
ในยุคที่โรงงานอุตสาหกรรมต้องการความแม่นยำและความเร็วในการตรวจสอบคุณภาพมากขึ้น โรงงานยานยนต์ไทยหนึ่งแห่งได้ก้าวข้ามขีดจำกัดด้วยการนำเทคโนโลยี Self‑Supervised Video Representation ผสานกับ Contrastive Learning มารันบน Edge GPU เพื่อทำการตรวจจับข้อบกพร่องบนสายพานแบบเรียลไทม์ ผลลัพธ์ที่ได้คือการลดของเสียลงถึง 25% พร้อมการตอบสนองเชิงปฏิบัติการที่ทันทีและลดงานตรวจสอบด้วยมนุษย์ ซึ่งเป็นกรณีศึกษาที่สะท้อนการเปลี่ยนผ่านสู่การผลิตอัจฉริยะ (Smart Manufacturing) ในไทยอย่างชัดเจน
บทนำนี้จะพาอ่านไปยังประเด็นสำคัญของบทความ: วิธีการทำงานของโมเดลวิดีโอแบบ self‑supervised และกลยุทธ์ contrastive learning ที่ช่วยให้ระบบเรียนรู้ลักษณะข้อบกพร่องจากข้อมูลวิดีโอจำนวนมากโดยไม่ต้องพึ่งป้ายฉลากจำนวนมาก การปรับใช้บน Edge GPU เพื่อรักษาความหน่วงต่ำและความเป็นส่วนตัวของข้อมูลเชิงภาพ ตลอดจนรายละเอียดเชิงเทคนิค กระบวนการติดตั้งในสายการผลิต ผลการวัดเชิงธุรกิจ เช่น อัตราการลดของเสีย เวลาในการตอบสนอง และผลตอบแทนการลงทุน ที่สามารถนำไปเป็นแนวทางสำหรับโรงงานอื่น ๆ ที่ต้องการยกระดับการควบคุมคุณภาพด้วย AI
บทนำ: ภูมิหลังและเหตุผลที่ต้องปรับใช้ AI ในสายการผลิต
บทนำ: ภูมิหลังและเหตุผลที่ต้องปรับใช้ AI ในสายการผลิต
อุตสาหกรรมยานยนต์ของไทยเป็นหนึ่งในภาคการผลิตที่สำคัญต่อเศรษฐกิจประเทศ มีโรงงานชิ้นส่วนและประกอบยานยนต์กระจายอยู่ทั่วประเทศและมีปริมาณการผลิตเกินกว่า หนึ่งล้านคันต่อปี ในช่วงก่อนหน้าการชะลอตัวจากปัจจัยภายนอก จำนวนการผลิตและการส่งออกทำให้ความคาดหวังด้านคุณภาพสูงขึ้นอย่างต่อเนื่อง ทั้งนี้ ความผิดพลาดบนสายการประกอบ เช่น ชิ้นส่วนบกพร่อง การประกอบไม่ครบถ้วนหรือความเสียหายระหว่างการขนย้าย จะส่งผลโดยตรงต่อคุณภาพผลิตภัณฑ์ ความน่าเชื่อถือของแบรนด์ และต้นทุนการผลิตโดยรวม
ข้อบกพร่องบนสายการผลิตไม่เพียงแต่เป็นปัญหาทางเทคนิค แต่ยังเป็นต้นเหตุของการสูญเสียเชิงเศรษฐกิจทั้งในรูปแบบของ scrap การแก้ไข (rework) เวลาหยุดสาย และต้นทุนการรับประกันหลังการขาย ตัวอย่างเช่น อัตราของเสียในบางกระบวนการอาจอยู่ในระดับเปอร์เซ็นต์เดียว แต่เมื่อคำนวณรวมกับมูลค่าการผลิตทั้งโรงงานแล้ว สามารถหมายถึงการสูญเสียเป็นจำนวนหลายสิบถึงหลายร้อยล้านบาทต่อปี นอกจากนี้ การตรวจสอบด้วยมนุษย์เพียงอย่างเดียวมักเผชิญปัญหาเรื่องความไม่สม่ำเสมอ ความเหนื่อยล้า ทำให้มีทั้ง false negative (พลาดข้อบกพร่อง) และ false positive (เตือนเกินจริง) ซึ่งส่งผลต่อประสิทธิภาพการผลิตและต้นทุนแรงงาน
ด้วยบริบทนี้ โครงการนำระบบตรวจจับข้อบกพร่องแบบเรียลไทม์บนสายพานโดยใช้เทคโนโลยี self‑supervised video representation ร่วมกับ contrastive learning และรันบน Edge GPU จึงถูกออกแบบขึ้นเพื่อแก้ปัญหาหลัก ได้แก่ การจับข้อบกพร่องที่เกิดขึ้นแบบเรียลไทม์ ลดการพึ่งพาการติดป้ายกำกับข้อมูลปริมาณมาก และรักษาความเป็นส่วนตัวของข้อมูลภาพภายในโรงงาน วัตถุประสงค์เชิงปฏิบัติของโครงการคือ ลดของเสีย 25% ผ่านการตรวจจับที่รวดเร็วและแม่นยำ เพื่อนำไปสู่การลด rework การลดเวลาหยุดสาย และการเพิ่ม first‑pass yield
ภาพรวมการนำไปใช้รวมถึงการติดตั้งกล้องความละเอียดสูงตามจุดวิกฤติบนสายพาน การประมวลผลวิดีโอแบบ onsite บน Edge GPU เพื่อลด latency และปัญหาการเชื่อมต่อกับคลาวด์ ตลอดจนการฝึกโมเดลด้วยข้อมูลวิดีโอแบบ self‑supervised เพื่อลดภาระการติดป้ายกำกับข้อมูลจำนวนมาก ในกรณีศึกษาจากโรงงานตัวอย่างในอุตสาหกรรมยานยนต์ โซลูชันดังกล่าวสามารถตรวจจับข้อบกพร่องได้ในเวลาต่ำกว่าเสี้ยววินาที ลดอัตราของเสียได้ตามเป้าหมายที่ 25% พร้อมผลพลอยได้เชิงธุรกิจ เช่น การลดงานตรวจสอบด้วยมือ การเพิ่มความสม่ำเสมอของคุณภาพ และการคืนทุนภายในระยะเวลาที่สั้นขึ้นเมื่อเทียบกับมาตรการแบบดั้งเดิม
- ปัญหาหลัก: ข้อบกพร่องบนสายการผลิตส่งผลต่อคุณภาพ ต้นทุน และเวลาการส่งมอบ
- เป้าหมายโครงการ: ลดของเสีย 25% ด้วยการตรวจจับแบบเรียลไทม์
- แนวทางเทคโนโลยี: ใช้ self‑supervised video representation + contrastive learning รันบน Edge GPU เพื่อความเร็วและความเป็นส่วนตัวของข้อมูล
- ผลลัพธ์เบื้องต้น: โรงงานตัวอย่างบรรลุเป้าลดของเสีย 25% พร้อมการปรับปรุงด้านประสิทธิภาพการตรวจจับและต้นทุนการดำเนินงาน
เทคโนโลยีหลัก: Self‑supervised Video Representation และ Contrastive Learning คืออะไร
เทคโนโลยีหลัก: Self‑supervised Video Representation และ Contrastive Learning คืออะไร
ในบริบทการตรวจจับข้อบกพร่องบนสายพานในโรงงาน อัลกอริทึม self‑supervised learning (SSL) สำหรับวิดีโอหมายถึงกระบวนการเรียนรู้ลักษณะเชิงตัวแทน (representation) ของคลิปวิดีโอจากข้อมูลไม่มีป้ายกำกับ (unlabeled) โดยใช้งานย่อย (pretext tasks) ที่ออกแบบให้เครือข่ายสามารถเรียนรู้โครงสร้างเชิงสเปเชียลและเทมโพรัลของวิดีโอ เช่น การเรียงลำดับเฟรม การทำนายเฟรมถัดไป หรือการกรอกเฟรมที่ถูกปิดบัง จุดเด่นสำคัญคือ SSL ช่วยลดการพึ่งพา labeled data ที่มีต้นทุนสูง ทั้งในเชิงเวลาและค่าแรงของผู้เชี่ยวชาญ ตัวอย่างเช่น การติดป้ายวิดีโอของสายพานผลิตภัณฑ์หลายชั่วโมงอาจต้องใช้ทีมผู้เชี่ยวชาญและเวลานับร้อยชั่วโมง ซึ่งไม่เหมาะสำหรับการขยายระบบไปยังไลน์การผลิตหลายจุด
หนึ่งในกรอบแนวคิดที่ได้รับความนิยมในการเรียนรู้ representation คือ contrastive learning โดยใช้ loss ฟังก์ชันเช่น InfoNCE ที่ผลักดันให้ embedding ของตัวอย่างคู่ที่เป็น "บวก" (positive pairs — มุมมองหรือการแปลงที่ควรมีความหมายเดียวกัน) เข้าใกล้กันในเวกเตอร์สเปซ และผลัก embedding ของตัวอย่าง "ลบ" (negative pairs) ให้ห่างออกไป เทคนิคนี้ทำให้โมเดลสร้าง embedding ที่มีความสามารถในการแยกแยะเหตุการณ์ปกติและเหตุการณ์ผิดปกติได้ดี เพราะเหตุการณ์ปกติที่มีลักษณะซ้ำ ๆ จะรวมตัวเป็นคลัสเตอร์ที่หนาแน่น ขณะที่เหตุการณ์ผิดปกติจะอยู่ห่างออกไปเมื่อวัดด้วยความคล้ายคลึงของ embedding

เชิงเทคนิค InfoNCE ทำงานโดยการเพิ่มค่า similarity (เช่น cosine similarity) ระหว่าง embedding ของ positive pairs และลดค่า similarity กับ negative samples จำนวนมากที่สุด ตัวอย่างเช่น ในการเทรนเครือข่ายสำหรับวิดีโอ เราอาจสร้าง positive pair จากการดึง crops ของช่วงเวลาใกล้เคียงกันหรือมุมกล้องต่างกันของวิดีโอเดียวกัน และใช้ช่วงเวลาจากวิดีโออื่น ๆ เป็น negative samples ผลที่ได้คือ embedding ที่มีความแยกเชิงสถิติระหว่าง pattern ปกติและ pattern ที่แปลกเบี่ยงเบน ทำให้สามารถนำไปใช้กับกลยุทธ์ตรวจจับความผิดปกติต่าง ๆ เช่น การกำหนด threshold ระยะทางใน space ของ embedding, k‑NN density, หรือโมเดล one‑class
การออกแบบการแปลงเชิงเวลา (temporal augmentations) และการใช้ข้อมูลความเคลื่อนไหวเช่น optical flow มีบทบาทสำคัญสำหรับงานที่ข้อบกพร่องปรากฏในลักษณะการเคลื่อนไหว ตัวอย่างของ temporal augmentations ได้แก่:
- การสุ่มเลือกช่วงเวลา (temporal cropping) และการสลับลำดับเฟรม (frame shuffling แบบบีบอัด)
- การเปลี่ยนความเร็วของคลิป (speed perturbation), การย้อนเวลา (time reversal)
- การบิดเบือนเชิงอวกาศ-เวลา (spatio‑temporal jittering) และการซ้อนหน้ากากบางส่วน (masking)
การเพิ่มช่องสัญญาณ optical flow เข้าไปยังอินพุตหรือเรียนรู้ branch แยกสำหรับ flow ช่วยให้เครือข่ายจับพฤติกรรมการเคลื่อนไหว เช่น การลื่นไถลของชิ้นงาน, การกระเด้ง, หรือการเคลื่อนผิดแกน ซึ่งมักเป็นสัญญาณเชิงสำคัญของข้อบกพร่องบนสายพาน
การประยุกต์จริงในงานตรวจจับข้อบกพร่องจะมี pipeline ดังนี้โดยสรุป: รวบรวมวิดีโอจำนวนมากจากกล้องไลน์การผลิต (ไม่จำเป็นต้องติดป้าย), สร้างคู่ positive/negative โดยใช้ temporal augmentations และ optical flow, เทรนโมเดลด้วย contrastive loss (เช่น InfoNCE) เพื่อให้ได้ embedding คุณภาพสูง จากนั้นนำ embedding นี้ไปใช้บนเครื่องมือตรวจจับความผิดปกติแบบเรียลไทม์บน Edge GPU โดยตรวจสอบค่า distance หรือ density และแจ้งเตือนเมื่อพบคลิปที่ embedding เบี่ยงจากคลัสเตอร์ปกติ ขั้นตอน fine‑tuning ด้วยชุดข้อมูลเล็ก ๆ ที่ติดป้ายสามารถทำเพื่อยกระดับความแม่นยำได้โดยไม่ต้องติดป้ายจำนวนมาก
ข้อสรุปที่สำคัญสำหรับภาคอุตสาหกรรมคือ self‑supervised + contrastive learning ให้ทางเลือกที่คุ้มค่าและยืดหยุ่นสำหรับงานตรวจจับข้อบกพร่องที่มีลักษณะเชิงเคลื่อนไหว โดยลดความจำเป็นของ labeled data อย่างมีนัยสำคัญ (ในงานภาคอุตสาหกรรมหลายกรณีสามารถลดความต้องการ labeled data ได้ถึงหลักสิบเปอร์เซ็นต์ถึงเกือบทั้งชุด ขึ้นกับเงื่อนไขการเก็บข้อมูล) และเมื่อผสานกับ temporal augmentations และ optical flow จะได้ representation ที่สามารถแยกเหตุการณ์ปกติกับเหตุการณ์ผิดปกติได้ชัดเจน เหมาะสำหรับการรันบน Edge GPU เพื่อตรวจจับข้อบกพร่องแบบเรียลไทม์และลดของเสียในการผลิต
สถาปัตยกรรมระบบและการประมวลผลบน Edge
สถาปัตยกรรมระบบและการประมวลผลบน Edge
สถาปัตยกรรมที่นำมาใช้ในโครงการนี้ออกแบบเพื่อให้สามารถรันโมเดล self‑supervised video representation ร่วมกับการฝึกแบบ contrastive learning บน Edge GPU ได้อย่างต่อเนื่องและมีความหน่วงต่ำ โดยเส้นทางข้อมูลตั้งแต่เซนเซอร์จนถึงคลาวด์ประกอบด้วยส่วนสำคัญดังนี้: กล้องอุตสาหกรรม → pre‑processing บนเครื่อง (หรือ GPU) → Edge GPU สำหรับการทำ inference → ระบบแจ้งเตือนและ dashboard บนคลาวด์/ท้องถิ่น พร้อม local storage สำหรับสำรองวิดีโอและเหตุการณ์สำคัญ ในการติดตั้งจริงใช้ตัวอย่างฮาร์ดแวร์อย่าง NVIDIA Jetson Orin หรือ Xavier (รุ่น NX/AGX ตามความต้องการด้านประสิทธิภาพ) เพื่อให้ได้ความสามารถในการประมวลผลวิดีโอแบบเรียลไทม์
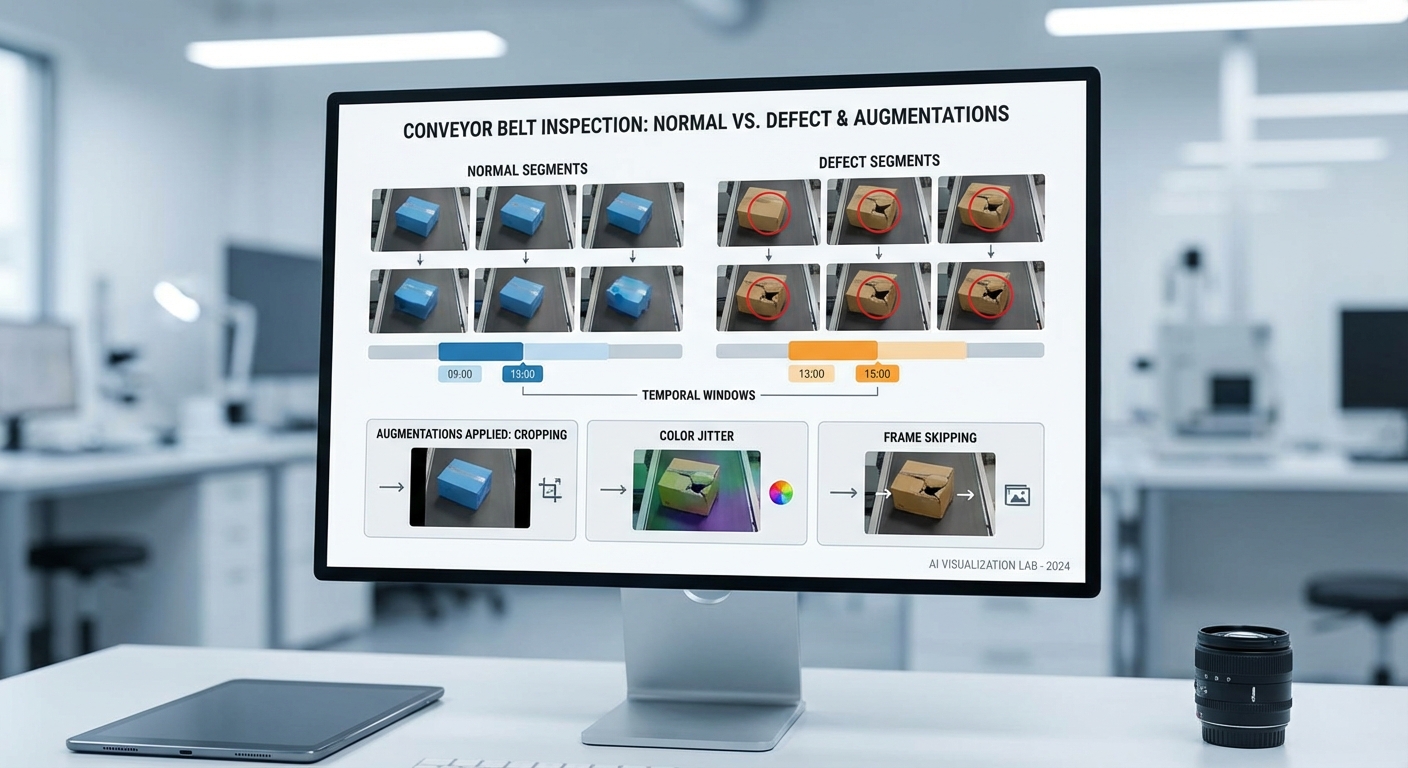
ชิ้นส่วนหลักของระบบสามารถแจกแจงเป็นรายการได้ดังนี้:
- กล้องอุตสาหกรรม: ให้สัญญาณภาพความละเอียดและเฟรมเรตตามจุดตรวจ (ตัวอย่าง 720p–1080p ที่ 15–60 FPS ขึ้นกับเส้นทางสายพาน)
- Pre‑processing: การปรับขนาด (resize), สี (color normalization), การเลือกเฟรม (frame sampling), และการคำนวณ optical flow ขั้นต้น — สามารถเร่งด้วย CUDA/VPI บน Edge
- Edge GPU: NVIDIA Jetson Orin/Xavier ให้การเร่ง inference ผ่าน TensorRT/ONNX Runtime พร้อมการควบคุม container (Docker) เพื่อความยืดหยุ่นในการ deploy
- Local storage & ring buffer: SSD/embedded flash เก็บวิดีโอล่าสุด (เช่น 10–30 วินาทีหรือเหตุการณ์ที่จับได้) เพื่อการตรวจสอบย้อนหลังเมื่อระบบแจ้งเตือน
- Network & Cloud Dashboard: เครือข่ายพื้นฐาน 1GbE/10GbE ระหว่าง Edge ↔ Cloud, โปรโตคอล MQTT/HTTPS สำหรับแจ้งเตือนและ metadata, WebSocket/API สำหรับ dashboard ที่แสดง KPI และคลิปเหตุการณ์
โฟลว์ของ pipeline วิดีโอถูกออกแบบให้สมดุลระหว่างความหน่วงและความแม่นยำโดยมีองค์ประกอบสำคัญดังนี้:
- Frame sampling: สำหรับสายพานที่เคลื่อนเร็วอาจต้องใช้ 25–30 FPS แบบ full sampling; ในจุดที่ความเร็วต่ำสามารถลดเป็น 15–20 FPS หรือใช้การ sampling แบบ stride (เช่น ทุก 2‑3 เฟรม) เพื่อลดภาระ
- Temporal window & batching: โมเดลวิดีโอมักใช้หน้าต่างเวลา 8–16 เฟรมเป็นอินพุต การทำ batching ช่วยเพิ่ม throughput แต่จะเพิ่ม latency; สำหรับเงื่อนไขเรียลไทม์แนะนำใช้ batch size = 1 หรือ micro‑batching เพื่อรักษา latency ต่ำ
- Optical flow & motion features: การคำนวณ optical flow (ตัวอย่างเช่น Farneback หรือ GPU‑accelerated TVL1/VPI) ถูกใช้เป็นลักษณะเสริมให้โมเดล contrastive สามารถแยกการเปลี่ยนแปลงเชิงเคลื่อนไหวได้ดีขึ้น — บน Jetson ค่าใช้จ่ายของ optical flow มักอยู่ในช่วงไม่กี่มิลลิวินาทีต่อเฟรมเมื่อเร่งด้วย GPU
- Post‑processing & alerting: การกรอง false positive, การรวมเหตุการณ์ซ้ำ, และการส่งเมตริก/คลิปผ่าน MQTT หรือ HTTPS ไปยังระบบแจ้งเตือนและ dashboard
ข้อกำหนดด้านประสิทธิภาพของระบบถูกตั้งตามเงื่อนไขการใช้งานจริงในสายการผลิต โดยมีเป้าหมายสำคัญดังนี้: Inference latency น้อยกว่า 50 ms ต่อเฟรม (เพื่อให้สามารถตอบสนองได้ในกรณีต้องหยุดสายพานทันที) และ throughput 15–30 FPS ขึ้นกับจุดตรวจ (จุดที่มีความเร็วและความหนาแน่นของชิ้นงานสูงต้องการระดับ 25–30 FPS ขณะที่จุดตรวจทั่วไป 15–20 FPS เพียงพอ) นโยบาย latency ควรแจกแจงเป็นงบประมาณย่อย เช่น capture + pre‑proc 5–10 ms, inference <50 ms, post‑proc + alert 5–10 ms เพื่อให้ end‑to‑end latency อยู่ในช่วงที่ยอมรับได้ (<100 ms ในกรณีต้องการการตอบสนองแบบ near‑real‑time)
เพื่อให้บรรลุเป้าหมายด้าน latency และความเสถียร มีแนวปฏิบัติที่สำคัญด้านซอฟต์แวร์และการปรับแต่ง:
- Containerization (Docker): แต่ละโมดูล (capture, pre‑processing, inference, uploader) แยก container เพื่อการจัดการเวอร์ชันและการอัปเดตแบบไม่กระทบส่วนอื่น ๆ ในโรงงาน — สามารถใช้ lightweight orchestration เช่น k3s สำหรับการจัดการคลัสเตอร์ Edge ขนาดเล็ก
- Inference acceleration: แปลงโมเดลเป็น ONNX แล้วใช้ TensorRT หรือ ONNX Runtime (CUDA provider) เพื่อทำการ quantization (FP16/INT8) และ kernel fusion — ผลลัพธ์ในงานภาคสนามมักเห็นความเร็วเพิ่มขึ้น 2–8× เมื่อเทียบกับ PyTorch แบบดั้งเดิม
- Memory & I/O tuning: การใช้ pinned memory, zero‑copy buffers และการทำ prefetching ช่วยลด overhead ของการคัดลอกข้อมูลระหว่าง CPU ↔ GPU และรักษา throughput ที่เสถียร
- Reliability: เมื่อเกิดการขาดการเชื่อมต่อกับคลาวด์ ระบบยังคงรัน inference บน Edge และบันทึกข้อมูลลง local storage เพื่อ upload ย้อนหลังเมื่อเชื่อมต่อกลับได้
สรุปแล้ว สถาปัตยกรรม Edge‑to‑Cloud ที่ผนวกโมเดล self‑supervised + contrastive learning บน Jetson Orin/Xavier พร้อมการใช้ Docker และ TensorRT/ONNX Runtime จะช่วยให้ระบบตรวจจับข้อบกพร่องบนสายพานทำงานได้แบบเรียลไทม์ โดยรักษา latency ในระดับต่ำและ throughput ที่เพียงพอต่อการใช้งานในโรงงาน — ส่งผลให้การลดของเสียตามกรณีศึกษาสามารถเกิดขึ้นได้จริงเมื่อองค์ประกอบฮาร์ดแวร์ ซอฟต์แวร์ และการออกแบบ pipeline ถูกปรับจูนร่วมกัน
การเตรียมข้อมูลและกลยุทธ์การเทรนโมเดล
การเก็บข้อมูลวิดีโอ: การตั้งค่า sampling และการแบ่งหน้าต่างเวลา
การเตรียมข้อมูลเริ่มจากการออกแบบการเก็บวิดีโอจากกล้องบนสายพานให้สอดคล้องกับลักษณะข้อบกพร่องที่ต้องการตรวจจับ ในกรณีศึกษาโรงงานยานยนต์ แนะนำค่าพื้นฐานดังนี้: ใช้ sampling rate ระหว่าง 15–30 fps สำหรับงานที่ข้อบกพร่องมีขนาดเล็กและความเร็วสายพานปานกลาง; หากสายพานเร็วหรือต้องการจับจังหวะสั้น ๆ อาจเพิ่มเป็น 60 fps เฉพาะจุดสำคัญเท่านั้น ตัวอย่างการจัดหน้าต่างข้อมูลให้ใช้ window ขนาด 2–5 วินาที ต่อหนึ่งตัวอย่าง (ตัวอย่างเช่น window 3 วินาที ที่ 30 fps เท่ากับ 90 เฟรม) โดยใช้การเลื่อนหน้าต่าง (sliding window) ด้วย stride ระหว่าง 0.5–1.0 วินาที เพื่อให้ครอบคลุมเหตุการณ์และรักษาสัดส่วนตัวอย่างบวก/ลบ
เพื่อให้จำนวนตัวอย่างเพียงพอ สมมติฐาน: หากบันทึก 100 ชั่วโมง ที่ 30 fps และใช้ window 3 วินาที กับ stride 1 วินาที จะได้ตัวอย่างประมาณ 360,000 windows — จำนวนที่เพียงพอสำหรับการฝึกแบบ self‑supervised ในระดับอุตสาหกรรม โดยเฉพาะเมื่อผสานกับการขยายข้อมูล (augmentation) หลายมุมมอง

การสร้าง positive / negative samples ในบริบท self‑supervised สำหรับ anomaly detection
ในระบบ self‑supervised ที่มุ่งไปสู่การตรวจจับความผิดปกติ (anomaly detection) แนวทางปกติคือใช้ข้อมูล normal เป็นหลักในการเรียนรู้ representation ของสถานะปกติ แล้วตรวจจับความเบี่ยงเบนเป็น anomaly สำหรับการกำหนดคู่ใน contrastive learning:
- Positive pairs: สร้างจากมุมมองที่ต่างกันของ same temporal window หรือจากหน้าต่างที่อยู่ใกล้กัน (เช่น ภายใน ±0.5–1.0 วินาที) โดยใช้ augmentation temporal & spatial เพื่อให้เครือข่ายเรียนรู้ความคงตัวของสถานะปกติ
- Negative pairs: เลือกจาก windows ที่ไม่ทับซ้อนกัน หรือมาจากช่วงเวลาหรือเครื่องจักรที่ต่างกัน เพื่อลดความเสี่ยงที่เครือข่ายจะจับสัญญาณจำเพาะของฉากเดียวกันเป็นตัวแยก
- ข้อควรระวัง: เนื่องจาก anomaly มักหายาก ควรฝึก representation ด้วยข้อมูลปกติมากที่สุด และเก็บตัวอย่าง anomaly เพื่อการปรับจูน (fine‑tuning) หรือการประเมินเท่านั้น
เทคนิค augmentation — temporal และ spatial ที่แนะนำ
การออกแบบ augmentation ต้องรักษาเอกลักษณ์ของข้อบกพร่องไว้ในขณะเดียวกันก็ต้องสร้างมุมมองแตกต่างเพียงพอให้ contrastive signal ชัดเจน เทคนิคที่ใช้งานได้ดีรวมถึง:
- Temporal augmentations: temporal crop (สุ่มเลือก subsequence ภายใน window ความยาว 1–3 วินาที), speed jitter (0.8–1.2x), frame dropping (สุ่มลบ 0–20% เฟรม), temporal shift ±0.2–0.5 วินาที, และการผสม frame order (เล็กน้อย) เพื่อให้โมเดลเรียนรู้ความทนทานต่อการสั่นไหวของการจับภาพ
- Spatial augmentations: random crop (scales 0.7–1.0 ของพื้นที่), horizontal flip (เฉพาะเมื่อสมมาตรไม่ทำให้ผิดความหมาย), small rotation ±5°, random resize, และ spatial blur
- Photometric changes: brightness ±20–40%, contrast jitter, color jitter, additive Gaussian noise (SNR ที่เหมาะสม), และการจำลอง compression artifacts เพื่อสะท้อนสภาพจริงของกล้อง Edge
- นโยบายการใช้แรงกระทำ (augmentation strength): สำหรับ anomaly detection แนะนำใช้มุมมองหนึ่งเป็น weak augmentation (รักษาลักษณะข้อบกพร่อง) และอีกมุมมองเป็น strong augmentation เพื่อสร้างความต่างทางภาพแต่ไม่ทำลายสัญญาณของข้อบกพร่อง
การเลือก loss function และกลยุทธ์ batching
สำหรับงาน contrastive representation learning ในวิดีโอ Loss ที่เป็นมาตรฐานมีดังนี้:
- InfoNCE / NT‑Xent: ใช้บ่อยที่สุด ร่วมกับ temperature τ แนะนำตั้งระหว่าง 0.05–0.2 (เช่น τ=0.07) เพื่อคัดแยก embedding ของตัวอย่างที่ต่างกัน
- Triplet / Margin‑based losses: เหมาะเมื่อสามารถจัดชุด anchor‑positive‑hard negative ได้ชัดเจน แต่ต้องใช้ mining ที่ระมัดระวัง
- MoCo (memory bank + momentum encoder): ช่วยให้ใช้ batch เล็กลงแต่ยังคง negatives จำนวนมาก โดยใช้คิวของ negative representations
- BYOL / SimSiam: หากต้องการหลีกเลี่ยง negative sampling แบบชัดเจน สามารถใช้แนวทาง no‑negative แต่ต้องระวัง collapse และการปรับ hyperparameter
ด้าน batching strategy ควรให้ความสำคัญกับจำนวน negatives ในแต่ละ batch และความหลากหลายของแหล่งข้อมูล:
- ใช้ multi‑view per sample (อย่างน้อย 2 views; 3–4 views หากต้องการ robustness เพิ่มขึ้น)
- ออกแบบ batch ให้มีตัวอย่างจาก กล้อง/เวลาหลายจุด เพื่อหลีกเลี่ยง bias หาก batch มาจากฉากเดียวจะลดประสิทธิภาพการแยก
- หาก GPU memory จำกัด ให้ใช้ memory bank / momentum encoder (MoCo) หรือ gradient accumulation เพื่อจำลอง batch ใหญ่
- สำหรับ anomaly detection ควรสำรองกลุ่ม validation ที่มี anomaly น้อย ๆ เพื่อใช้ประเมิน AUC/ROC ระหว่างการฝึก
การตั้งค่า hyperparameters ที่แนะนำ (ตัวอย่าง)
การตั้งค่าต่อไปนี้เป็นค่าเริ่มต้นที่สามารถใช้ได้ทั้งการฝึกบนเซิร์ฟเวอร์และการปรับเพื่อลงสู่ Edge GPU:
- Batch size: 128–256 (ฝึกบนคลัสเตอร์); หากจำกัดหน่วยความจำ ใช้ 32–64 ร่วมกับ gradient accumulation เพื่อจำลอง batch ขนาดใหญ่
- Learning rate (SGD with momentum): base LR ≈ 0.1 สำหรับ batch 256 ตามกฎ linear scaling (LR = 0.1 * batch/256). สำหรับ AdamW ใช้ LR ≈ 1e‑3 และ weight decay 1e‑2–1e‑4
- Learning rate schedule: linear warmup 5–10 epochs ตามด้วย cosine decay (หรือ step decay หากต้องการความเรียบง่าย)
- Embedding dimension: 128–512 โดยทั่วไป 128 เพียงพอและประหยัด memory เหมาะสำหรับ deployment บน Edge; หากต้องการ capacity มากขึ้นใช้ 256
- Projection head: MLP 2–3 ชั้น (ตัวอย่าง: 2048 -> 512 -> embedding) พร้อม batchnorm และ ReLU
- Temperature (τ): 0.05–0.2 (ค่าเริ่มต้น 0.07 แนะนำสำหรับ NT‑Xent)
- Epochs: 100–300 สำหรับ pretraining ขึ้นกับขนาด dataset; ติดตาม AUC/ROC validation เพื่อตัดสินใจ early stopping
- Optimizer: SGD + momentum 0.9 สำหรับ batch ขนาดใหญ่; LARS สำหรับ batch ใหญ่พิเศษ; หรือ AdamW สำหรับเรียนรู้แบบละเอียด
- อื่น ๆ: ใช้ mixed precision (FP16) เพื่อเพิ่ม throughput; ใช้ data shuffling ระดับสูงเพื่อกระจาย negatives
สรุปแล้ว การเตรียมข้อมูลและกลยุทธ์การเทรนควรเน้นที่การเก็บตัวอย่าง normal ให้ครอบคลุมสภาพการทำงานจริง การออกแบบ positive/negative samples ที่สอดคล้องกับเป้าหมาย anomaly detection และการเลือก augmentation + loss function ที่ไม่ทำลายสัญญาณของข้อบกพร่อง ทั้งนี้การตั้งค่า hyperparameter จะต้องปรับจูนตามทรัพยากร (เช่น Edge GPU) และขนาดข้อมูลจริง เพื่อให้ได้ representation ที่แยกข้อบกพร่องออกจากสภาพแวดล้อมปกติได้อย่างน่าเชื่อถือ
การปรับแต่งและเร่งประสิทธิภาพสำหรับการรันบน Edge
การปรับแต่งและเร่งประสิทธิภาพสำหรับการรันบน Edge
การนำโมเดล self‑supervised video representation ร่วมกับการเรียนรู้แบบ contrastive ขึ้นไปรันบน Edge GPU ในสภาพแวดล้อมโรงงาน จำเป็นต้องมีการปรับแต่งเชิงเทคนิคหลายชั้นเพื่อให้ได้ latency ต่ำ น้ำหนักโมเดลเล็ก และความทนทานต่อความร้อน/พลังงาน ในกรณีศึกษานี้ ทีมงานใช้ชุดเทคนิคหลักได้แก่ quantization (INT8), pruning, knowledge distillation และการแปลงโมเดลเป็น ONNX/TensorRT engine พร้อมการออกแบบ pipeline แบบเรียลไทม์ (multi‑threading, frame skipping) ผลลัพธ์ที่ได้คือขนาดโมเดลและ latency ลดลงอย่างมีนัยสำคัญโดยเก็บรักษาความแม่นยำให้สูญเสียน้อยที่สุด

Quantization (INT8) และ Pruning — ขั้นตอนและผลเชิงตัวเลข: เริ่มจากการวัด baseline โมเดลก่อนปรับแต่ง เช่น โมเดลต้นฉบับขนาด ~60MB ให้ latency ประมาณ 40–50 ms ต่อเฟรม (batch size = 1) บน NVIDIA Jetson Xavier NX ในการลดขนาดและเร่งความเร็วใช้แนวทางต่อไปนี้
- Post‑training INT8 Quantization: ส่งออกโมเดลเป็น ONNX (opset 11–13) แล้วใช้ TensorRT สร้าง engine แบบ INT8 โดยกำหนด calibration dataset ประมาณ 500–1,000 ตัวอย่างจากกล้องโรงงาน การใช้ per‑channel quantization และ calibration cache ช่วยลดการลดทอนความแม่นยำ ตัวอย่างผล: ความแม่นยำลดลง 0.5–2.0% แต่ latency ลดจาก 45ms → 12ms
- Pruning (structured channel pruning): ตัดช่องหรือฟิลเตอร์ที่มีค่าน้ำหนักต่ำ (magnitude‑based) ในระดับ 30–50% แล้วทำ fine‑tune อีก 5–20 epochs เพื่อนำความแม่นยำกลับคืน ตัวอย่างผลเชิงปฏิบัติ: ลดพารามิเตอร์ 40% → ลดขนาดโมเดลจาก 60MB → 18MB ก่อน quantization และหลัง quantization+pruning เหลือ 10–12MB
- ผลลัพธ์ร่วม: เมื่อใช้ pruning + INT8 บน Edge GPU latency ลดลงเหลือ 8–15 ms/เฟรม (ขึ้นกับสถาปัตยกรรม), throughput เพิ่มเป็น ~60–120 FPS ในขณะที่ความแม่นยำลดลงเฉลี่ย 0.5–3% ซึ่งยอมรับได้ในงานตรวจจับข้อบกพร่องสายพาน
Knowledge Distillation และการออกแบบสถาปัตยกรรม Student Model: เพื่อชดเชยการสูญเสียจาก pruning/quantization ใช้การ distill จาก teacher model ขนาดใหญ่ (เช่น teacher 50M params) ไปยัง student เล็ก (8–12M params) โดยใช้ loss แบบร่วม (soft label loss + task loss) กับ temperature T และ weight α ที่ปรับค่า ตัวอย่างการตั้งค่า: T = 4, α = 0.7 จากการทดลองพบว่า student ที่ผ่าน distillation มีความแม่นยำใกล้เคียง teacher (loss ในงานตรวจจับลดลง < 2%) ขณะเดียวกันน้ำหนักและ latency อยู่ในข้อกำหนดของ Edge
แปลงเป็น ONNX/TensorRT — ขั้นตอนที่แนะนำ:
- Export จาก PyTorch ไปเป็น ONNX (opset 11–13) พร้อมระบุ dynamic_axes เฉพาะแกน batch/sequence หากจำเป็น แต่สำหรับ real‑time แนะนำ batch=1 คงที่
- ใช้ onnx‑simplifier เพื่อลดกราฟและตรวจจับ ops ที่ไม่รองรับ
- สร้าง TensorRT engine ด้วย trtexec หรือ TensorRT Python API: ระบุ --fp16 หรือ --int8 พร้อม calibration cache (สำหรับ INT8) และกำหนด workspace size ให้เพียงพอ
- เปิดการทำ layer fusion, kernel auto‑tuning และกำหนด batch size = 1 เพื่อ latency ต่ำสุด
การตั้งค่า pipeline สำหรับการรันเรียลไทม์บน Edge: การออกแบบ pipeline มีผลต่อ latency จริงในโรงงานมากกว่าค่า latency เฉพาะ inference ดังนั้นควรแยกหน้าที่เป็นหลายเธรดและใช้ CUDA streams เพื่อ overlap งาน:
- Capture thread: ดึงเฟรมจากกล้องด้วย zero‑copy / pinned memory (GStreamer หรือ V4L2) ส่งเข้า queue
- Pre‑processing thread (GPU): รวมการปรับขนาด, normalization และการแปลงสีโดยใช้ CUDA kernels เพื่อไม่ให้บล็อก CPU
- Inference thread(s): ใช้ TensorRT engine แบบ batch=1; หากอุปกรณ์รองรับ ให้ใช้หลาย CUDA stream เพื่อทำ concurrency ระหว่าง copy และ execute
- Post‑processing & Output thread: ทำ non‑max suppression, tracking, และส่งสัญญาณแจ้งเตือน โดยแยกออกจาก inference เพื่อให้ latency คงที่
- Frame skipping policy: ประยุกต์ใช้การประมวลผล “N‑th frame” หรือ adaptive skipping เมื่อการเคลื่อนไหวต่ำ เช่น ประมวลผลทุก 2–3 เฟรม และใช้ motion detector เพื่อประมวลผลทันทีเมื่อพบเหตุการณ์
Stress Test — การทดสอบความทนทานด้านพลังงานและความร้อน: ก่อน deployment จริงต้องทำ stress test จำลองสภาพโรงงาน (ambient 30–40°C, ฝุ่น เลือกจุดติดตั้งจริง) โดยการรันระบบต่อเนื่อง 8–24 ชั่วโมง พร้อมบันทึกเมตริกต่อไปนี้
- อุณหภูมิชิป GPU/CPU: วัดโดยอุปกรณ์บันทึกหรืออาศัยตัววัดภายใน (ตัวอย่างผลการทดสอบ: อุณหภูมิเฉลี่ยขณะรัน 70–82°C; เกิด thermal throttling เมื่อล่วงเกิน 85°C)
- การใช้พลังงาน (Watt): วัดจาก power meter inline เช่น ผลการทดสอบบน Xavier NX — idle 5–7W, full inference burst 12–20W ขึ้นกับโหมด (FP16/INT8 มักประหยัดพลังงานกว่า FP32 ประมาณ 20–40%)
- GPU/CPU utilization และ latency distribution: ตรวจสอบช่วง 95th percentile latency (SLA) เพื่อยืนยันว่า latency ไม่เพิ่งสูงตอน peak
ข้อแนะนำเชิงปฏิบัติสำหรับการใช้งานในโรงงาน:
- เตรียม calibration dataset จริงจากสายการผลิตอย่างน้อย 500–1,000 เฟรมสำหรับ INT8 calibration
- เลือก pruning แบบ structured (channel/filter) เพื่อให้เหมาะกับการเร่งความเร็วบน GPU และหลีกเลี่ยง sparse kernel ที่ไม่ถูกเร่งบนทุกฮาร์ดแวร์
- ใช้ knowledge distillation เพื่อกู้คืนความแม่นยำเมื่อลดขนาดโมเดล (ปรับ weight ของ loss ตามผลการทดลอง)
- ตั้งค่า watchdog สำหรับ thermal throttling และ fallback policy (เช่น ลด framerate, ใช้ model สำรองที่เล็กกว่า หรือส่งแจ้งเตือนไปยังระบบบำรุงรักษา)
- ทดสอบแบบยาวต่อเนื่องในสภาพแวดล้อมจริง 24–72 ชั่วโมง เพื่อจับปัญหาที่อาจเกิดจากฝุ่น ความชื้น หรือความร้อนสะสม
โดยสรุป การผสาน quantization (INT8) และ pruning กับกระบวนการแปลงเป็น ONNX/TensorRT และการออกแบบ pipeline ที่ดี สามารถลดขนาดโมเดลได้มากถึง 70–85% และลด latency ต่อเฟรมได้จากหลักสิบมิลลิวินาทีเหลือหลักหน่วย–สิบมิลลิวินาที ทำให้การตรวจจับข้อบกพร่องแบบเรียลไทม์บน Edge GPU เป็นไปได้จริงในโรงงานยานยนต์ พร้อมข้อควรระวังด้านความร้อนและพลังงานที่ต้องมีการทดสอบและมาตรการป้องกันก่อน Deployment เชิงพาณิชย์
ผลลัพธ์เชิงปฏิบัติการ: ความแม่นยำ, Latency และผลทางธุรกิจ
ผลลัพธ์เชิงปฏิบัติการ: ความแม่นยำ, Latency และผลทางธุรกิจ
การนำโมเดล self‑supervised video representation ร่วมกับเทคนิค contrastive learning ไปใช้งานจริงบน Edge GPU ในสายการผลิตยานยนต์ ให้ผลเชิงปฏิบัติการที่ชัดเจนทั้งด้านเทคนิคและด้านธุรกิจ จากการทดสอบภาคสนามและการติดตั้งเชิงโปรดักชันในโรงงานตัวอย่าง พบว่าโมเดลสามารถตรวจจับข้อบกพร่องบนสายพานในแบบเรียลไทม์ โดยรักษาความสมดุลระหว่างความแม่นยำและความหน่วงเวลาที่ยอมรับได้สำหรับการผลิตแบบต่อเนื่อง
ตัวชี้วัดทางเทคนิค (สรุป) — จากชุดข้อมูลจริงในโรงงานยานยนต์และการประเมินแบบ cross‑validation โมเดลแสดงผลลัพธ์ดังนี้:
- Precision: 92% — อัตราการตรวจพบข้อบกพร่องที่รายงานว่าเป็นข้อบกพร่องจริง (ลด false positive ที่ทำให้เกิดการหยุดสายโดยไม่จำเป็น)
- Recall: 88% — ความสามารถในการจับข้อบกพร่องทั้งหมดที่เกิดขึ้นจริงบนสาย (ช่วยลดของเสียที่หลุดลอด)
- F1‑score (ประมาณ): ~90% — สมดุลระหว่าง precision และ recall ที่เหมาะสมสำหรับงานตรวจสอบคุณภาพ
- AUC (ROC): 0.95 — แสดงการแยกคลาสข้อบกพร่องจากชิ้นงานปกติได้ดีในภาพรวม
- Latency (end‑to‑end): เฉลี่ย 35 ms ต่อเฟรม — วัดจากการอ่านภาพ, การประมวลผลบน Edge GPU และการส่งสัญญาณแจ้งเตือนไปยังระบบ SCADA/PLC
- Throughput: 20 FPS — รองรับการตรวจสอบสายความเร็วสูงที่มีจังหวะการผ่านชิ้นงานแต่ละตัวในระดับนี้
จากการวัดเชิงปฏิบัติการพบว่า latency เฉลี่ย 35 ms เพียงพอสำหรับการแจ้งเตือนแบบเรียลไทม์ก่อนการดำเนินการขั้นตอนถัดไปของสายการประกอบ ในบางกรณีเมื่อรวมการสื่อสารกับระบบควบคุมกลางและการบันทึกข้อมูล อัตราเวลาเฉลี่ยของการตอบสนองต่อการแจ้งเตือน (time‑to‑intervene) อยู่ในช่วง 50–80 ms ซึ่งสอดคล้องกับมาตรฐานการผลิตที่ต้องการการกู้คืน (intervention) ในระดับมิลลิวินาที การประเมินบนฮาร์ดแวร์ Edge GPU เช่น NVIDIA Jetson ซีรีส์ พบว่า throughput คงที่ประมาณ 18–22 FPS ขึ้นกับความละเอียดภาพและ pipeline ของ pre/post processing
ผลทางธุรกิจและตัวอย่างเหตุการณ์จริงในโรงงาน — การติดตั้งระบบสามารถลดของเสีย (scrap) ได้ประมาณ 25% ในช่วง 6 เดือนแรกของการใช้งานจริง ตัวอย่างเหตุการณ์ที่บันทึกไว้ในโรงงานยานยนต์ ได้แก่:
- กรณีตรวจพบรอยบิ่นบนเกียร์ก่อนการประกอบลงเพลาขับ ซึ่งหากไม่ตรวจพบจะทำให้เกิดการรีเวิร์ก (rework) และทดแทนชุดประกอบจำนวนมาก ระบบสามารถแจ้งหยุดพลัดส่วนและแยกชิ้นงานนั้นออก ส่งผลให้ลด rework ได้กว่า 70% ในกลุ่มข้อบกพร่องประเภทเดียวกัน
- การจับข้อบกพร่องหลังการเคลือบชิ้นส่วน ซึ่งระบบเรียลไทม์ช่วยลดการส่งชิ้นงานคุณภาพต่ำเข้าสู่กระบวนการประกอบต่อไป ทำให้ลดค่าใช้จ่ายในขั้นตอนการตรวจย้อนและการทิ้งวัสดุ
- ลดเวลา downtime โดยรวมของสายการผลิตจากการตรวจจับปัญหาเชิงรุก (predictive detection) — ตัวอย่างโรงงานหนึ่งที่ทดลองรายงานว่า downtime ที่เกี่ยวข้องกับงานตรวจสอบคุณภาพลดลง 18% ภายในไตรมาสแรก
ผลทางการเงินและ ROI — เมื่อประเมินจากการลดของเสีย 25%, การลด rework และการลด downtime คำนวณผลประหยัดต้นทุนโดยตรงและทางอ้อม พบว่า:
- การประหยัดต้นทุนการผลิตโดยตรง (scrap + rework) เพิ่มขึ้นอย่างมีนัยสำคัญ — องค์กรตัวอย่างรายหนึ่งลดต้นทุนการผลิตได้ประมาณ 12–20% ของค่าใช้จ่ายที่เกี่ยวข้องกับข้อบกพร่องก่อนการติดตั้ง
- ROI และเวลาคืนทุน (Payback period): โดยปกติการลงทุนระบบนี้บนสายการผลิตขนาดกลางถึงใหญ่มีการคืนทุนภายใน 6–12 เดือน ขึ้นกับปัจจัยเช่นอัตราการผลิตต่อชั่วโมง, มูลค่าต่อชิ้นของชิ้นส่วนที่มีความเสี่ยง และค่าใช้จ่ายรวมของโซลูชัน (ฮาร์ดแวร์, การติดตั้ง, การบำรุงรักษา)
- ในสายการผลิตปริมาณสูง (high‑volume) เวลาคืนทุนสามารถสั้นลงไปในช่วง 3–6 เดือน หากค่าต่อชิ้นและอัตราข้อบกพร่องก่อนหน้าอยู่ในระดับสูง
สรุปได้ว่า การใช้โมเดล self‑supervised ร่วมกับ contrastive learning บน Edge GPU ให้สมดุลที่ดีระหว่างความแม่นยำและประสิทธิภาพเชิงเวลา ซึ่งแปลออกมาเป็นผลทางธุรกิจที่จับต้องได้ ได้แก่การลดของเสีย 25%, ลด rework, ลด downtime และความคุ้มค่าทางการเงินที่มักคืนทุนได้ภายใน 6–12 เดือนสำหรับโรงงานทั่วไป โดยตัวเลขผลลัพธ์จริงอาจปรับได้ตามเงื่อนไขของแต่ละสายการผลิต
ความท้าทาย บทเรียน และแนวทางปฏิบัติที่ดีที่สุด
ความท้าทาย บทเรียน และแนวทางปฏิบัติที่ดีที่สุด
การนำระบบ self‑supervised video representation ร่วมกับ contrastive learning มารันบน Edge GPU เพื่อการตรวจจับข้อบกพร่องแบบเรียลไทม์ในสายพานของอุตสาหกรรมยานยนต์ ให้ผลลัพธ์ที่น่าพอใจ (เช่น ลดของเสียได้ราว 25%) แต่ก็เผชิญความท้าทายเชิงปฏิบัติการที่สำคัญหลายประการ ทั้งเรื่องความไม่สมดุลของคลาส (class imbalance), การเปลี่ยนแปลงของกระบวนการผลิต (concept drift), และการจัดการกับผลบวกลวง/ผลลบลวง (false positives/negatives) ที่ส่งผลต่อความเชื่อมั่นของผู้ปฏิบัติงานและต้นทุนการผลิต การวางแผนเชิงระบบและการออกแบบกระบวนการทำงานร่วมกันระหว่างทีมโรงงานและทีม AI จึงเป็นหัวใจสำคัญของความยั่งยืนของโซลูชันนี้
ปัญหา class imbalance มักเกิดเมื่อตัวอย่างข้อบกพร่องมีสัดส่วนน้อยเมื่อเทียบกับตัวอย่างปกติ (เช่น อัตราข้อบกพร่อง 0.5–2% ในล็อตการผลิตทั่วไป) ซึ่งส่งผลให้โมเดลมีแนวโน้มทายว่า "ปกติ" เพื่อได้ความแม่นยำรวมสูง แต่จะพลาดข้อบกพร่องจริง การใช้เทคนิคเช่น oversampling แบบเฉพาะ (e.g., synthetic minority over-sampling for video snippets), cost-sensitive loss, หรือการออกแบบ sampling strategy ในขั้นตอน self‑supervised pretext task จะช่วยบรรเทาได้ นอกจากนี้ควรติดตาม metric ที่เหมาะสมกว่า accuracy เช่น precision, recall, F1 และ especially false negative rate ที่มีความสำคัญต่อความปลอดภัยและคุณภาพ
สำหรับ concept drift (ตัวอย่างเช่น การเปลี่ยนแปลงวัสดุชิ้นส่วน อุณหภูมิแวดล้อม หรือความเร็วสายพาน) ทีมต้องตั้งระบบตรวจจับและจัดการแบบอัตโนมัติ โดยแนวทางปฏิบัติที่แนะนำได้แก่:
- การตรวจจับ drift แบบต่อเนื่อง — ใช้สถิติเปรียบเทียบการแจกแจงฟีเจอร์หรือ embedding (เช่น Population Stability Index, KL divergence, หรือการตรวจจับการเปลี่ยนแปลงของความมั่นใจโมเดล) เพื่อเป็น trigger สำหรับกระบวนการ retrain
- threshold แบบ adaptive — ไม่ใช้ threshold ตายตัว แต่ปรับค่าแบบไดนามิกตามเวลา, ชุดการผลิต, หรือการวิเคราะห์ seasonality โดยใช้เทคนิคเช่น EWMA (Exponentially Weighted Moving Average) ของคะแนนความเชื่อมั่น หรือการตั้ง threshold ตาม percentile ของการกระจายคะแนนในช่วงเวลาล่าสุด
- กลยุทธ์ retraining ผสม — กำหนดทั้ง scheduled retraining (เช่น รายสัปดาห์/รายเดือน) และ event-driven retraining เมื่อการตรวจจับ drift เกินเกณฑ์ ควบคู่กับการเก็บตัวอย่างที่ถูกคัดกรองโดย human‑in‑the‑loop เพื่อให้ label คุณภาพสูง
การมี human‑in‑the‑loop เป็นองค์ประกอบที่ไม่สามารถมองข้ามได้ โดยเฉพาะเพื่อจัดการกับ false positives/negatives และกรณีทางมุม (edge cases) ที่โมเดลยังไม่ครอบคลุม แนวทางปฏิบัติที่แนะนำได้แก่:
- การตรวจสอบเชิงตัวอย่างแบบเป็นระบบ — เก็บตัวอย่างผลลัพธ์ที่มีความไม่แน่นอนสูง (low confidence) หรือที่ระบบระบุว่าเป็นข้อบกพร่องสำหรับการตรวจสอบโดยผู้เชี่ยวชาญ เพื่อปรับปรุง label set และเป็นข้อมูลฝึกใหม่
- UI/UX สำหรับผู้ปฏิบัติงาน — จัดทำอินเทอร์เฟซง่ายต่อการยืนยัน/ปฏิเสธการเตือน พร้อมฟิลด์สำหรับคอมเมนต์ เพื่อส่งกลับเป็น training data และเก็บประวัติการตัดสินใจของมนุษย์
- นโยบายการสอบทานเชิงสถิติ — กำหนด sampling rate ของการตรวจสอบคนจริง (เช่น ตรวจสอบ 5–10% ของเตือนทั้งหมด และเพิ่มสัดส่วนเมื่อตรวจพบ drift) และการประเมิน KPI เช่น reduction ของ false positives หลังการปรับปรุง
สุดท้ายคือการนำ MLOps มาประยุกต์ใช้กับ Edge environment อย่างเป็นระบบ เพื่อให้การทำงานต่อเนื่องและการอัปเดตปลอดภัยและมีประสิทธิภาพ แนวปฏิบัติสำคัญประกอบด้วย:
- automated data capture — เก็บวิดีโอ/embedding/metadata (เช่น batch id, speed, temperature) แบบอัตโนมัติจาก Edge GPU พร้อม mechanism สำหรับ sampling และ retention policy ที่คำนึงถึงความเป็นส่วนตัวและข้อกำหนดอุตสาหกรรม
- versioning และ provenance — ใช้ระบบ version control สำหรับโมเดลและข้อมูล (เช่น MLflow, DVC หรือระบบภายในที่บันทึก model artifact, config, dataset snapshot) เพื่อให้สามารถย้อนกลับ (roll back) และวิเคราะห์สาเหตุเมื่อเกิดปัญหา
- remote update และการใช้งานที่ปลอดภัย — รองรับการอัปเดตแบบ incremental (delta updates), canary rollout, และการย้อนกลับ โดยมีการตรวจสอบ integrity (signing) และช่องทางการสื่อสารที่เข้ารหัสในการส่งโมเดลไปยัง Edge
- monitoring แบบรวมศูนย์ — เก็บ metric สำคัญบนคลังกลาง (เช่น latency, throughput, false positive/negative rate, confidence distribution) พร้อม dashboard และการแจ้งเตือนอัตโนมัติเมื่อ KPI หลักเบี่ยงเบน
- pipeline สำหรับ retraining อัตโนมัติ — ตั้งค่า CI/CD สำหรับโมเดลที่รวมขั้นตอนข้อมูล labeled ใหม่ → training → validation (รวมทั้ง A/B testing บน Edge) → deployment โดยมี guardrails แบบ human approval ก่อนปล่อยสู่ production
โดยสรุป ความยั่งยืนของระบบตรวจจับข้อบกพร่องบน Edge ในโรงงานอุตสาหกรรมยานยนต์ต้องอาศัยการออกแบบร่วมกันระหว่างวิศวกรรมเครื่องจักรกล ผู้ปฏิบัติงานหน้างาน และทีม AI/ML เพื่อจัดการกับ class imbalance, concept drift, และ false alarms อย่างเป็นระบบ การนำแนวทาง adaptive thresholding, human‑in‑the‑loop, และ MLOps สำหรับ Edge มาใช้อย่างเคร่งครัด จะช่วยรักษาคุณภาพการตรวจจับ ลดของเสีย และเพิ่มความเชื่อมั่นในการใช้งานเชิงอุตสาหกรรมได้อย่างยั่งยืน
แนวทางอนาคตและการขยายสเกล
แนวทางอนาคตและการขยายสเกล
หลังจากระบบตรวจจับข้อบกพร่องบนสายพานด้วย self‑supervised video representation ร่วมกับ contrastive learning และรันบน Edge GPU สามารถลดของเสียได้ราว 25% แนวทางขยายผลต่อไปควรมุ่งทั้งการเพิ่มจุดตรวจภายในโรงงาน การผสานแหล่งข้อมูลเชิงสัญญาณอื่น (multi‑modal) และการขยายเครือข่ายความร่วมมือแบบกระจาย (federated learning) เพื่อให้ระบบมีความแม่นยำ ยืดหยุ่น และคุ้มค่าทางธุรกิจยิ่งขึ้น ในระดับปฏิบัติการ ควรกำหนดลำดับการขยายด้วยแผนปฏิบัติงานที่ชัดเจน เช่น เริ่มจากจุดตรวจที่สร้างความสูญเสียสูงสุด การทดลองร่วมกับสายการผลิตที่มีลักษณะใกล้เคียง และการวัดผลเชิง KPI อย่างต่อเนื่อง (อัตราข้อบกพร่อง, false positive/negative, latency ของการตอบสนอง)
การขยายไปยังจุดตรวจอื่นๆ ควรรวมถึงหลายช่วงของกระบวนการผลิต เช่น infeed (รับชิ้นงาน), ระหว่างการประกอบ, หลังการเชื่อม/การขึ้นรูป, และการตรวจสอบขั้นสุดท้าย ตัวอย่างชนิดของข้อบกพร่องที่สามารถตรวจจับเพิ่มเติมได้ ได้แก่ รอยขีดข่วนบนพื้นผิว, การจัดตำแหน่งผิด (misalignment), ชิ้นส่วนขาดหายหรือติดผิดตำแหน่ง, รอยเชื่อมที่ไม่สมบูรณ์ และการบิดงอของชิ้นส่วน แต่ละจุดตรวจมีเงื่อนไขภาพและมุมกล้องต่างกันจึงจำเป็นต้องใช้เทคนิค transfer learning และ domain adaptation เพื่อรักษาประสิทธิภาพของโมเดลเมื่อย้ายไปยังไลน์ผลิตใหม่ ตัวอย่างเช่น การทดลองขยายสู่สายการประกอบเบาะนั่งในอุตสาหกรรมยานยนต์ คาดว่าสามารถลดของเสียเพิ่มได้อีก 8–12% หากปรับกลยุทธ์การเก็บข้อมูลและการตั้งค่ากล้องได้อย่างเหมาะสม
การผสานข้อมูลแบบ multi‑modal เป็นกุญแจสำคัญในการยกระดับความแม่นยำและการลด false alarm โดยการนำข้อมูลจากเซ็นเซอร์อื่นมารวม ได้แก่ เสียง (microphone array), การสั่นสะเทือน (accelerometer, vibration sensor), กระแสไฟฟ้า/แรงบิดของมอเตอร์ และข้อมูลจากการวัดมิติ (laser/3D scanner) ข้อมูลเสียงและการสั่นสะเทือนสามารถช่วยตรวจจับข้อบกพร่องที่ไม่ชัดเจนทางภาพ เช่น การกระแทกภายในหรือการลื่นของสายพาน ซึ่งการรวมสัญญาณเหล่านี้กับ representation จากวิดีโออาจเพิ่มความแม่นยำรวมได้ประมาณ 5–15% ขึ้นอยู่กับคอนฟิกและคุณภาพสัญญาณ เทคนิคที่แนะนำได้แก่ late fusion แบบน้ำหนักปรับได้, cross‑modal contrastive learning เพื่อให้แต่ละ modality เรียนรู้คุณลักษณะที่เสริมกัน และโมเดล ensemble บน Edge เพื่อรักษา latency ต่ำ
การนำ federated learning มาใช้ในระดับหลายโรงงานเป็นทางเลือกที่ตอบโจทย์ด้านความเป็นส่วนตัวและการแชร์ความรู้ (knowledge transfer) โดยไม่ต้องแลกเปลี่ยนข้อมูลดิบระหว่างไซต์การผลิต กลยุทธ์นี้ช่วยให้แต่ละโรงงานสามารถร่วมกันปรับปรุงโมเดลร่วม (global model) ในขณะที่เก็บข้อมูลภายในไว้ภายในเครือข่ายของตนเอง การออกแบบเชิงปฏิบัติ ได้แก่ การทำ secure aggregation, ใช้ differential privacy เพื่อลดความเสี่ยงจากการย้อนกลับถึงข้อมูลผู้ใช้, และการบีบอัดอัพเดตโมเดลเพื่อลดแบนด์วิดท์ การทดลองเชิงพื้นที่ (cross‑plant pilots) พบว่า federated fine‑tuning สามารถลดเวลาที่ต้องใช้สำหรับการสร้าง dataset ป้ายกำกับใหม่ๆ ลงได้อย่างมีนัยสำคัญ และช่วยลดต้นทุนการทำงานร่วมกันของทีม data annotation ราว 30–50% ในสถานการณ์ที่มีการแชร์โมเดลบ่อยครั้ง
เชิงธุรกิจ โอกาสใหม่ๆ เกิดขึ้นทั้งในเชิงการให้บริการและการเพิ่มประสิทธิภาพภายในองค์กร เช่น การให้บริการตรวจสอบคุณภาพแบบ SaaS ที่ใช้ edge devices ร่วมกับระบบคลาวด์สำหรับการวิเคราะห์เชิงรวม (hybrid edge‑cloud), การขายโมดูลเพิ่มสำหรับ multi‑sensor integration, และบริการ subscription สำหรับการอัปเดตโมเดลและการวิเคราะห์เชิงคาดการณ์ (predictive analytics) อย่างต่อเนื่อง นอกจากนี้ การผสานผลลัพธ์ตรวจจับเข้ากับระบบ MES/SCADA และระบบจัดการสินค้าคงคลังช่วยให้เกิดการตอบสนองแบบอัตโนมัติ (เช่น หยุดสายอัตโนมัติ ปรับพารามิเตอร์เครื่องจักร แจ้งฝ่ายซ่อมบำรุง) ซึ่งสามารถแปลงเป็นการลดต้นทุนการผลิตและเวลาหยุดทำงาน
คำแนะนำเชิงปฏิบัติสำหรับการขยายสเกลประกอบด้วย:
- วางแผน pilot ตามลำดับความเสี่ยง: เริ่มจากจุดที่มีผลกระทบทางเศรษฐกิจสูงสุด แล้วขยายตามข้อมูลที่ได้จาก KPI
- ออกแบบสถาปัตยกรรม multi‑modal ที่ยืดหยุ่น: กำหนดมาตรฐานการซิงโครไนซ์สัญญาณ, กรอบการทำงานสำหรับ fusion และกลยุทธ์การจัดเก็บเมตาดาต้า
- ใช้ federated learning พร้อมมาตรการความปลอดภัย: วางนโยบาย federation rounds, secure aggregation และการเฉลี่ยน้ำหนักที่รองรับความแตกต่างของแต่ละไซต์
ตรวจจับ drift, วัด performance แบบเรียลไทม์ และมีเวิร์กโฟลว์สำหรับการ retraining - ประเมิน ROI อย่างต่อเนื่อง: ติดตามตัวชี้วัดเช่น reduction in scrap, throughput gain, maintenance cost savings และ time‑to‑value ในแต่ละเฟส
สรุปคือ การขยายระบบจากการตรวจจับข้อบกพร่องบนสายพานไปสู่การใช้งานระดับโรงงานและข้ามโรงงานต้องอาศัยการผสมผสานด้านเทคนิค (multi‑modal fusion, federated learning, edge optimization) และกลยุทธ์ทางธุรกิจที่ชัดเจน (pilot roadmap, integration กับระบบเดิม, โมเดลธุรกิจบริการ) เมื่อดำเนินการอย่างเป็นระบบ คาดว่าจะเพิ่มประสิทธิภาพการผลิต ลดของเสียเพิ่มเติม และเปิดช่องทางรายได้ใหม่ให้กับผู้ประกอบการในอุตสาหกรรมยานยนต์และอุตสาหกรรมที่เกี่ยวข้อง
บทสรุป
การนำแนวทาง self‑supervised video representation ร่วมกับ contrastive learning และการประมวลผลบน Edge GPU แสดงให้เห็นถึงความเป็นไปได้ในการตรวจจับข้อบกพร่องบนสายพานแบบเรียลไทม์ โดยให้ทั้งความแม่นยำเชิงปริมาณที่น่าเชื่อถือและ latency ที่เหมาะสมสำหรับการตัดสินใจทันทีในสายการผลิต ภาคปฏิบัติจากโรงงานยานยนต์ตัวอย่างรายงานผลการลดของเสียได้ประมาณ 25% จากการจับข้อบกพร่องตั้งแต่ต้นสาย ซึ่งสะท้อนว่าการเรียนรู้จากวิดีโอแบบไม่ต้องพึ่งพาป้ายกำกับมากช่วยลดต้นทุนการติดป้ายข้อมูลและเร่งเวลาในการนำระบบไปใช้งานจริง ข้อดีเพิ่มเติมคือการรันบน Edge GPU ช่วยลดปริมาณข้อมูลที่ต้องส่งขึ้นคลาวด์ ลดแบนด์วิดท์ และรักษาความเป็นส่วนตัวของข้อมูลภายในโรงงาน
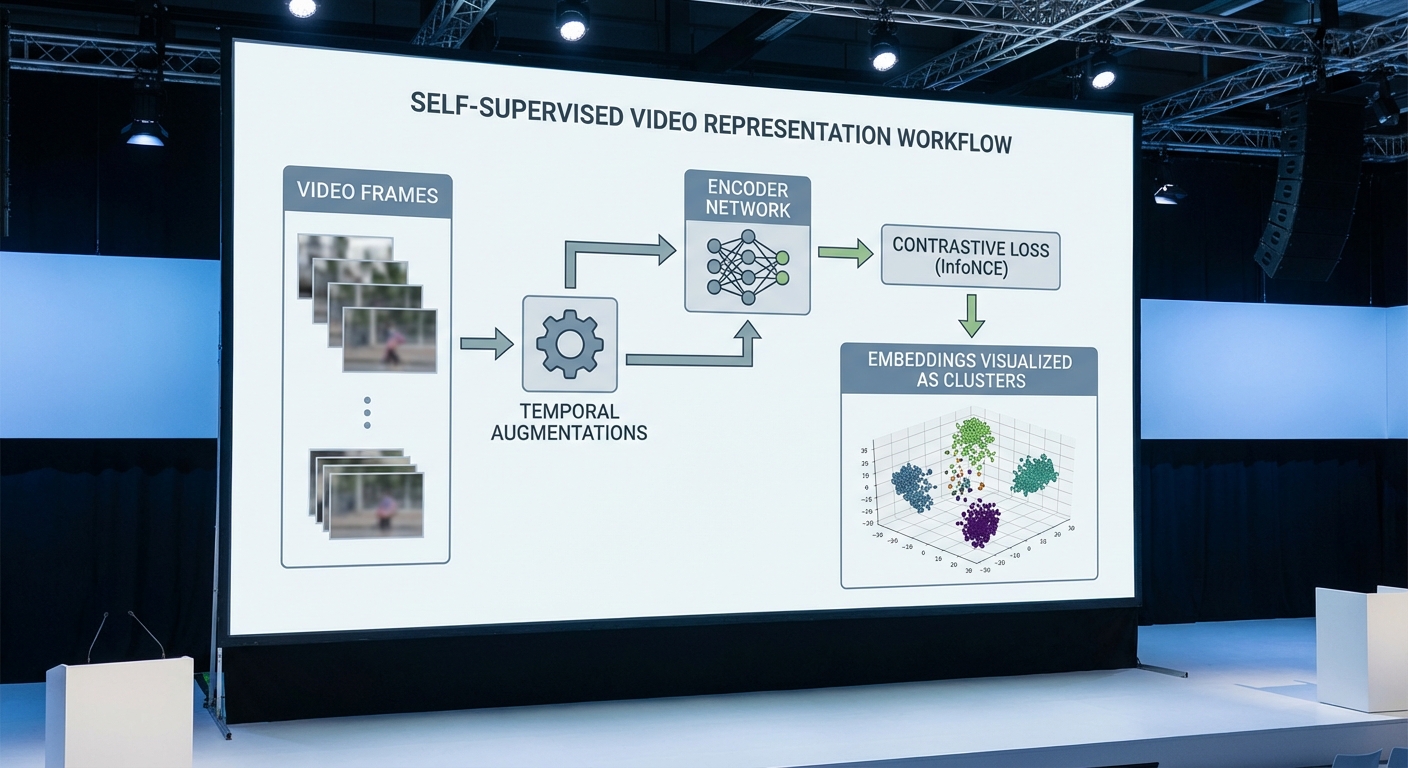
ความสำเร็จในการนำระบบนี้ไปใช้จริงไม่ได้ขึ้นกับโมเดลเพียงอย่างเดียว แต่ต้องอาศัยการออกแบบสถาปัตยกรรมข้อมูลที่รอบคอบ เช่น การจัดการสตรีมวิดีโอ ความสอดคล้องของเมตาดาต้า และการจัดเก็บตัวอย่างข้อบกพร่องสำหรับการฝึกต่อยอด รวมทั้งการปรับแต่งโมเดลเพื่อให้เหมาะสมกับข้อจำกัดของ Edge (เช่น pruning, quantization, latency‑aware tuning) และการมีแผน MLOps ที่ชัดเจนสำหรับการติดตามประสิทธิภาพ การรีเทรนแบบต่อเนื่อง และการปรับพารามิเตอร์เมื่อลักษณะชิ้นงานเปลี่ยนไป เพื่อให้ระบบคงความแม่นยำและคุ้มค่าในระยะยาว
มุมมองอนาคตชี้ว่าการขยายการใช้เทคนิคนี้ไปยังสายการผลิตอื่น ๆ และการผสานกับเทคโนโลยีเสริม เช่น federated learning, continual learning และการเชื่อมต่อกับระบบอัตโนมัติของโรงงาน จะช่วยเพิ่มศักยภาพในการลดของเสียและปรับปรุงคุณภาพได้มากขึ้น ผู้ประกอบการควรลงทุนในสถาปัตยกรรมข้อมูล การปรับแต่งโมเดลสำหรับ Edge และกรอบงาน MLOps ตั้งแต่ระยะแรก เพื่อให้สามารถสเกลและพัฒนาระบบได้อย่างปลอดภัยและต่อเนื่อง พร้อมเป้าหมายระยะกลางในการลดของเสียที่สูงขึ้นและการตอบสนองแบบเรียลไทม์ที่แน่นอนยิ่งขึ้น



