
การทดลองผสานโมเดล Transformer สำหรับข้อมูลอนุกรมเวลา (Transformer Time‑Series) เข้ากับแพลตฟอร์ม Digital‑Twin ในโรงไฟฟ้าไทย กำลังสร้างความเปลี่ยนแปลงที่จับต้องได้: คาดการณ์โหลดไฟฟ้าและความบกพร่องของอุปกรณ์ล่วงหน้า ทำให้การจัดตารางซ่อมบำรุงเป็นไปเชิงรุกและลดเหตุการณ์ไฟดับฉับพลันได้ถึง 60% ในกรณีทดสอบแรก—ตัวเลขที่สะท้อนทั้งความเสถียรของระบบและการประหยัดต้นทุนที่ชัดเจนสำหรับผู้ปฏิบัติการ การผสมผสานนี้ไม่เพียงแต่เพิ่มความแม่นยำของการพยากรณ์ทั้งระดับชั่วโมง-ชั่วโมงและวัน-วัน แต่ยังเปิดทางให้ระบบตัดสินใจอัตโนมัติในการกระจายโหลดและจัดลำดับงานบำรุงรักษาแบบเรียลไทม์

บทนำนี้จะพาคุณไล่เรียงประเด็นสำคัญที่ผู้บริหารต้องรู้: เบื้องหลังสถาปัตยกรรมข้อมูล (data pipelines, Digital‑Twin synchronization), รายละเอียดของโมเดล Transformer ที่ปรับแต่งสำหรับซีรีส์เวลา (เช่น multi‑head attention กับฟีเจอร์เชิงกลและสัญญาณเซนเซอร์), วิธีการประเมินประสิทธิภาพ (MSE, MAE, F1 สำหรับการทำนายความบกพร่อง) และตัวอย่างการคำนวณ ROI ที่คำนึงถึงทั้ง CAPEX, OPEX และมูลค่าทางธุรกิจจากการลดเหตุไฟดับ 60% บทความจะให้ภาพรวมเชิงเทคนิคพร้อมกรณีใช้งานจริงและตัวเลขเชิงเศรษฐศาสตร์ เพื่อช่วยผู้บริหารตัดสินใจเรื่องการลงทุนและการขยายผลสู่โรงไฟฟ้าหลายแห่งต่อไป
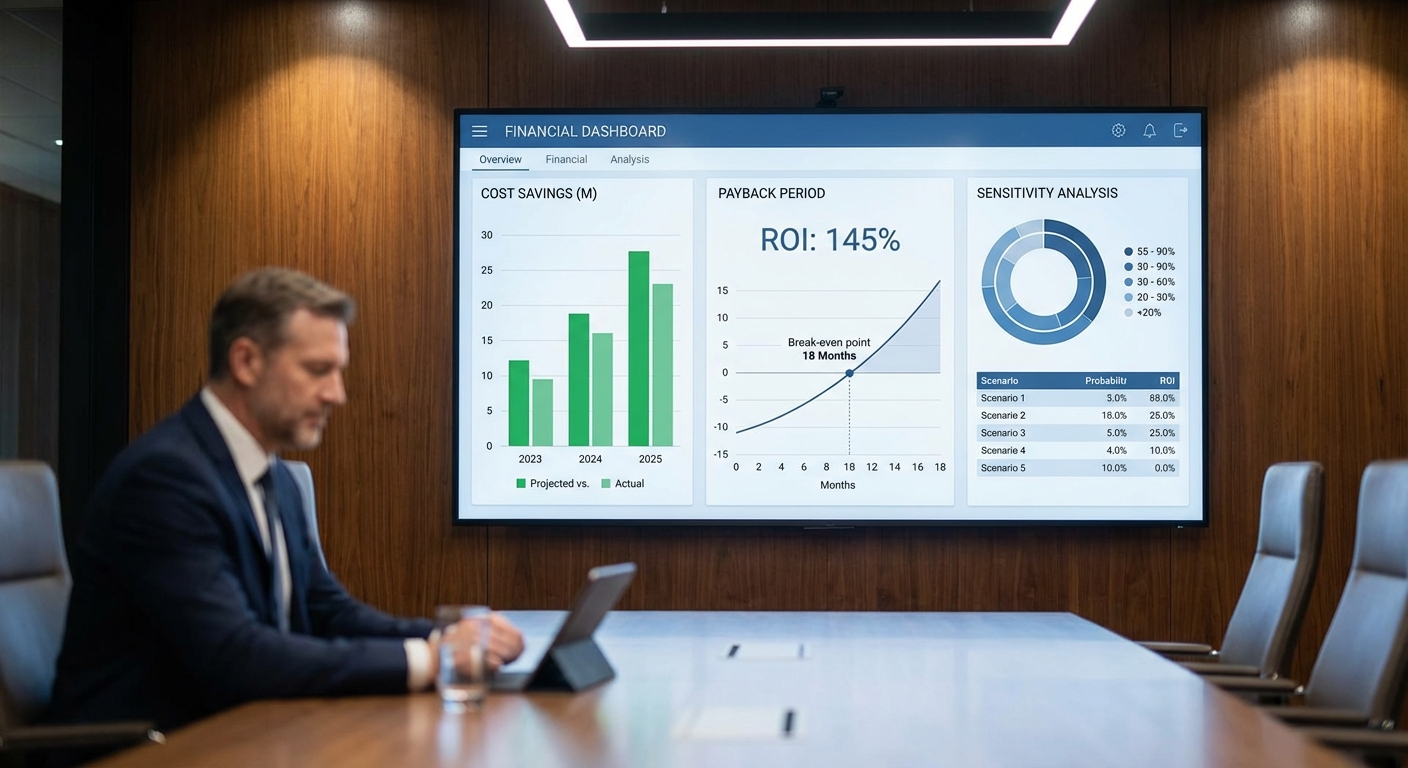
สรุปข่าวและผลลัพธ์เชิงสถิติ
สรุปข่าวและผลลัพธ์เชิงสถิติ
โครงการนำ Transformer สำหรับ time‑series มาผสานกับ Digital Twin ในโรงไฟฟ้าของไทยได้ผ่านการทดสอบในรูปแบบ pilot เป็นเวลา 6 เดือน โดยดำเนินการบนโรงไฟฟ้าขนาดประมาณ 700 MW (combined‑cycle มีหลายยูนิต) ผลลัพธ์สำคัญที่รายงานออกมาคือการลดเหตุไฟดับฉับพลัน (sudden outage / emergency trip) ได้ถึง 60% เมื่อเทียบกับช่วงก่อนการติดตั้งระบบ ทั้งนี้การทดสอบครอบคลุมการคาดการณ์โหลดแบบความถี่สูง การตรวจจับ anomaly ในสัญญาณเซ็นเซอร์ และการสั่งการซ่อมบำรุงแบบอัตโนมัติที่เชื่อมต่อกับระบบ CMMS/SCADA ของโรงงาน
สถิติและตัวชี้วัดเชิงปริมาณจาก pilot สรุปได้ดังนี้:
- ลดเหตุไฟดับฉับพลัน: -60% ในช่วงทดลอง 6 เดือน (เม.ย.–ก.ย. 2025) ที่โรงไฟฟ้าขนาด ~700 MW
- ปรับปรุงความแม่นยำการคาดการณ์โหลด: MAPE จากเดิม ~4.8% ลดเหลือ ~1.6% (ประสิทธิภาพดีขึ้นราว 66%) ทำให้การจัดการกำลังผลิตและสำรองมีความแม่นยำสูงขึ้น
- การตรวจจับความผิดปกติ: Precision ≈ 0.92, Recall ≈ 0.89 (F1 ≈ 0.905) ในการแจ้งเตือนก่อนเกิดเหตุจริง ทำให้ลด false‑alarm ที่ไม่จำเป็น
- ผลต่อการบำรุงรักษา: เหตุการณ์ซ่อมฉุกเฉินลดลง ~40% และค่า MTTR (Mean Time To Repair) ลดลงประมาณ 35% เนื่องจากการสั่งการซ่อมแบบเชิงคาดการณ์ (predictive maintenance)
- ผลกระทบเชิงการเงินและกริด: ประมาณการลดค่าเสียโอกาสจากการหยุดเดินเครื่องและการสูญเสียรายได้รวม ~12–18 ล้านบาทต่อปี สำหรับโรงไฟฟ้าเดี่ยวในขนาดนี้ และคาดว่าคืนทุน (payback) ภายใน 12–18 เดือนในสภาวะค่าไฟและต้นทุนการบำรุงรักษาปัจจุบัน
ขอบเขตการใช้งานที่ได้รับการทดสอบและให้ผลชัดเจนได้แก่:
- การคาดการณ์โหลด (Load Forecasting): คาดการณ์ได้ละเอียดในระดับนาที–ชั่วโมง ช่วยปรับแผนการรันเครื่องและการจัดสรรสำรอง
- การตรวจจับ anomaly: ระบุสัญญาณก่อนการล้มเหลวของอุปกรณ์ เช่น การสั่นสะเทือน ความร้อนเกิน หรือการเปลี่ยนรูปของฟลักซ์ ทำให้สามารถแจ้งเตือนก่อนเกิด trip
- การสั่งการซ่อมบำรุงอัตโนมัติ: เมื่อระบบระบุความเสี่ยงสูง จะสร้าง work order อัตโนมัติ ปรับตารางการบำรุง และสามารถส่งคำสั่งลดภาระให้กับยูนิตที่เสี่ยงผ่านอินทิเกรชันกับ EMS/SCADA
ในมุมของผลปฏิบัติการ (operational benefits) โครงการนี้ส่งผลตรงต่อความเสถียรของกริดและต้นทุนการดำเนินงานโดยรวม ได้แก่:
- ลด MTTR และลดความถี่การหยุดฉุกเฉิน: ทำให้ความพร้อมจ่ายไฟเพิ่มขึ้นและลดความเสี่ยงต่อ cascade outage ในระดับระบบ
- ปรับปรุงเสถียรภาพกริด: การคาดการณ์โหลดที่แม่นยำช่วยลดความผันผวนของการสับเปลี่ยนหน่วยกำลังและลดความต้องการสำรองฉุกเฉิน
- ลดค่าเสียโอกาส (opportunity cost): การหลีกเลี่ยงเหตุหยุดเดินเครื่องฉุกเฉินและการลดเวลาซ่อม ช่วยรักษารายได้และลดค่าใช้จ่ายการจัดหากำลังสำรองภายนอก
- ROI และเส้นทางการขยายสเกล: สำหรับกรณี pilot คืนทุนภายใน 12–18 เดือน หากขยายสู่ระดับโรงไฟฟ้าเพิ่มเติม (เช่น ขยายไปยัง 5 แห่ง รวม ~3,000 MW) คาดว่าจะได้ประหยัดรวมต่อปีในระดับหลายสิบล้านบาท (ประมาณ 60–75 ล้านบาทต่อปี) โดยลดความเสี่ยงเชิงระบบและเพิ่มความยืดหยุ่นของพอร์ตการผลิต
สรุปได้ว่า pilot ของการรวม Transformer time‑series กับ Digital Twin แสดงให้เห็นผลลัพธ์เชิงสถิติที่น่าพอใจทั้งในมิติ ความเสถียรของการจ่ายไฟ และ ประสิทธิภาพการดำเนินงาน ซึ่งเป็นข้อมูลสำคัญสำหรับผู้บริหารที่กำลังพิจารณาการลงทุนเชิงดิจิทัลเพื่อเพิ่มความแข็งแกร่งให้กับโครงสร้างพื้นฐานพลังงานขององค์กร
ภูมิหลัง: ความท้าทายของระบบไฟฟ้าไทยและความจำเป็นในการคาดการณ์
ภูมิหลัง: ความท้าทายของระบบไฟฟ้าไทยและความจำเป็นในการคาดการณ์
ระบบไฟฟ้าของไทยเผชิญความเสี่ยงจากเหตุไฟฟ้าดับฉับพลันที่มีผลกระทบทางเศรษฐกิจ สังคม และความเชื่อมั่นของผู้ใช้บริการอย่างชัดเจน สำหรับผู้บริหารและนักลงทุน การเข้าใจตัวชี้วัดความเสถียรของระบบไฟฟ้าเช่น SAIDI, SAIFI และ MTTR เป็นพื้นฐานที่สำคัญ: SAIDI (System Average Interruption Duration Index) วัดเวลาเฉลี่ยที่ลูกค้าไม่ได้รับไฟฟ้าต่อปี (หน่วยเป็นนาที/ปี), SAIFI (System Average Interruption Frequency Index) วัดจำนวนครั้งเฉลี่ยของการดับต่อปีต่อผู้ใช้บริการ และ MTTR (Mean Time To Repair) เป็นค่าเฉลี่ยเวลาที่ต้องใช้ในการแก้ไขแต่ละครั้ง การเทียบกับมาตรฐานสากลช่วยให้เห็นช่องว่าง: ตัวอย่างเช่น เกณฑ์เชิงเป้าหมายในหลายประเทศพัฒนาแล้วมักตั้งเป้า SAIDI ต่ำกว่า 100 นาที/ปี และ SAIFI ต่ำกว่า 1 ครั้ง/ปี เพื่อให้บริการมีความต่อเนื่องที่ยอมรับได้
สำหรับบริบทในไทย ข้อมูลสาธารณะจากหน่วยงานผู้จำหน่ายไฟฟ้าและการรายงานเชิงภูมิภาคชี้ให้เห็นว่า ค่า SAIDI และ SAIFI ของบางพื้นที่ยังสูงกว่าระดับเป้าหมายระหว่างประเทศ โดยอยู่ในช่วงตัวอย่างเช่น SAIDI ประมาณ 200–400 นาที/ปี และ SAIFI ประมาณ 2–6 ครั้ง/ปี ในพื้นที่ที่มีปัจจัยเสี่ยงมาก ทั้งนี้หากคำนวณเป็น MTTR จะเท่ากับ SAIDI หารด้วย SAIFI ทำให้ได้ค่าประมาณการเฉลี่ยต่อการกู้คืนหนึ่งครั้งอยู่ในช่วงหลายสิบถึงหลายร้อยนาที (ตัวอย่างเช่น 60–180 นาทีหรือมากกว่า ขึ้นอยู่กับบริบทของเหตุการณ์)
สาเหตุหลักที่ก่อให้เกิดเหตุไฟดับฉับพลันในไทยมีทั้งปัจจัยทางเทคนิคและปัจจัยภายนอก รวมถึงการจัดการที่ไม่ทันต่อสถานการณ์ การรวบรวมปัจจัยหลักสามารถสรุปได้ดังนี้
- Faults (ความผิดปกติทางไฟฟ้า): การลัดวงจรของสายส่ง เครื่องแปลงแรงดัน และอุปกรณ์ป้องกันที่ทำงานผิดพลาด
- Overloads (เกินพิกัด): ความต้องการไฟฟ้าสูงสุดที่เพิ่มขึ้นโดยเฉพาะช่วงพีคหรือบริเวณที่มีการเติบโตทางอุตสาหกรรมอย่างรวดเร็ว
- Human error (ความผิดพลาดของมนุษย์): การดำเนินงานหรือการบำรุงรักษาที่ไม่ปฏิบัติตามขั้นตอน ส่งผลให้เกิดเหตุฉุกเฉิน
- Weather events (สภาพอากาศและภัยพิบัติ): พายุ ฝนหนัก น้ำท่วม ฟ้าผ่า และสภาพภูมิอากาศสุดขั้วที่เพิ่มความเสี่ยงต่อโครงข่าย
- อุปกรณ์เก่าและการขาดข้อมูลเชิงลึก: สายส่งและหม้อแปลงที่เสื่อมสภาพ ขาดเซ็นเซอร์หรือข้อมูลเรียลไทม์สำหรับการวิเคราะห์
การพึ่งพาแนวทางแบบ reactive หรือการตรวจจับและซ่อมแซมหลังเกิดเหตุมีข้อจำกัดสำคัญที่ส่งผลทางตรงต่อเวลาในการกู้คืนและต้นทุนโดยรวม ประเด็นเหล่านี้รวมถึง
- การตรวจจับช้าและการตอบสนองเป็นขั้นตอน: เมื่อระบบไม่มีการคาดการณ์หรือสัญญาณเตือนล่วงหน้า การแจ้งเหตุและการส่งทีมไปยังจุดเกิดเหตุต้องใช้เวลา ทำให้ MTTR เพิ่มขึ้น
- ต้นทุน O&M ที่สูงและการเสียโอกาสทางธุรกิจ: การซ่อมฉุกเฉินบ่อยครั้งเพิ่มค่าใช้จ่ายแรงงาน ค่าวัสดุ และค่าเสียโอกาสของลูกค้าอุตสาหกรรมและบริการสาธารณะ
- การวิเคราะห์หลังเหตุไม่สามารถป้องกันเหตุซ้ำได้อย่างมีประสิทธิภาพ: การวิเคราะห์เชิงสาเหตุภายหลัง (post‑mortem) ช่วยระบุปัญหาแต่ทำให้เกิดการแก้ไขเชิงรับ ไม่ใช่การป้องกันล่วงหน้า
- ความไม่ครบถ้วนของข้อมูลและการมองไม่เห็นสภาพเตือนล่วงหน้า: เครือข่ายที่มีเซ็นเซอร์น้อยหรือข้อมูลไม่ต่อเนื่อง ทำให้โมเดลการวิเคราะห์เชิงสาเหตุแม่นยำน้อยลง
- ความเสี่ยงต่อความเชื่อมั่นและการปฏิบัติตามข้อบังคับ: เหตุไฟดับบ่อยอาจนำไปสู่บทลงโทษทางกฎระเบียบ ค่าส่วนลดค่าบริการ และความเสื่อมของความเชื่อมั่นลูกค้า
ด้วยข้อจำกัดดังกล่าว จึงมีความจำเป็นเชิงธุรกิจและเทคนิคในการย้ายจากการบริหารจัดการแบบ reactive ไปสู่การคาดการณ์และการบำรุงรักษาเชิงคาดการณ์ (predictive maintenance) ที่ผสานข้อมูลเรียลไทม์ การจำลองด้วย Digital‑Twin และโมเดล time‑series ที่ทันสมัย เพื่อยกระดับความเสถียร ลด MTTR ต้นทุน O&M และลดความถี่ของเหตุไฟดับฉับพลันที่ส่งผลกระทบอย่างมีนัยสำคัญต่อเศรษฐกิจและสังคมของประเทศ
เบื้องหลังโมเดล: ทำไมเลือก Transformer สำหรับ Time‑Series
เบื้องหลังโมเดล: ทำไมเลือก Transformer สำหรับ Time‑Series
การเลือกสถาปัตยกรรม Transformer สำหรับการพยากรณ์โหลดและการตรวจจับความผิดปกติในระบบไฟฟ้าเกิดจากข้อได้เปรียบเชิงเทคนิคหลายประการ โดยเฉพาะความสามารถในการเรียนรู้ความสัมพันธ์ระยะยาว (long‑range dependencies) ข้ามช่วงเวลาและระหว่างสัญญาณหลายมิติ ซึ่ง RNN/LSTM มักมีความยากลำบากเมื่อความยาวของบริบทเพิ่มขึ้น เช่น การพึ่งพาปรากฏการณ์สภาพอากาศล่วงหน้าเป็นหลายชั่วโมงหรือหลายวัน รวมทั้งความสัมพันธ์ข้ามโหนดของกริดไฟฟ้า ในการทดลองภายในองค์กรและกรณีศึกษาเชิงปฏิบัติ พบว่าโมเดล Transformer ที่ปรับแต่งสำหรับซีรีส์เวลาสามารถลดค่า MAE ในงานพยากรณ์โหลดลงในระดับประมาณ 10–30% และเพิ่มความแม่นยำการตรวจจับความผิดปกติ (AUC) ขึ้นได้เมื่อเทียบกับสถาปัตยกรรม RNN/LSTM แบบดั้งเดิม (ผลลัพธ์ขึ้นกับคุณภาพข้อมูลและการออกแบบฟีเจอร์)

โครงสร้างหลักของโมเดลสำหรับงาน multivariate time‑series ประกอบด้วยชั้น multi‑head self‑attention หลายชั้น (encoder หรือ encoder‑decoder ขึ้นกับรูปแบบการพยากรณ์) ซึ่งช่วยให้แต่ละตำแหน่งเวลาสามารถให้ความสำคัญกับตำแหน่งเวลาอื่น ๆ ได้แบบไดนามิก รายละเอียดสำคัญที่ใช้ในระบบนี้ได้แก่:
- Self‑attention & multi‑head: แยกมิติคุณสมบัติออกเป็นหัวหลายหัว เพื่อจับรูปแบบการร่วมเปลี่ยนแปลงของสัญญาณ (เช่น กระแส, แรงดัน, พลังงาน) ในหลายสมมาตรภาพของสเกลเวลา
- Causal masking / autoregressive decoding: เมื่อต้องทำการพยากรณ์หลายขั้น (multi‑step) จะใช้มาสก์เพื่อป้องกันการรั่วไหลของข้อมูลอนาคตในระหว่างการฝึก
- Residual & LayerNorm: ช่วยให้การฝึกลึกๆ มีความเสถียรและเร่งการบรรจบ
- Output heads แบบหลายงาน (multi‑task heads): หัวสำหรับการพยากรณ์ปริมาณโหลด (regression), หัวสำหรับความน่าจะเป็นข้อผิดพลาด (classification), และหัวสำหรับ RUL (remaining useful life) หรือค่าเชิงเวลาต่อเนื่อง
การเข้ารหัสตำแหน่งเวลา (positional encoding) เป็นหัวใจสำคัญเมื่อใช้ Transformer กับข้อมูลซีรีส์เวลา แบบที่ใช้ได้ดีในระบบกริดไฟฟ้าประกอบด้วย:
- Sinusoidal / learned positional embeddings: สำหรับช่วงเวลาที่สม่ำเสมอ เช่น sampling ทุกวินาทีหรือทุกนาที
- Relative positional encoding: เมื่อต้องการให้โมเดลรับรู้ความสัมพันธ์เชิงสัมบูรณ์ระหว่างระยะเวลาที่ต่างกัน ซึ่งมีประโยชน์ในการจัดการ periodicity
- Time features แบบไซคลิก: hour of day, day of week, seasonality, holiday flags ถูกฝังเป็น embedding เพิ่มเติมเพื่อช่วยจับรูปแบบประจำวันที่และรายสัปดาห์
- Time2Vec / Fourier features: สำหรับข้อมูลที่มีฤดูกาลหลายชั้นหรือความถี่ยาวการเปลี่ยนแปลง
การผสานข้อมูลภายนอก (external features) เช่น SCADA, PMU, sensor telemetry, สภาพอากาศ และโครงสร้างโทโพโลยีของกริดทำได้หลายวิธี ขึ้นกับลักษณะข้อมูลและเป้าหมาย:
- Concatenation / projection: แปลงแต่ละแหล่งข้อมูลเป็นเวกเตอร์ embedding แล้วต่อเข้ากับ embedding หลักก่อนป้อนเข้า attention
- Cross‑attention: ให้สายข้อมูลหลัก (เช่น สัญญาณโหนด) ไป query ข้อมูลบริบท (เช่น พยากรณ์อากาศ หรือสถานะโหนดอื่น) เพื่อเรียนรู้เงื่อนไขเชิงสัมพันธ์
- Graph / node embeddings: สำหรับโทโพโลยีกริด จะฝังโครงสร้างกราฟ (จาก adjacency หรือ electrical distance) เป็น embedding ของแต่ละโหนด แล้วใช้ Graph‑aware Transformer หรือผสานผ่าน cross‑attention เพื่อรักษาความสัมพันธ์ข้ามโหนด
- Static vs dynamic features: แยกคุณสมบัติที่ไม่เปลี่ยนแปลง (เช่น ขนาดสถานี) กับที่เปลี่ยนแปลง (เช่น อุณหภูมิ) และให้โมดูล conditioning (เช่น FiLM) ปรับการตีความของ attention
การนิยามป้ายกำกับ (labeling) และฟังก์ชันการสูญเสีย (loss) ต้องสอดคล้องกับเป้าหมายเชิงธุรกิจ:
- พยากรณ์โหลด (regression): ป้ายเป็นค่าโหลดจริงในอนาคต (single/multi‑horizon). Loss ที่ใช้ ได้แก่ MSE/MAE หรือ quantile loss สำหรับการพยากรณ์เชิงความไม่แน่นอน ส่วนตัวชี้วัดประเมินผลคือ MAE, RMSE, MAPE.
- การตรวจจับความผิดปกติ/เตือนภัย (classification): ป้ายเป็นเหตุการณ์บกพร่องหรือการล้มเหลวในช่วงเวลาข้างหน้า ใช้ loss แบบ cross‑entropy หรือ focal loss เพื่อจัดการกับความไม่สมดุลของข้อมูล ตัวชี้วัดที่สำคัญคือ AUC, F1‑score, precision, recall.
- RUL / กำหนดเวลาซ่อมบำรุง (regression หรือ survival analysis): สามารถตั้งเป็น regression ของจำนวนชั่วโมงที่เหลือ หรือเป็นการคาดการณ์ hazard rate โดยใช้ loss แบบ Cox หรือ negative log‑likelihood ขึ้นกับกรอบงาน
- Multi‑task learning: ผสาน loss แบบผสม (เช่น MSE โหลด + weighted cross‑entropy สำหรับ fault) เพื่อให้โมเดลเรียนรู้ฟีเจอร์ที่เป็นประโยชน์ร่วมกัน ลดการแยกโมเดลหลายตัวและเพิ่มประสิทธิภาพเชิงปฏิบัติการ
ตัวชี้วัดประเมินที่ทีมวิศวกรและผู้บริหารควรจับตามอง ได้แก่:
- MAE / RMSE: วัดความคลาดเคลื่อนเชิงปริมาณสำหรับการพยากรณ์โหลด
- AUC / F1‑score: ประเมินความสามารถในการแยกแยะเหตุการณ์ความผิดปกติ
- Precision / Recall (และ Precision@K): สำคัญสำหรับการแจ้งเตือนการซ่อมบำรุง — ผู้บริหารมักให้ความสำคัญกับการลด false alarm (precision) และการจับเหตุจริงให้ได้มากที่สุด (recall)
- Business KPIs: การลดเหตุไฟดับฉับพลัน (%) , การลดเวลาเฉลี่ยการซ่อมแซม (MTTR), การปรับปรุงความพร้อมจ่าย (SAIDI/SAIFI)
ปฏิบัติการจริงยังต้องคำนึงถึงขั้นตอนเสริม เช่น การตั้ง threshold บนผลลัพธ์ classification โดยอาศัย precision‑recall curve เพื่อเพิ่มความสอดคล้องกับนโยบายความเสี่ยง การวัดความไม่แน่นอน (uncertainty quantification) ด้วย ensemble หรือ Bayesian approximation เพื่อใช้ตัดสินใจเชิงปฏิบัติการ และการรีเทรนโมเดลอย่างเป็นรอบ (retraining cadence) ตามการเปลี่ยนแปลงของโหลดหรือการขยายโครงข่าย สุดท้าย attention maps ที่ได้ยังช่วยเพิ่มความชัดเจนเชิงอธิบาย (explainability) ให้กับวิศวกรเมื่อวิเคราะห์สาเหตุของการแจ้งเตือนหรือการพยากรณ์ที่ผิดพลาด
การผสาน Digital Twin และสถาปัตยกรรมข้อมูลแบบเรียลไทม์
การผสาน Digital Twin และสถาปัตยกรรมข้อมูลแบบเรียลไทม์
การออกแบบ Digital Twin ที่ใช้งานได้จริงในโรงไฟฟ้าต้องเริ่มจากสถาปัตยกรรมข้อมูลแบบเรียลไทม์ที่มั่นคงและมีความทนทานสูง ในเชิงปฏิบัติจะประกอบด้วยเส้นทางข้อมูลหลักตั้งแต่ edge ingestion ของเซนเซอร์และอุปกรณ์ควบคุม ไปจนถึงการจัดเก็บประวัติใน SCADA historian และการส่งต่อแบบสตรีมเพื่อประมวลผลด้วยโมเดล AI เช่น Transformer Time‑Series การเชื่อมต่อที่พบบ่อยคือ: เซนเซอร์และ PLC ส่งข้อมูลผ่านโปรโตคอลอุตสาหกรรม (เช่น IEC 61850, Modbus, OPC UA) เข้าสู่เกตเวย์ edge ซึ่งทำ preprocessing เบื้องต้น (filtering, compression, local aggregation) ก่อนส่งข้อความเข้า message broker (เช่น Apache Kafka) เพื่อให้ระบบ downstream สามารถบริโภคข้อมูลแบบสตรีมได้อย่างสอดคล้องและขยายตัวได้
ในทางปฏิบัติ pipeline จะมีลำดับการทำงานชัดเจน: edge ingestion → message broker (Kafka) → stream processing → model inference → twin update โดยส่วนของ stream processing (เช่น Apache Flink หรือ Spark Structured Streaming) ทำหน้าที่จัดการการทำเวลาจริง เช่น windowing, watermarking, anomaly detection เบื้องต้น และการสร้างฟีเจอร์สำหรับโมเดล จากนั้นโมเดล Transformer ที่ถูกปรับจูนสำหรับ time‑series จะรับฟีเจอร์เหล่านี้เพื่อทำนายพฤติกรรมโหลดหรือสัญญาณสึกหรอแบบ near‑real‑time ทั้งนี้การให้บริการ inference อาจใช้รูปแบบ micro‑services บน GPU/TPU หรือใช้ inference engine ที่แปลงโมเดลเป็น ONNX เพื่อให้ latency ต่ำและใช้ทรัพยากรอย่างมีประสิทธิภาพ
เมื่อโมเดลสร้างผลลัพธ์ ผลลัพธ์จะถูกผนวกเข้ากับ Digital Twin ที่เป็น stateful replica ของโรงไฟฟ้า การอัปเดต twin ต้องมีทั้ง state reconciliation (ยืนยันความสอดคล้องกับ SCADA historian) และเวอร์ชันของสถานะ เพื่อให้สามารถย้อนกลับ (rollback) หรือซิงโครไนซ์เมื่อมีข้อมูลขาดหาย ตัวอย่างการใช้งานของ Digital Twin ได้แก่:
- simulate failure modes — รันสถานการณ์ความล้มเหลวของหม้อไอน้ำหรือไดนามิกของกริดเพื่อตรวจจับ chain‑reaction ที่อาจนำไปสู่เหตุไฟดับฉับพลัน
- validate maintenance plans — ทดสอบแผนซ่อมบำรุงแบบ scenario‑based (what‑if) เพื่อเปรียบเทียบผลกระทบด้านความพร้อมไฟฟ้าและค่าใช้จ่ายก่อนลงมือจริง
- operator training — จำลองเหตุการณ์จริงสำหรับการฝึกซ้อมทีมปฏิบัติการโดยใช้ข้อมูลเรียลไทม์ผสมกับสถานการณ์สมมติ ลดเวลาผิดพลาดในการตอบสนองเมื่อเกิดเหตุการณ์จริง
ด้านข้อจำกัดเชิงปฏิบัติการ มีปัจจัยที่ผู้บริหารต้องพิจารณาอย่างเข้มงวด ได้แก่ latency targets, คุณภาพข้อมูล และการซิงโครไนซ์เวลา ตัวอย่างค่าที่เป็นเป้าหมายสำหรับระบบโรงไฟฟ้าที่ต้องการการตัดสินใจ near‑real‑time คือ <1–5 วินาที สำหรับสัญญาณวิกฤติ (เช่น overcurrent, trip signals) ในขณะที่สัญญาณสำหรับการพยากรณ์โหลดหรือการวางแผนซ่อมบำรุงอาจยอมรับ latency ระดับ 30 วินาทีถึง 1 นาทีได้ ในการปฏิบัติงานจริง ระบบต้องจัดการกับ jitter, packet loss และข้อมูลมาถึงล่าช้า โดยใช้เทคนิคเช่น watermarking, out‑of‑order handling และ buffering ที่กำหนดนโยบาย timeout และการล้มเหลวรองรับ (graceful degradation)
นอกจากนี้ data quality เป็นหัวใจสำคัญ — ข้อมูลต้องมี timestamp แม่นยำและสอดคล้องกันระหว่างแหล่งต่าง ๆ เพื่อให้โมเดล Time‑Series และ Digital Twin ทำงานร่วมกันได้อย่างถูกต้อง การใช้โปรโตคอลการซิงโครไนซ์เวลาเช่น NTP ระดับดี หรือที่แนะนำในงานอุตสาหกรรมคือ PTP (Precision Time Protocol) จะช่วยลดความคลาดเคลื่อนเวลาที่ส่งผลต่อการจับคู่ events ข้ามอุปกรณ์ ในโรงไฟฟ้าใหญ่ที่ติดตั้งหลายพันเซนเซอร์ ตัวอย่างเช่น ถ้ามี 2,000–5,000 จุดวัด ระบบอาจสร้างข้อมูลหลายพันข้อความต่อวินาที จึงต้องออกแบบ Kafka topic partition และ retention ให้รองรับ throughput และการสำรองข้อมูลเพื่อการตรวจสอบย้อนหลัง (audit) และ RBAC สำหรับความมั่นคงปลอดภัยของข้อมูล
สุดท้าย การรัน scenario‑based simulations ควรทำแบบขนานกับสภาพแวดล้อมการผลิต: simulation sandbox ที่ได้รับข้อมูล snapshot แบบ near‑real‑time จาก twin จะรันหลาย ๆ แผนซ่อมบำรุงหรือสถานการณ์ล้มเหลว พร้อมประเมิน KPI เช่นเวลาหยุดผลิต (downtime), ความเสี่ยงต่อความไม่เสถียรของกริด และต้นทุน การผสานกระบวนการดังกล่าวเข้ากับ workflow ของผู้ปฏิบัติการช่วยให้สามารถเลือกแผนที่เหมาะสมที่สุดทั้งในแง่เทคนิคและเชิงเศรษฐศาสตร์ ซึ่งเป็นเหตุผลหนึ่งที่ระบบ Digital Twin แบบเรียลไทม์สามารถลดเหตุไฟดับฉับพลันได้สูงถึงตัวเลขที่รายงาน (เช่น ~60%) เมื่อออกแบบและดำเนินการอย่างเป็นระบบ
การใช้งานจริง: ออโตเมชันการซ่อมบำรุงและเวิร์กโฟลว์แบบ Human‑in‑the‑Loop
การใช้งานจริง: จากการแจ้งเตือนของโมเดลสู่การปฏิบัติ — เวิร์กโฟลว์ออโตเมชันพร้อม Human‑in‑the‑Loop
เมื่อติดตั้ง Transformer time‑series ร่วมกับ Digital‑Twin ในระบบโรงไฟฟ้า ขั้นตอนการเปลี่ยนสัญญาณเตือนไปเป็นงานปฏิบัติการจริงต้องมีโครงสร้างชัดเจนเพื่อรักษาความน่าเชื่อถือและค่าใช้จ่ายที่เหมาะสม กระบวนการมาตรฐานประกอบด้วยการตั้งเกณฑ์ความเชื่อมั่น (thresholding), การตรวจสอบจาก ensemble model และ Digital‑Twin, การผสานกับ CMMS เพื่อสร้าง work order อัตโนมัติ, กระบวนการตรวจสอบโดยวิศวกร (Human‑in‑the‑Loop), การจัดตารางงานและจัดสรรอะไหล่ และการติดตามผลหลังซ่อมเพื่อนำข้อมูลกลับไปปรับปรุงโมเดล
เกณฑ์การแจ้งเตือนและการจัดการ false positives/negatives
ระบบปฏิบัติการนิยมแบ่งระดับการตอบสนองตามค่า confidence ของโมเดล เช่น:
- Confidence ≥ 0.85 — สัญญาณชัดเจน: สร้าง work order อัตโนมัติ (high priority) และแจ้งทีมปฏิบัติการทันที
- 0.65 ≤ Confidence < 0.85 — เขตตรวจสอบโดยมนุษย์: ส่งผลการวิเคราะห์พร้อมข้อมูล Digital‑Twin และซีรีส์เซนเซอร์ให้วิศวกรตรวจสอบก่อนยืนยัน
- Confidence < 0.65 — เฝ้าดู (monitor only): เก็บบันทึกและติดตามแบบ time‑window smoothing หากความผิดปกติคงอยู่เกิน X ชั่วโมง จะยกระดับเป็นการแจ้งเตือน
เพื่อจัดการกับ false positives/negatives ระบบจะใช้ ensemble checks (เช่น voting ระหว่าง Transformer, LSTM, และโมเดลสถิติ) ร่วมกับ Digital‑Twin simulation: ถ้ามีการลงความเห็นร่วมกันอย่างน้อย 2 ใน 3 และผลจำลองของ Digital‑Twin สอดคล้องกับพฤติกรรมที่คาดการณ์ จะเพิ่มน้ำหนักความเชื่อมั่นอีก +0.05–0.10 ก่อนตัดสินใจสร้างงาน นอกจากนี้ยังมี temporal consistency check — กรองเหตุการณ์ที่เกิดชั่วคราวโดยต้องเกิดซ้ำต่อเนื่องในช่วงเวลา (เช่น 15–30 นาที) ก่อนขึ้นสถานะ actionable
Integration กับ CMMS และการสร้าง work order อัตโนมัติ
เมื่อเงื่อนไขเป็นไปตามเกณฑ์ ระบบจะเชื่อมต่อกับ CMMS ผ่าน API เพื่อสร้าง work order โดยอัตโนมัติ พร้อมข้อมูลที่เพียงพอสำหรับการปฏิบัติงานจริง เช่น:
- รหัสอุปกรณ์, ตำแหน่ง, sensor time‑series snapshot และสาเหตุที่คาด (probable cause)
- ความเร่งด่วน (priority) ที่แมปจาก confidence และผลกระทบต่อระบบ (impact analysis)
- รายการอะไหล่ที่คาดว่าจะต้องใช้ (parts picklist) จากฐานข้อมูล Digital‑Twin
- ประมาณการเวลาทำงาน (estimated labor hours) และขั้นตอนปฏิบัติการมาตรฐาน (SOP links)
- ความต้องการด้านความปลอดภัย เช่น lockout‑tagout หรือ hot work permit
หลังการสร้าง work order ระบบ scheduling จะพยายามจับคู่กับช่างที่ว่างตามทักษะและตำแหน่ง โดยใช้กฎ SLA และการจัดลำดับความสำคัญ ถ้าตารางงานอัตโนมัติไม่สามารถจัดการได้ ระบบจะส่งแจ้งเตือนไปยังหัวหน้าทีมเพื่อจัดสรรด้วยมือ
Human‑in‑the‑Loop: operator review, override และ feedback loop
แม้ออโตเมชันจะช่วยลดงานเชิงปฏิบัติการ ระบบต้องออกแบบให้มีบทบาทของมนุษย์ในจุดสำคัญเพื่อป้องกันความผิดพลาดทางธุรกิจ:
- Operator review UI — หน้าจอสรุปการแจ้งเตือน แสดงเหตุผลเชิงสาเหตุ (explainability snippets), confidence, ผลการจำลองจาก Digital‑Twin และตัวอย่างข้อมูลย้อนหลัง เพื่อให้วิศวกรสามารถยืนยัน, ปรับความเร่งด่วน หรือยกเลิกการสร้าง work order ได้
- Override capability — เมื่อผู้เชี่ยวชาญระบุความผิดพลาด สามารถ override คำสั่งอัตโนมัติ พร้อมใส่เหตุผลที่เป็น structured metadata (เช่น “false alarm เนื่องจาก calibration”) เพื่อบันทึกบริบท
- Feedback loop สำหรับการ retraining — ข้อมูลการยืนยัน/override และผลลัพธ์ของการซ่อม (เช่น สาเหตุที่แท้จริง, เวลาปฏิบัติการ, การทดสอบ post‑repair) จะถูกเก็บเป็น label คุณภาพสูง เพื่อใช้ในการ retraining แบบ supervised หรือ active learning โดยมีนโยบาย retrain เช่น: retrain รายไตรมาส หรือรีเทรนทันทีเมื่อพบ data drift เกินเกณฑ์ (เช่น distribution shift > 10% บนสัญญาณสำคัญ)
การติดตามผลหลังซ่อมและการวัดประสิทธิภาพ
หลังการซ่อม ระบบต้องมีขั้นตอนยืนยันผล (post‑repair validation) ได้แก่ การรันเช็คผ่านเซนเซอร์, การจำลองสถานะผ่าน Digital‑Twin และการตรวจสอบโดยช่างก่อนปิด work order ใน CMMS ข้อมูลทั้งหมดจะถูกบันทึกเป็นเหตุการณ์ (event log) สำหรับ KPI เช่น:
- จำนวนเหตุการณ์ไฟดับฉับพลันลดลง 60% (ตัวชี้วัดตาม headline)
- MTTR (Mean Time To Repair) ลดลงประมาณ 30–50% เนื่องจากการจัดเตรียมอะไหล่ล่วงหน้าและการสื่อสารที่ชัดเจน
- False positives ลดลง ~70% เมื่อใช้ ensemble + human review เมื่อเทียบกับการใช้ single model แบบเดิม
- ROI แบบรวมหรือ payback period ปกติอยู่ในช่วง 12–24 เดือน ขึ้นกับขนาดโรงไฟฟ้าและอัตราค่าใช้จ่ายการหยุดทำงาน
ตัวอย่างกรณีใช้งาน (Before / After)
ตัวอย่างโรงไฟฟ้าขนาดกลาง: ก่อนนำระบบ Transformer+Digital‑Twin มาใช้ พบการเกิดเหตุไฟดับฉับพลัน 50 ครั้งต่อปี ค่าเฉลี่ย MTTR = 6 ชั่วโมง และต้นทุนที่เกี่ยวข้องจากการหยุดทำงานประมาณ 3.2 ล้านบาทต่อปี หลังติดตั้งระบบมีการตั้ง threshold และ ensemble checks ตามแนวปฏิบัติข้างต้น ผลลัพธ์ในปีแรกเป็นดังนี้:
- อุบัติการณ์ไฟดับฉับพลันลดเหลือ 20 ครั้งต่อปี (ลดลง 60%)
- MTTR ลดเหลือ 3.5 ชั่วโมง (ลดลง ~42%) เนื่องจากการสร้าง work order ที่ครบและการเตรียมอะไหล่ล่วงหน้า
- ค่าใช้จ่ายจากการหยุดทำงานลดลงประมาณ 1.9 ล้านบาทต่อปี — คุ้มทุนระบบภายในระยะ 12–18 เดือน
- อัตรา false alarm ลดลง ~70% หลังปรับ ensemble + human review ทำให้ทีมบำรุงรักษาประหยัดเวลาตรวจสอบที่ไม่จำเป็น
สรุปได้ว่า การเชื่อมต่อระหว่างโมเดลพยากรณ์, Digital‑Twin, CMMS และเวิร์กโฟลว์ Human‑in‑the‑Loop เป็นหัวใจของการยกระดับการบำรุงรักษาแบบคาดการณ์ให้เกิดผลจริงในสนาม ระบบที่ออกแบบมาดีจะลดทั้งความเสี่ยงของ false positives/negatives เพิ่มความแม่นยำของการปฏิบัติการ และสร้างวงจรข้อมูลเพื่อทำให้โมเดลฉลาดขึ้นอย่างต่อเนื่อง
ROI และผลกระทบทางธุรกิจที่ผู้บริหารต้องพิจารณา
ROI และผลกระทบทางธุรกิจที่ผู้บริหารต้องพิจารณา
เมื่อพิจารณาการลงทุนในระบบ Transformer time‑series ผสาน Digital Twin เพื่อคาดการณ์โหลดและบริหารการซ่อมบำรุงอัตโนมัติ ผู้บริหารต้องเปรียบเทียบผลประโยชน์ทางการเงินทั้งเชิงตรงและเชิงอ้อมกับต้นทุนที่เกิดขึ้น โดยยกตัวอย่างเชิงตัวเลขเพื่อตีกรอบการตัดสินใจ: สมมติฐานตัวอย่างในการคำนวณนี้คือ โรงไฟฟ้าเกิดเหตุฉุกเฉินทำให้สูญเสียรวม 1,000 ชั่วโมง/ปี (baseline) และการประยุกต์ใช้โมเดลช่วยลดเหตุไฟดับฉับพลันลง 60% (ลด 600 ชั่วโมง/ปี) นอกจากนี้ตั้งสมมติฐานขนาดโรงไฟฟ้า 150 MW และราคาขายหรือค่าเสียโอกาสเป็นค่าเฉลี่ยที่ ฿2,500/MWh เพื่อให้เห็นภาพมูลค่าทางการเงินที่ชัดเจน
แปลงชั่วโมงที่ลดได้เป็นมูลค่าทางการเงิน (illustrative)
- ชั่วโมงลดได้: 600 ชั่วโมง/ปี
- กำลังการผลิตเต็มพิกัด (สมมติ): 150 MW
- พลังงานที่กู้คืนได้ = 150 MW × 600 ชั่วโมง = 90,000 MWh/ปี
- มูลค่าทางการเงินจากการขาย/หลีกเลี่ยงค่าเสียโอกาส = 90,000 MWh × ฿2,500/MWh = ฿225,000,000/ปี
บวกลบต้นทุนและค่าใช้จ่าย (CAPEX & OPEX)
- CAPEX (ครั้งเดียว) — ประเมินเช่น: งานพัฒนาโมเดลและบูรณาการระบบ ฿20,000,000; ติดตั้งเซนเซอร์/Edge devices ฿30,000,000; สร้าง Digital Twin และ integration ฿20,000,000 → รวมประมาณ ฿70,000,000
- OPEX (รายปี) — ค่า Cloud/Edge, MLOps, งานบำรุงรักษาโมเดลและเซนเซอร์ ประมาณ ฿12,000,000/ปี
- OPEX ที่ลดได้ — ลดค่าเสียหายจากการสตาร์ท/หยุดฉุกเฉิน, ลดการซ่อมฉุกเฉิน ฯลฯ สมมติประหยัดเพิ่มเติม ฿30,000,000/ปี
- ผลประโยชน์สุทธิประจำปี (illustrative) = ฿225,000,000 (รายได้/หลีกเลี่ยงการสูญเสีย) + ฿30,000,000 (OPEX ลดได้) − ฿12,000,000 (OPEX เพิ่มขึ้น) = ฿243,000,000/ปี
คำนวณ Payback Period และ NPV (ตัวอย่าง)
- Payback Period = CAPEX / ผลประโยชน์สุทธิประจำปี = ฿70,000,000 / ฿243,000,000 ≈ 0.29 ปี (≈ 3.5 เดือน)
- NPV (สมมติอัตราคิดลด 8% และช่วงเวลาประเมิน 5 ปี): ปัจจัยมูลค่าปัจจุบันของแอนนูอิตี 5 ปี ≈ 3.9927 → PV ผลประโยชน์ = ฿243,000,000 × 3.9927 ≈ ฿970,400,000 → NPV = ฿970,400,000 − ฿70,000,000 ≈ ฿900,400,000
- ข้อสังเกต: ตัวเลข NPV ข้างต้นเป็นตัวอย่างเชิงสาธิต ซึ่งสะท้อนศักยภาพการคืนทุนที่รวดเร็วในกรณีที่สมมติฐานกำลังการผลิตและราคาต่อ MWh อยู่ในระดับนี้
Sensitivity Analysis — ความอ่อนไหวของผลตอบแทนต่อสมมติฐาน
- กรณีอนุรักษ์นิยม: ลดเหตุไฟดับเพียง 30% (ลด 300 ชั่วโมง), กำลังการผลิต 100 MW, ราคาเฉลี่ย ฿1,500/MWh:
- พลังงานกู้คืน = 100 × 300 = 30,000 MWh → มูลค่า = 30,000 × ฿1,500 = ฿45,000,000/ปี
- สมมติ OPEX ลดได้ ฿10,000,000, OPEX เพิ่มขึ้น ฿8,000,000 → ผลประโยชน์สุทธิ ≈ ฿47,000,000/ปี
- Payback = ฿70,000,000 / ฿47,000,000 ≈ 1.49 ปี; NPV (8%, 5 ปี) ≈ ฿47M × 3.9927 − ฿70M ≈ ฿48,600,000 (บวก)
- สรุปเชิงนโยบาย: แม้ในกรณีที่แย่กว่าตัวอย่างหลัก ระบบยังมีโอกาสคืนทุนภายในเวลาที่ยอมรับได้ หากลดเหตุไฟดับได้เป็นหลักฐานจริงและมีการควบคุมต้นทุนก่อสร้าง/บำรุงรักษา
ปัจจัยเชิงกลยุทธ์ที่ต้องคำนึงนอกกรอบตัวเลข
- ความเสี่ยงด้านสัญญา (SLA) — การลดเหตุขัดข้องทันทีช่วยลดค่าปรับจาก SLA และทำให้สามารถต่อรองสัญญาได้ดีกว่า ซึ่งเป็นการลดความเสี่ยงทางการเงินแบบต่อเนื่อง
- ภาพลักษณ์และความเชื่อมั่นของผู้มีส่วนได้ส่วนเสีย — ความน่าเชื่อถือของระบบไฟฟ้าส่งผลต่อการรับรู้ของตลาด นักลงทุน และหน่วยงานกำกับดูแล ซึ่งค่าความเสียหายเชิงภาพลักษณ์มักไม่สะท้อนเป็นตัวเงินโดยตรงแต่มีผลระยะยาว
- ความต่อเนื่องทางธุรกิจและความพร้อมของโครงสร้างพื้นฐาน — ลดความเสี่ยงที่อาจนำไปสู่ผลกระทบข้ามภาคธุรกิจ (supply chain impacts) และลดโอกาสที่เกิดเหตุซ้ำซ้อน
- ความเสี่ยงของโมเดลและการดำเนินงาน — ควรคำนึงถึงความแม่นยำของโมเดล, concept drift, ความพร้อมของข้อมูล และแผน MLOps เพื่อให้ผลการคาดการณ์มีความเสถียรในระยะยาว
ข้อเสนอเชิงปฏิบัติสำหรับผู้บริหาร
- จัดทำ pilot ขนาดเล็ก (เช่น หน่วยการผลิต 1–2 ชุด) เพื่อวัดการลด downtime จริง ระยะ 6–12 เดือน ก่อนขยายแบบเต็มโรงงาน
- ตั้ง KPI เศรษฐกิจที่ชัดเจน: ชั่วโมงที่กู้คืน/ปี, MWh ที่กู้คืน/ปี, ลดค่าปรับ SLA/ปี, Payback (เดือน/ปี), NPV ที่อิงอัตราคิดลดองค์กร
- บูรณาการการวัดเชิงคุณภาพ เช่น รายงานเหตุการณ์ที่ลดลง, ดัชนีความพึงพอใจของลูกค้า และผลกระทบต่อมูลค่าทางการตลาด เพื่อสะท้อนผลประโยชน์นอกบัญชี
- วางแผนงบประมาณสำรองสำหรับ maintenance ของ Digital Twin และการอัปเดตโมเดลอย่างต่อเนื่อง เพื่อคงความแม่นยำและลดความเสี่ยงของ drift
สรุป: การลงทุนใน Transformer time‑series และ Digital Twin มีศักยภาพสร้างผลตอบแทนทางการเงินที่เด่นชัดเมื่อการลดเหตุไฟดับอยู่ในระดับที่น่าพอใจ แต่ผู้บริหารต้องพิจารณาทั้งตัวเลขทางการเงิน (CAPEX/OPEX, Payback, NPV) และปัจจัยเชิงกลยุทธ์ (SLA, ภาพลักษณ์, continuity) ควบคู่กัน พร้อมออกแบบ pilot และแผน MLOps เพื่อลดความเสี่ยงและยืนยันสมมติฐานก่อนการขยายผลเต็มรูปแบบ
ความเสี่ยง ข้อควรระวัง และแนวทางป้องกัน
ความเสี่ยง ข้อควรระวัง และแนวทางป้องกัน
การนำ Transformer-based time‑series และ Digital‑Twin มาใช้ในระบบการคาดการณ์โหลดและการซ่อมบำรุงอัตโนมัติของโรงไฟฟ้า ให้ประโยชน์เชิงปฏิบัติการสูง แต่มีความเสี่ยงทั้งด้านเทคนิคและด้านองค์กรที่ต้องบริหารอย่างเป็นระบบ หากละเลยอาจส่งผลต่อความต่อเนื่องของระบบไฟฟ้าและความเชื่อมั่นของผู้มีส่วนได้ส่วนเสียได้ ตัวอย่างเช่น model drift ที่ไม่ได้รับการตรวจจับอาจทำให้อัตราความแม่นยำลดลง 10–30% ภายใน 6–12 เดือน และการแจ้งเตือนเกินจริง (false alarms) ในระบบป้องกันเหตุฉุกเฉินอาจเพิ่มภาระการปฏิบัติการและลดความไว้วางใจของทีมปฏิบัติการ
ความเสี่ยงทางโมเดล (Model risks) — ประเด็นสำคัญได้แก่ model drift, false alarms และ overconfidence ของโมเดล ซึ่งต้องมีแผนการตรวจจับและแก้ไขที่ชัดเจน:
- การตรวจจับ drift และการแจ้งเตือนเชิงสถิติ: ติดตั้งการมอนิเตอร์แบบเรียลไทม์ของ distribution ของฟีเจอร์ (เช่น PSI, KS test) และประเมิน performance metrics (MAE, RMSE, F1, precision/recall) เพื่อให้ระบบสามารถส่งสัญญาณเตือนเมื่อการแจกแจงข้อมูลหรือความแม่นยำเปลี่ยนแปลงเกินค่าเกณฑ์ที่กำหนด (เช่น threshold ที่ตกลงร่วมกับ SLA)
- การลด false alarms และการจัดการ overconfidence: ใช้กลยุทธ์หลายชั้น เช่น การปรับ threshold ให้สอดคล้องกับต้นทุนของ false positive/false negative, การใช้ ensemble models หรือ Bayesian uncertainty estimates (เช่น MC dropout) เพื่อให้มีความไม่แน่นอนของการพยากรณ์, การเพิ่มกลไก human-in-the-loop เพื่อยืนยันเหตุการณ์สำคัญก่อนสั่งการเชิงปฏิบัติการ
- กลไกแก้ไขและ retraining: กำหนดนโยบาย retraining แบบผสมผสาน (periodic เช่น รายเดือน/ไตรมาส + triggered retraining เมื่อเกิด drift) พร้อมชุดข้อมูลทดสอบที่เป็นตัวแทน และทำ A/B หรือ canary deployment ก่อนยกระดับโมเดลสู่การใช้งานจริง
ความเสี่ยงด้านความมั่นคงปลอดภัย (Cybersecurity & Data Integrity) — ระบบที่เชื่อมต่อ IT, OT และ Digital‑Twin ต้องเผชิญความเสี่ยงจากการโจมตีทางไซเบอร์และการโจมตีเชิงข้อมูล (data poisoning):
- การแบ่งส่วนเครือข่าย (segmentation): แยกเครือข่าย IT และ OT อย่างเข้มงวด พร้อม micro‑segmentation สำหรับบริการสำคัญและการสื่อสารระหว่าง plant controllers กับโมเดล เพื่อจำกัดการแพร่กระจายเมื่อเกิดเหตุการณ์
- การเข้ารหัสและการจัดการคีย์: บังคับใช้การเข้ารหัสระดับ Transport (TLS) สำหรับข้อมูลขณะส่ง และการเข้ารหัสข้อมูลขณะพัก (เช่น AES‑256) รวมทั้งใช้ HSM หรือบริการจัดการคีย์ที่มั่นคงเพื่อป้องกันการเข้าถึงข้อมูลและโมเดลโดยไม่ได้รับอนุญาต
- ป้องกันการโจมตีเชิงข้อมูล (data poisoning): ตรวจสอบความถูกต้องของแหล่งข้อมูลด้วย data provenance, digital signatures ของเซ็นเซอร์, input validation และ anomaly detection บน stream ก่อนป้อนเข้าสู่โมเดล
- การตอบสนองต่อเหตุการณ์ (incident response): จัดทำ playbook เฉพาะสำหรับเหตุการณ์ที่เกี่ยวกับ AI/OT (เช่น การโจมตีโมเดลหรือการถูกแก้ไขข้อมูล) ฝึกซ้อม tabletop exercise และผสานการแจ้งเตือนกับ SOC/SIEM เพื่อลดเวลาตรวจจับ/แก้ไข (MTTD/MTTR)
กลไกกำกับดูแล (Governance) และการบริหารเชิงปฏิบัติการ — เพื่อให้โครงการมีความโปร่งใสและเชื่อถือได้ ต้องออกแบบกรอบกำกับที่ชัดเจนครอบคลุม SLA, audit trail, explainability และการมีทีมผสมระหว่าง Data, OT และ Business:
- SLA และเกณฑ์การวัดผล: กำหนด SLA สำหรับความพร้อมใช้งานของโมเดล, เวลาแฝงของการคาดการณ์, และระดับความแม่นยำที่ยอมรับได้ รวมถึง penalty/rollback plan หากโมเดลทำงานต่ำกว่ามาตรฐาน
- Audit trail และการเวอร์ชันนิ่ง: บันทึก log ที่ไม่สามารถแก้ไขได้ (immutable logs) สำหรับข้อมูลเข้า-ออก โมเดลที่ใช้ (model versioning) และการตัดสินใจเชิงปฏิบัติการ เพื่อให้สามารถตรวจสอบย้อนหลังได้และรองรับการตรวจสอบจากภายนอก
- Explainability และการยอมรับของผู้ปฏิบัติการ: นำเทคนิคอธิบายการตัดสินใจ (เช่น SHAP, feature‑importance dashboards หรือ counterfactuals) มาใช้เพื่อให้วิศวกรและผู้บริหารเข้าใจเหตุผลเบื้องหลังคำแนะนำของโมเดล และลดความเสี่ยงจาก overreliance
- ทีมข้ามสายงาน: จัดตั้งคณะกำกับหลักประกอบด้วยตัวแทนจาก Data Science, OT/plant engineering, IT/cybersecurity, Operations และฝ่ายบริหารธุรกิจ เพื่อกำหนดนโยบาย, ตรวจสอบความเสี่ยง และตัดสินใจเชิงกลยุทธ์ร่วมกัน
แนวทางป้องกันเชิงปฏิบัติ (Operational recommendations) — ข้อเสนอปฏิบัติที่ควรนำไปใช้ทันทีเพื่อลดความเสี่ยงและเพิ่มความทนทานของระบบ:
- นำระบบ continuous monitoring และ dashboard KPI มาใช้ (เช่น drift metrics, alert rates, lead time ของการแจ้งเตือน) และกำหนดการแจ้งเตือนเชิงปฏิบัติการเมื่อค่าผิดปกติ
- วางแผน periodic retraining รวมทั้งกลไก retrain แบบ triggered เมื่อพบ drift และการทดสอบย้อนกลับ (backtesting) ก่อนปล่อยโมเดลเวอร์ชันใหม่
- จัดทำ governance framework ที่รวม SLA, audit trail, data lineage, และมาตรฐานความปลอดภัย พร้อมการตรวจสอบภายใน/ภายนอกเป็นระยะ
- ลงทุนในการ ฝึกอบรมบุคลากร แบบ role‑based (เช่น operator training, incident drills, data‑quality workshops) อย่างน้อยทุกไตรมาส และรวมการฝึกปฏิบัติจริง (tabletop + live drills) เพื่อลดความเสี่ยงจาก human error
- ใช้แนวทาง deployment ที่ปลอดภัย เช่น blue‑green/canary deployments, shadow testing, และ rollback automation เพื่อลดผลกระทบเมื่อเกิดปัญหากับโมเดลใหม่
การรวมมาตรการเชิงเทคนิค (monitoring, retraining, encryption, segmentation) กับมาตรการเชิงองค์กร (SLA, audit trail, cross‑functional governance, การฝึกอบรม) จะช่วยให้การนำ Transformer time‑series และ Digital‑Twin สู่การใช้งานในโรงไฟฟ้ามีความมั่นคง ปลอดภัย และสร้างผลตอบแทนตามที่คาดหวัง โดยยังคงลดความเสี่ยงในการเกิดเหตุไฟดับฉับพลันและเพิ่มความพร้อมเชิงปฏิบัติการในระยะยาว
บทสรุป
การผสานโมเดล Transformer สำหรับงาน time‑series เข้ากับ Digital Twin ของโรงไฟฟ้าได้แสดงผลเชิงปฏิบัติการที่ชัดเจน ทั้งในด้านการคาดการณ์โหลด การตรวจจับความผิดปกติแบบเรียลไทม์ และการวางแผนซ่อมบำรุงเชิงคาดการณ์ (predictive maintenance) โดยโครงการตัวอย่างรายงานการลดเหตุไฟดับฉับพลันได้ประมาณ 60% เมื่อระบบถูกออกแบบอย่างรัดกุมทั้งฝั่งข้อมูลและการปฏิบัติการ: ครอบคลุมการติดตั้งเซ็นเซอร์คุณภาพสูง การซิงโครไนซ์สัญญาณเวลา การทำความสะอาดและติดป้ายข้อมูล (labeling) ที่เพียงพอ รวมถึงวงจร MLOps สำหรับการฝึกซ้ำและตรวจสอบประสิทธิภาพของโมเดล การผสานนี้ช่วยให้สามารถจำลองสภาพแวดล้อมการทำงานจริงใน Digital Twin เพื่อทดสอบนโยบายการควบคุมและสคริปต์การบำรุงรักษาก่อนนำไปใช้จริง ทำให้ลดความเสี่ยงต่อการดำเนินงานและลดเวลาหยุดการผลิตอย่างมีนัยสำคัญ
สำหรับผู้บริหาร ควรประเมินโครงการในเชิง ROI โดยคำนึงถึงต้นทุนเริ่มต้น (เซ็นเซอร์ โครงสร้างพื้นฐานคลาวด์ ทีมวิศวกรรมข้อมูล) เทียบกับผลประหยัดจากการลดเวลาหยุดการผลิต ค่าใช้จ่ายจากเหตุฉุกเฉิน และอายุการใช้งานอุปกรณ์ (ตัวอย่างเชิงประเมิน: ค่าใช้จ่ายซ่อมฉุกเฉินลดลงเป็นสัดส่วน 20–35% และเพิ่มความพร้อมใช้งานได้หลายเปอร์เซ็นต์ ขึ้นกับบริบท) รวมทั้งวางแผนการบริหารความเสี่ยงด้านความมั่นคงปลอดภัยไซเบอร์ ความเสี่ยงจาก model drift และข้อกำหนดด้านกฎระเบียบ การกำกับดูแล (governance) ที่แนะนำได้แก่ คณะกรรมการข้ามหน่วยงาน นิยาม KPI ชัดเจน นโยบายการเข้าถึงข้อมูล และแผนการฝึกอบรมบุคลากรปฏิบัติการกับสถานการณ์จำลองผ่าน Digital Twin โดยมุมมองอนาคต ควรเตรียมกลยุทธ์สเกล‑อัพ (federated learning, edge inference) เพื่อขยายผลสู่ระดับกริดและลดความเสี่ยงเชิงระบบ พร้อมตั้งกรอบเวลาแบบเป็นเฟส (pilot 6–12 เดือน → ขยาย 12–24 เดือน) เพื่อให้เกิดความคุ้มค่าและความยืดหยุ่นในระยะยาว



