ดีขึ้นสามารถลดอัตราการยอมรับเสียงปลอม (false accept) ได้ ขณะเดียวกันก็ต้องเผชิญกับ trade‑off ระหว่างความแม่นยำ (เช่น FAR/FRR) และประสบการณ์ผู้ใช้ (เช่น ความหน่วงในการยืนยันหรืออัตราการยกเลิกของผู้ใช้) ทีมงานต้องกำหนดตัวชี้วัดเชิงประสิทธิภาพ เช่น อัตราการปฏิเสธที่ผิดพลาด (FRR), อัตราการยอมรับที่ผิดพลาด (FAR), ความหน่วงเฉลี่ย และอัตราการคงอยู่ของผู้ใช้ เพื่อประเมินผลกระทบต่อ UX นอกจากนี้ การจัดการข้อมูลเสียงที่เป็นข้อมูลชีวภาพจำเป็นต้องมีมาตรการคุ้มครองข้อมูลที่เข้มงวด เช่น การเข้ารหัสข้อมูลขณะส่งและขณะเก็บ การลดข้อมูล (data minimization) นโยบายการเก็บข้อมูลและการขอความยินยอมชัดเจน ตามกรอบกฎหมายคุ้มครองข้อมูลส่วนบุคคล (เช่น PDPA) และมาตรฐานความมั่นคงปลอดภัยสากล
การนำ Voice‑KYC 2.0 สู่การใช้งานจริงต้องอาศัยการทดสอบต่อเนื่อง (continuous testing และ adversarial/red‑team testing), การอัปเดตโมเดลเพื่อต่อสู้กับเทคนิค deepfake ใหม่ ๆ และการตรวจสอบเชิงปฏิบัติ (operational monitoring) เพื่อรักษาความแม่นยำในสภาพแวดล้อมจริง การบูรณาการกับระบบตรวจจับการฉ้อโกงแบบองค์รวม (fraud‑management), ช่องทางบริการอื่น (เว็บ แอป สาขา) และกระบวนการยืนยันตัวตนหลายปัจจัยจะช่วยให้ผลลัพธ์ยั่งยืน โดยธนาคารควรกำหนดแผนการนำร่อง (pilot) ที่มีตัวชี้วัดชัดเจน ทดลองกับกรณีการใช้งานจริง เช่น การยืนยันธุรกรรมทางโทรศัพท์หรือการเปิดบัญชี แล้วค่อยขยายสเกล พร้อมกับการสื่อสารเชิงโปร่งใสต่อผู้ใช้เกี่ยวกับความเสี่ยงและการคุ้มครองข้อมูล เพื่อสร้างสมดุลระหว่างความปลอดภัย ประสิทธิภาพการให้บริการ และความไว้วางใจของผู้ใช้ในระยะยาว



