
LabBench‑AI เป็นกรณีศึกษาที่น่าจับตามองของสตาร์ทอัพไทยที่ผสานเครื่องมือเชิงคำนวณและระบบหุ่นยนต์ในห้องปฏิบัติการอย่างเป็นระบบ — โดยการรวมแนวทาง Active‑Learning, หุ่นยนต์จัดของเหลว (liquid‑handling robots) และ Bayesian Optimization ส่งผลให้รอบการทดลองยา (experimental cycles) ถูกย่นเหลือเพียงประมาณ 1/5 ของกระบวนการดั้งเดิม ในเคสจริงจากห้องปฏิบัติการสถาบันวิจัยของไทย รายงานระบุว่าจำนวนการทดลองตัวอย่างลดจากราว 100 เคสเหลือประมาณ 20 เคส ทำให้เวลาที่ต้องใช้ในการคัดกรองสารนำไปทดสอบลดจากหลายเดือนเหลือเพียงไม่กี่สัปดาห์ — ผลลัพธ์ที่ไม่เพียงแต่เพิ่มความรวดเร็ว แต่ยังช่วยลดต้นทุนสารเคมีและแรงงานอย่างมีนัยสำคัญ
บทนำนี้ชี้ให้เห็นประเด็นสำคัญที่บทความจะขยายความ ได้แก่ สถาปัตยกรรมระบบการทำงานของ LabBench‑AI (data pipeline, model loop, และการควบคุมหุ่นยนต์), บทบาทของ Active‑Learning ในการเลือกตัวอย่างที่ให้ข้อมูลมากที่สุด, วิธีที่ Bayesian Optimization ปรับพารามิเตอร์การทดลองเพื่อเพิ่มอัตราค้นพบ และการนำหุ่นยนต์จัดของเหลวมาลดความแปรปรวนเชิงปฏิบัติการ รวมถึงผลลัพธ์เชิงปริมาณและข้อควรระวังเชิงปฏิบัติ เช่น คุณภาพข้อมูล วิกฤตการคาลิเบรตหุ่นยนต์ การถ่ายโอนโมเดลจาก in silico สู่ wet‑lab และข้อจำกัดเชิงกฎระเบียบ บทความนี้จะสรุปทั้งตัวอย่างเชิงตัวเลข ผลการวัดในพื้นที่จริง และแนวปฏิบัติที่ควรระวังเพื่อให้ผู้อ่านเข้าใจภาพรวมการประยุกต์ใช้ AI ในการเร่งการค้นคว้ายาอย่างครบถ้วน
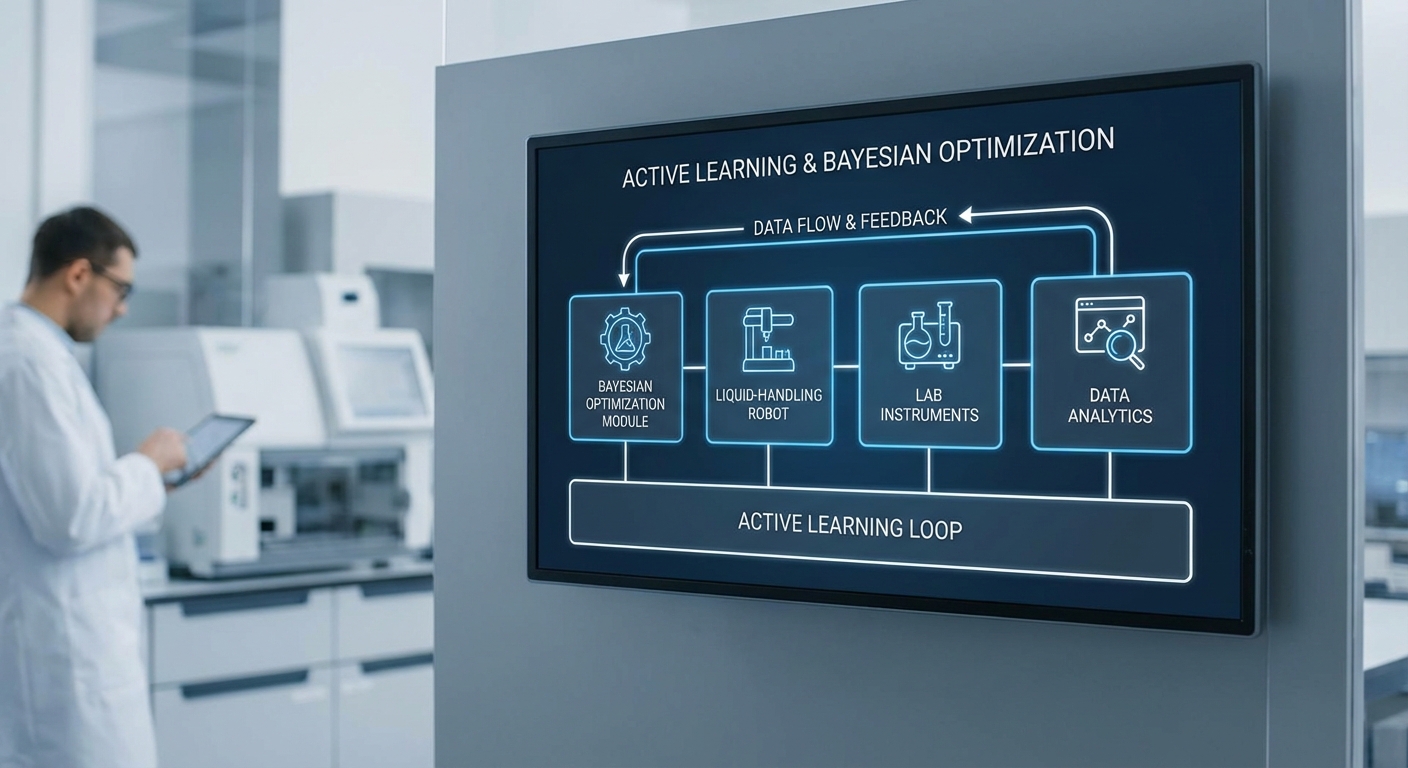
นำเสนอภาพรวม: ปัญหาและโอกาสในวงการทดลองยา
นำเสนอภาพรวม: ปัญหาและโอกาสในวงการทดลองยา
กระบวนการค้นคว้าและพัฒนายา (drug discovery & optimization) เป็นหนึ่งในกิจกรรมที่ใช้ทรัพยากรสูงทั้งด้านเวลา งบประมาณ และบุคลากร โดยทั่วไปการพัฒนายาจนถึงการได้รับอนุมัติใช้เวลานานหลายปี—มักอยู่ในช่วง 10–15 ปี—และมีต้นทุนรวมตั้งแต่ หลายร้อยล้านไปจนถึงระดับพันล้านดอลลาร์สหรัฐ ขึ้นกับประเภทของยาและขอบเขตการทดลอง งานวิจัยและรายงานอุตสาหกรรมชี้ว่าอัตราความสำเร็จจากการเริ่มต้นพัฒนาไปสู่การอนุมัติจริงมักต่ำกว่า ประมาณ 10% ทำให้ความล้มเหลวระหว่างทางเป็นต้นทุนที่สำคัญของระบบนิเวศการวิจัยยาระดับโลก
ในระดับห้องปฏิบัติการ ภารกิจสำคัญคือการค้นหาเงื่อนไขการทดลองที่เหมาะสม—เช่น ปริมาณสาร ความเข้มข้น เวลา อุณหภูมิ ตัวเร่งปฏิกิริยา ฯลฯ—ซึ่งแต่ละเงื่อนไขมีต้นทุนในแง่วัสดุ อุปกรณ์ และแรงงาน เงื่อนไขทดลองแต่ละชุดเมื่อรวมต้นทุนเชิงปฏิบัติการอาจมีมูลค่าสูงถึง หลักร้อยถึงหลักพันดอลลาร์ ทำให้การสำรวจเชิงสถิติเชิงอิสระ (brute‑force) เป็นไปได้ยากทั้งด้านเวลาและงบประมาณ นี่ยิ่งตอกย้ำความจำเป็นในการออกแบบการทดลองอย่างมีประสิทธิภาพเพื่อให้ได้ผลลัพธ์มากที่สุดจากจำนวนการทดลองที่จำกัด
ความท้าทายเชิงเทคนิคอีกประการคือปัญหา high‑dimensional experimental space เมื่อจำนวนพารามิเตอร์เพิ่มขึ้น ความเป็นไปได้ของการผสมผสานเงื่อนไขเติบโตแบบเลขยกกำลัง ตัวอย่างเช่น หากมีพารามิเตอร์ 10 ตัวและแต่ละตัวมี 5 ระดับ ความเป็นไปได้รวมจะเท่ากับ 510 = 9,765,625 รูปแบบ การสำรวจพจน์ทั้งหมดดังกล่าวในห้องปฏิบัติการเป็นไปไม่ได้ในทางปฏิบัติ ทั้งนี้ยังมีความไม่แน่นอนจากผลการทดลอง ความแปรปรวนของตัวอย่าง และเสียงรบกวน (noise) ในข้อมูล ทำให้การหาเงื่อนไขที่ดีที่สุดกลายเป็นปัญหาเชิงคณิตศาสตร์และทรัพยากรที่ซับซ้อน
ด้วยบริบทดังกล่าว การผสาน ปัญญาประดิษฐ์ (AI) โดยเฉพาะเทคนิคเช่น active learning และ Bayesian optimization เข้ากับระบบอัตโนมัติของหุ่นยนต์จัดของเหลวและการทดลอง มีศักยภาพในการเปลี่ยนแปลงวิธีทำงานของห้องปฏิบัติการอย่างมีนัยสำคัญ เหตุผลสำคัญได้แก่:
- ค้นหาเชิงรุก (exploration vs. exploitation) — Active learning สามารถเลือกการทดลองที่ให้ข้อมูลเชิงสารสนเทศสูงสุด ลดการทดลองที่ซ้ำซ้อนและเร่งการเรียนรู้ของโมเดล
- ประสิทธิภาพในการใช้ทรัพยากร — Bayesian optimization ช่วยค้นหา optimum ของฟังก์ชันที่มีค่าใช้จ่ายสูงและมีเสียงรบกวน โดยลดจำนวนการทดลองที่ต้องทำอย่างมีนัยสำคัญ
- ความสม่ำเสมอและสเกล — หุ่นยนต์ช่วยลดความคลาดเคลื่อนที่เกิดจากมนุษย์ เปิดโอกาสให้ทำการทดลองต่อเนื่อง 24/7 และเพิ่มอัตราการทำซ้ำซึ่งสำคัญต่อความเชื่อถือได้ของผล
- ความเร็วสู่ตลาดและมูลค่าทางธุรกิจ — การลดรอบเวลาและต้นทุนของการหาพารามิเตอร์ที่เหมาะสมสามารถย่นระยะเวลาในการพัฒนายา ทำให้บริษัทและสถาบันวิจัยมีความได้เปรียบทางการแข่งขันและลดความเสี่ยงทางการเงิน
ในบริบทของประเทศไทย แม้การลงทุนด้าน R&D โดยรวมจะยังต่ำกว่าประเทศที่พัฒนาแล้ว แต่ภาคชีวเภสัชและเทคโนโลยีชีวภาพกำลังเติบโตอย่างต่อเนื่อง การนำระบบ AI‑driven automation มาใช้จะช่วยสร้างความสามารถเชิงการแข่งขัน เพิ่มอัตราการใช้ทรัพยากรวิจัยให้เกิดผลสูงสุด และเปิดโอกาสเชิงธุรกิจทั้งในด้านการพัฒนายาร่วมทุน การให้บริการสาธิตเทคโนโลยี และการผลิตแบบกำหนดเฉพาะทาง ซึ่งเป็นช่องทางสร้างมูลค่าให้กับระบบนิเวศนวัตกรรมในประเทศ
เทคโนโลยีหลักของ LabBench‑AI: Active Learning, หุ่นยนต์จัดของเหลว และ Bayesian Optimization
LabBench‑AI รวมหลักการทางคณิตศาสตร์และฮาร์ดแวร์อัตโนมัติเข้าไว้ด้วยกัน เพื่อย่นระยะเวลาการค้นหาสมุนไพรโมเลกุลและพารามิเตอร์การทดลองทางเภสัชกรรมให้เหลือเพียง 1/5 ของรอบทดลองแบบดั้งเดิม โดยอาศัยสามองค์ประกอบหลักที่ทำงานร่วมกันอย่างเป็นระบบ: Active Learning สำหรับการเลือกทดลองที่ให้ข้อมูลมากที่สุด, หุ่นยนต์จัดของเหลว (liquid‑handling robots) สำหรับการปฏิบัติการที่แม่นยำและทำซ้ำได้สูง, และ Bayesian Optimization เพื่อหาจุดพารามิเตอร์ที่เหมาะสมที่สุดจากข้อมูลจำนวนน้อยต่อรอบทดลอง

1) Active Learning — เลือกตัวอย่างที่ให้ข้อมูลเชิงสารสนเทศสูงสุด
หลักการของ Active Learning คือการลดจำนวนตัวอย่างทดลองที่ต้องรันจริงโดยให้โมเดลเป็นผู้ "ถาม" ว่าควรทดลองจุดใดที่คาดว่าจะให้ข้อมูลมากที่สุดต่อการเรียนรู้ โมเดลจะประเมินความไม่แน่นอนหรือประโยชน์เชิงข้อมูลของแต่ละตัวเลือกแล้วจัดลำดับความสำคัญ วิธีการทั่วไปได้แก่ uncertainty sampling, query‑by‑committee, และการเลือกตัวอย่างตามค่าคาดหวังของการเปลี่ยนแปลงพารามิเตอร์ (expected model change)
- ข้อดีเชิงปริมาณ: ในงานวิจัยและเคสอุตสาหกรรม Active Learning สามารถลดจำนวนตัวอย่างที่ต้องเห็นหรือทดสอบได้ตั้งแต่ 50% ถึงเกือบ 90% ขึ้นกับลักษณะปัญหา
- การใช้งานจริงในห้องปฏิบัติการ: ตัวอย่างเช่น ในการหาเงื่อนไขการสังเคราะห์สารนำส่งยา LabBench‑AI จะให้โมเดลเลือกชุดของสภาวะทดลองที่คาดว่าจะลดความไม่แน่นอนของเส้นความสัมพันธ์ระหว่างพารามิเตอร์กับผลลัพธ์ได้มากที่สุด แทนที่จะทดสอบแบบ grid หรือ random ทั้งหมด
- ผลต่อวงจรการทดลอง: เมื่อผสานกับหุ่นยนต์และ Bayesian Optimization การเลือกตัวอย่างเชิงสารสนเทศสูงสุดจะทำให้แต่ละรอบทดลองให้ประโยชน์เชิงเรียนรู้สูงสุด ส่งผลให้จำนวนรอบและต้นทุนลดลงอย่างมาก
2) หุ่นยนต์จัดของเหลว (Liquid‑handling robots) — ความเที่ยงตรง ความเร็ว และความซ้ำซ้อน
หุ่นยนต์จัดของเหลวเป็นห่วงโซ่การผลิตเชิงปฏิบัติการที่สำคัญในการแปลงคำสั่งการทดลองจากซอฟต์แวร์เป็นผลลัพธ์เชิงทดลองที่เชื่อถือได้ โดยเฉพาะเมื่อใช้ร่วมกับกลยุทธ์เลือกตัวอย่างเชิงสารสนเทศที่ต้องการรันชุดทดลองเฉพาะเจาะจง
- Precision & Accuracy: หุ่นยนต์สุ่มตัวอย่างในปริมาณนาโนถึงไมโครลิตรด้วยความคลาดเคลื่อนต่ำ โดยทั่วไป CV (coefficient of variation) ของปริมาตรการาจัดการอยู่ในช่วง <1–3% สำหรับระบบระดับสูง ซึ่งลดความผันผวนของสัญญาณเชิงทดลองและเพิ่มความเชื่อมั่นในข้อมูลที่ป้อนกลับไปยังโมเดล
- Throughput: หุ่นยนต์ระดับห้องปฏิบัติการสามารถจัดการแผ่น 96‑well หรือ 384‑well ด้วยความเร็วหลายร้อยถึงหลายพันตัวอย่างต่อวัน ขึ้นกับขั้นตอนการเตรียมและการอ่านผล ทำให้การทดลองหลายสภาวะที่เลือกโดย Active Learning สามารถรันได้ในช่วงเวลาสั้นลง
- Reproducibility: ความสามารถในการทำซ้ำขั้นตอนเดิมอย่างแม่นยำช่วยลดแหล่งความไม่แน่นอนด้านกระบวนการ (process variability) ซึ่งสำคัญเมื่อนำข้อมูลกลับเข้าสู่โมเดล Bayesian หรือการเรียนรู้เชิงลึก เพราะข้อมูลมี noise น้อยลง โมเดลจึงคาดการณ์ได้แม่นยำขึ้น
สรุปคือ หุ่นยนต์จัดของเหลวทำหน้าที่เป็น "แขนปฏิบัติการ" ที่แปลคำสั่งเชิงข้อมูลของ Active Learning และ Bayesian Optimization ให้เป็นผลลัพธ์เชิงทดลองที่มีคุณภาพสูง ลด false signal และเพิ่มประสิทธิผลของรอบทดลองแต่ละครั้ง
3) Bayesian Optimization — หาเงื่อนไขทดลองที่ดีที่สุดด้วยตัวอย่างจำนวนน้อย
Bayesian Optimization (BO) เป็นกรอบการทำงานสำหรับ optimization ของฟังก์ชันที่ประเมินได้แพง (expensive-to-evaluate) และไม่มีรูปแบบปิด เช่น สมรรถนะของโมเลกุลภายใต้พารามิเตอร์การทดลองต่าง ๆ BO ใช้ surrogate model (เช่น Gaussian Process, Random Forest, หรือ Bayesian Neural Network) เพื่อประมาณพฤติกรรมของฟังก์ชันเป้าหมาย แล้วเลือกจุดทดลองใหม่โดยอาศัย acquisition function ที่สมดุลระหว่าง exploration (สำรวจพื้นที่ไม่แน่นอน) และ exploitation (ใช้พื้นที่ที่คาดว่าดีอยู่แล้ว)
- Surrogate models: Gaussian Process (GP) เป็นตัวเลือกคลาสสิกเพราะให้การคาดการณ์ค่าพร้อมค่าความไม่แน่นอน (mean + variance) แต่สำหรับปัญหามิติสูงหรือข้อมูลเชิงหมวดหมู่ อาจใช้ Random Forest หรือ Bayesian Neural Networks แทน
- Acquisition functions ที่นิยม: Expected Improvement (EI), Upper Confidence Bound (UCB), Probability of Improvement (PI) — ฟังก์ชันเหล่านี้แปลงการคาดการณ์ของ surrogate model ให้เป็นคะแนนสำหรับเลือกจุดทดลองถัดไป
- ตัวเลขเชิงประสิทธิผล: ในหลายงาน BO สามารถหา near‑optimal settings ได้ภายใน 10–50 การทดลอง ขณะที่การค้นหาแบบสุ่มหรือ grid search อาจต้องการเป็นร้อยถึงพันการทดลองเพื่อให้ได้ผลใกล้เคียงกัน
การประสานงานระหว่าง BO กับ Active Learning และหุ่นยนต์คือวงจรปิด (closed loop): BO แนะนำเงื่อนไขทดลองที่น่าเป็นประโยชน์, Active Learning ระบุจุดที่เพิ่มข้อมูลเชิงสารสนเทศ, และหุ่นยนต์ดำเนินการทดลองจริงทันที จากนั้นผลลัพธ์ถูกป้อนกลับสู่ surrogate model เพื่ออัพเดตความเชื่อและเลือกจุดถัดไป
ตัวอย่างการตั้ง objective และ constraints ในบริบทการทดลองยา
เมื่อออกแบบการเพิ่มประสิทธิภาพเชิงทดลองสำหรับการค้นหายา เราต้องนิยามฟังก์ชันเป้าหมาย (objective) และข้อจำกัด (constraints) อย่างชัดเจน ตัวอย่างการตั้งค่าเชิงปฏิบัติการมีดังนี้:
- Objective (ตัวอย่าง):
- Maximize pharmacological potency (เช่น ลดค่า IC50 ให้ต่ำสุด)
- Maximize selective index = potency / toxicity
- Minimize cost per assay หรือ minimize reaction time โดยยังคง potency สูง
- Constraints (ตัวอย่าง):
- ความเป็นพิษ (toxicity) ต้องไม่เกินค่าคงที่ที่ยอมรับได้ (เช่น cell viability > 80%)
- ความละลาย (solubility) ต้องผ่านเกณฑ์ขั้นต่ำเพื่อตรวจวัดได้ (เช่น > 10 µM)
- ข้อจำกัดเชิงปฏิบัติการ เช่น ปริมาณตัวอย่างขั้นต่ำ/สูงสุดที่หุ่นยนต์สามารถจัดการได้และเวลาทดสอบสูงสุดต่อรอบ
- ข้อจำกัดด้านต้นทุนหรือความพร้อมของ reagent — บางพารามิเตอร์อาจมี "budget" หรือจำกัดจำนวนครั้งทดสอบ
ในการใช้งานจริง เราจะรวม objective และ constraints เหล่านี้เข้าเป็นฟังก์ชันเดียวหรือหลายมิติ (multi‑objective optimization) และ BO จะพยายามหา trade‑off ที่ดีที่สุด เช่น การใช้ Pareto front เพื่อเลือกชุดพารามิเตอร์ที่ให้สมดุลระหว่าง potency กับ toxicity ภายใต้ข้อจำกัดด้านปริมาณและต้นทุน
โดยสรุป การผสาน Active Learning, หุ่นยนต์จัดของเหลว และ Bayesian Optimization ในแพลตฟอร์มอย่าง LabBench‑AI ทำให้สามารถลดจำนวนการทดลองจริงและรอบการค้นคว้าได้อย่างมีนัยสำคัญ เพิ่มความน่าเชื่อถือของข้อมูล และเร่งเวลาเข้าสู่การตัดสินใจเชิงกลยุทธ์ในงานพัฒนายาระดับห้องปฏิบัติการและอุตสาหกรรม
เคสศึกษา: การนำไปใช้ในห้องปฏิบัติการสถาบันวิจัย — ผลลัพธ์จริง
เคสศึกษา: การนำไปใช้ในห้องปฏิบัติการสถาบันวิจัย — ผลลัพธ์จริง
สถาบันวิจัยพันธมิตรของ LabBench‑AI มีวัตถุประสงค์เพื่อเพิ่มประสิทธิภาพการทดลองด้านสภาพแวดล้อมปฏิกิริยา (reaction conditions) และองค์ประกอบบัฟเฟอร์สำหรับกระบวนการสังเคราะห์/ทดสอบสารนำร่อง โดยเป้าหมายเชิงปฏิบัติคือการเพิ่มผลผลิต (yield) และความทนทานของเงื่อนไขภายใต้ข้อจำกัดด้านเวลาและวัสดุเดิม ทีมวิจัยเลือกเคสตัวอย่างที่มีความซับซ้อนปานกลางถึงสูง: การปรับแต่งพารามิเตอร์หลายมิติสำหรับปฏิกิริยาเอนไซม์เพื่อให้ได้ประสิทธิภาพสูงสุดในเชิงปริมาณและการทำซ้ำ
รายละเอียดพารามิเตอร์ที่ optimized ดังนี้
- จำนวนพารามิเตอร์: 6 ตัวแปรต่อการทดลอง (pH, อุณหภูมิ, ความเข้มข้นตัวทำปฏิกิริยา, ความเข้มข้นเกลือ, อัตราส่วน cofactor, เวลาปฏิกิริยา)
- ช่วงค่าที่สำรวจ: pH 5.0–9.0 (ต่อเนื่อง), อุณหภูมิ 20–45°C, reagent 0.1–10 mM, NaCl 0–200 mM, cofactor 0–1 (ratio), incubation 5–120 นาที
- ขนาดปัญหา (เชิงคณิตศาสตร์): เมื่อแบ่งเป็นระดับประมาณ 10 ระดับต่อพารามิเตอร์ จะให้การผสมเชิงตารางสูงถึง ~10^6 กรณีที่เป็นไปได้ — ไม่สามารถสำรวจแบบ exhaustive ได้ในการทำงานจริง
ขั้นตอนการทำงานที่นำไปใช้ร่วมกับ LabBench‑AI ประกอบด้วยการผสานสามองค์ประกอบหลัก: (1) อัลกอริทึม Bayesian Optimization ที่ออกแบบมาเพื่อค้นหาจุดสูงสุดในพื้นที่พารามิเตอร์หลายมิติ, (2) กลไก Active Learning ที่เลือกตัวอย่างถัดไปโดยคำนึงถึงความไม่แน่นอนของโมเดล, และ (3) หุ่นยนต์จัดการของเหลวสำหรับการดำเนินการจริงในแล็บ ทำให้ลูปออกแบบ–ทดสอบ–เรียนรู้สั้นลงอย่างมาก ตัวอย่าง workflow: เริ่มจากชุดสาธิต 12 จุด เลือกชุดทดลองถัดไปโดย Bayesian acquisition function ทำซ้ำเป็นรอบ ๆ จนกว่าค่า objective จะถึงเกณฑ์
ผลลัพธ์เชิงปริมาณจากรายงานของห้องปฏิบัติการมีดังนี้ (ตัวเลขรายงานโดยทีมวิจัยพันธมิตร):
- รอบทดลองลดลงเหลือ 1/5: จากเดิมเฉลี่ยประมาณ 100 รอบ ในกระบวนการเดิมแบบ DOE/one‑factor‑at‑a‑time เหลือเพียง ~20 รอบ ภายใต้การนำของ LabBench‑AI
- throughput เพิ่มขึ้นเป็น 4 เท่า: จาก ~10 การทดลองต่อวัน เป็น ~40 การทดลองต่อวัน เนื่องจากการรันที่ต่อเนื่องโดยหุ่นยนต์และการเลือกตัวอย่างที่มีประสิทธิภาพ
- เวลาในการค้นหาลดลง 78%: เวลารวมจากการวางแผนถึงการยืนยันผล (end‑to‑end) ลดจาก ~45 วัน เหลือ ~10 วัน (ตัวเลขตามการวัดเวลาจริงในแลบ)
- อัตราสำเร็จ (yield/hit‑rate) เพิ่มขึ้น: ผลผลิตที่เกินเกณฑ์เป้าหมายเพิ่มจากเฉลี่ย ~45% ในวิธีดั้งเดิม เป็น ~82% หลังการปรับด้วย LabBench‑AI (เพิ่มขึ้นเชิงสถิติและเชิงปฏิบัติ)
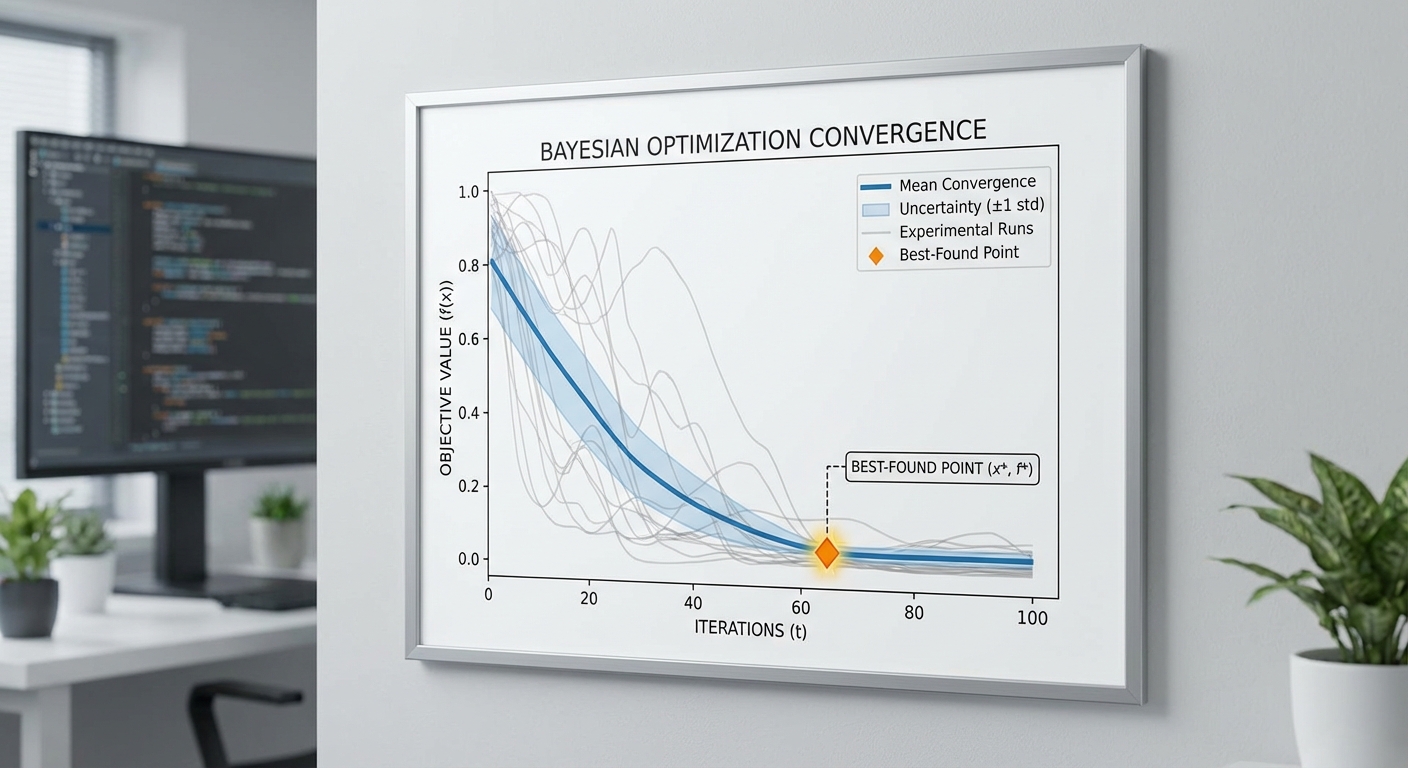
เพื่อแสดงภาพเปรียบเทียบ ทีมวิจัยเสนอข้อมูลสรุปเชิงตัวอย่าง (graphical summary ถูกแนบในรายงานฉบับเต็ม):
- ก่อนใช้ LabBench‑AI: เส้นโค้งการปรับปรุง yield ต่อรอบแสดงการเพิ่มอย่างช้า ๆ และ plateau ก่อนค่าที่เป็นจริงสูงสุด — ต้องการ ~100 รอบจึงเข้าถึงเกณฑ์
- หลังใช้ LabBench‑AI: เส้นโค้งแสดงการกระโดดขึ้นของ objective ในรอบแรก ๆ และถึง plateau ที่สูงกว่าใน ~20 รอบ ตัวอย่าง: รอบที่ 5 พบเงื่อนไขที่ให้ yield 60% (เดิมต้องใช้ ~40 รอบเพื่อให้ได้ระดับเดียวกัน)
การยืนยันความทนทานและความสามารถในการทำซ้ำ (robustness validation) ดำเนินการดังนี้
- ทดสอบเงื่อนไขที่ค้นพบด้วยการทำซ้ำ 12 ตัวอย่างต่อเงื่อนไข ใน 3 ชุดการผลิตต่างกัน (3 batches) ผลแสดงค่าเฉลี่ยและ coefficient of variation (CV) < 8%
- ทดสอบความไวต่อการเปลี่ยนแปลงสภาพแวดล้อม ±2°C และ ±0.1 หน่วย pH พบว่า yield ยังคงอยู่ที่ ≥95% ของค่าที่พบในสภาพมาตรฐาน
- การยืนยันเชิงสถิติ (t‑test และ ANOVA) ชี้ให้เห็นว่าพารามิเตอร์ที่ค้นพบมีความแตกต่างอย่างมีนัยสำคัญเมื่อเทียบกับเงื่อนไขเดิม (p < 0.01)
สรุปเชิงธุรกิจ: การผสาน LabBench‑AI กับหุ่นยนต์จัดการของเหลวและกลยุทธ์ Bayesian optimization ช่วยให้สถาบันวิจัยลดต้นทุนเวลาและวัสดุอย่างมีนัยสำคัญ (รอบทดลองเหลือ 1/5, throughput เพิ่ม 4 เท่า, เวลาลด 78%) พร้อมทั้งปรับปรุงอัตราความสำเร็จของกระบวนการ ทำให้การพัฒนาสารนำร่องหรือการปรับสภาพปฏิกิริยาสำหรับการสเกลต่อไปมีพื้นฐานข้อมูลที่เชื่อถือได้และพร้อมใช้งานในเชิงพาณิชย์มากขึ้น
เวิร์กโฟลว์และสถาปัตยกรรมข้อมูล: จากการออกแบบทดลองถึงการตัดสินใจ
เวิร์กโฟลว์โดยรวม: จากการออกแบบทดลองถึงการตัดสินใจอัตโนมัติ
เวิร์กโฟลว์ของระบบ LabBench‑AI ถูกออกแบบมาเป็นวงจรปิด (closed loop) ที่ผสานการออกแบบทดลองเชิงสถิติ, หุ่นยนต์จัดของเหลว, การจัดเก็บข้อมูลเชิงระบบ และการเรียนรู้ของเครื่องแบบ Bayesian เพื่อให้การตัดสินใจเรียงลำดับการทดลองเป็นไปอย่างมีประสิทธิภาพ ขั้นตอนหลักประกอบด้วย initial design (ชุดทดลองเริ่มต้น) → การรันโดยหุ่นยนต์และการวัดผล → การเก็บและตรวจสอบคุณภาพข้อมูล (instrument integration, LIMS) → การฝึก surrogate model (เช่น Gaussian Process) → การคำนวณ acquisition function (เช่น Expected Improvement) → การสั่งรันชุดทดลองถัดไปโดยอัตโนมัติ และทำใหม่จนกว่าจะบรรลุเป้าหมายหรือถึงข้อจำกัดทรัพยากร
เวิร์กโฟลว์นี้ลดรอบการทดลองได้อย่างมีนัยสำคัญในเคสจริง โดยการชี้นำให้ทดลองเฉพาะจุดที่คาดว่าจะให้ข้อมูลสูงสุด — ตัวอย่างเช่นกรณีศึกษาในสถาบันวิจัยที่ใช้ LabBench‑AI รายงานว่าจำนวนรอบทดลองลดลงเหลือประมาณ 1/5 เมื่อเทียบกับการค้นหาแบบ grid search ดั้งเดิม
รายละเอียดขั้นตอนเชิงปฏิบัติ
- Initial design (การออกแบบแคมเปญทดลองเริ่มต้น)
- เลือกจุดเริ่มต้นโดยใช้วิธีสุ่มเชิงพื้นที่ (Latin hypercube) หรือกำหนดโดยผู้เชี่ยวชาญ (domain priors) เพื่อให้หลีกเลี่ยง bias จากจุดเริ่มต้นเพียงจุดเดียว
- กำหนดตัวแปรการทดลอง (ตัวอย่างเช่น pH, อัตราการเติม, อุณหภูมิ, ความเข้มข้นของสาร) และขอบเขตของแต่ละตัวแปร
- ตั้งค่าจำนวน replications เพื่อประเมินความไม่แน่นอนของการวัด (เช่น replicate = 3)
- การรันหุ่นยนต์และการวัดผล
- ระบบสั่งงานหุ่นยนต์ผ่าน scheduler ที่รับคำสั่ง batch จาก acquisition module
- การจัดการพาหะ (plates, tubes) และการ calibrate หุ่นยนต์ก่อนรัน เพื่อให้ความคลาดเคลื่อนเชิงตำแหน่งและปริมาณน้อยที่สุด
- เก็บ metadata สำคัญ (timestamp, plate ID, well position, operator, instrument ID)
- การเก็บข้อมูล ทดลอง และการบูรณาการกับ LIMS
- ผลการวัดจะถูกส่งไปยังระบบ LIMS/ELN ผ่าน API หรือ message queue (เช่น REST, MQTT)
- รูปแบบข้อมูลมาตรฐาน (JSON/CSV) ประกอบด้วยค่า measurement, เบี่ยงเบนมาตรฐานจาก replicates, และสถานะ QC
- Data provenance ถูกบันทึกเพื่อให้ย้อนกลับได้ (which robot, which protocol, calibration version)
- การตรวจสอบคุณภาพข้อมูล (Data validation & uncertainty-aware measurement)
- data validator จะตรวจจับ outliers, missing values และความไม่สอดคล้องของ metadata ก่อนส่งต่อให้ model trainer
- วัดความไม่แน่นอนจาก replicates และ propagation ของ noise จะถูกป้อนเข้า surrogate model เป็น noise term เพื่อให้โมเดลคำนวณความไม่แน่นอนได้ถูกต้อง
- การฝึก surrogate model และการคำนวณ acquisition
- model trainer ปรับโมเดลเช่น Gaussian Process (GP) โดยใช้ข้อมูลเดิมและค่า noise ที่ประเมินได้
- acquisition function (เช่น Expected Improvement) คำนวณจุดถัดไปที่ให้ประโยชน์คาดหวังสูงสุด โดยพิจารณาค่า mean และ variance จาก GP
- ถ้ามีการรันแบบคู่ขนาน (batch), acquisition ถูกปรับให้เลือกชุดจุดที่มีความหลากหลาย (batch EI หรือ qEI)
- Scheduler และการวนลูปอัตโนมัติ
- เมื่อได้ชุดจุดถัดไป scheduler จะแปลงคำสั่งเป็นโปรโตคอลหุ่นยนต์และจัดลำดับการทำงานร่วมกับ LIMS
- วงจรจะวนซ้ำจนกระทั่งบรรลุเป้าหมาย (target metric), ใช้งบประมาณครบ หรือไม่มีการปรับปรุงที่มีนัยสำคัญเป็นจำนวน N รอบ
สถาปัตยกรรมซอฟต์แวร์: องค์ประกอบและการเชื่อมต่อ
สถาปัตยกรรมข้อมูลของ LabBench‑AI ถูกออกแบบเป็นโมดูลหลักที่แยกความรับผิดชอบชัดเจน เพื่อความยืดหยุ่นและความทนทานต่อข้อผิดพลาด แต่ละโมดูลสื่อสารผ่าน API และ message bus (เช่น Kafka หรือ RabbitMQ) ประกอบด้วย:
- Experiment Manager — ประสานงานการออกแบบแคมเปญ, จัดการ metadata ของการทดลอง, และเป็น interface สำหรับผู้ใช้หรือทีมวิจัย
- Data Validator / ETL — รับผลจาก instruments/LIMS, ทำความสะอาดข้อมูล, ประเมินความไม่แน่นอน และป้อนข้อมูลให้โมเดล
- Model Trainer (Surrogate) — ฝึก GP หรือ surrogate อื่น ๆ, บันทึก version ของโมเดล และให้บริการ prediction + uncertainty ผ่าน model API
- Acquisition Engine — คำนวณ acquisition function, รองรับ batch selection, และส่งคำสั่งไปยัง Scheduler
- Scheduler & Robot Controller — แปลงการตัดสินใจเป็นโปรโตคอลหุ่นยนต์, จัดคิวรัน, และรายงานสถานะกลับสู่ LIMS/Experiment Manager
- Storage & Provenance — object store สำหรับ raw data, time series, model artifacts และ log ที่จำเป็นสำหรับการ audit
ตัวอย่าง pseudo‑workflow / flowchart (เชิงลำดับ)
- 1. Initialize campaign:
- กำหนด design space, constraints, budget, objective function
- สร้าง initial experiments N0 (e.g., N0 = 12 via Latin hypercube)
- 2. Submit initial batch → Scheduler → Robot run → Instrument measures → Results → LIMS
- 3. Data Validator: clean & compute per‑point uncertainty → Store
- 4. Model Trainer: Fit GP to (X, y, σ_y) → provide μ(x), σ(x)
- 5. Acquisition Engine: compute EI(x) = E[max(0, f(x) − f_best − ξ)] → select top K points
- 6. Scheduler: send selected points to robot → goto step 2
- 7. Stopping criteria: if f_best ≥ target OR budget exhausted OR no improvement in M iterations → terminate
ตัวอย่างการตั้งค่าพารามิเตอร์สำหรับ Bayesian Optimization
ด้านล่างเป็นตัวอย่างการตั้งค่าเชิงปฏิบัติที่สามารถนำไปใช้เป็นค่าเริ่มต้น (tunable) ในแคมเปญวิจัยยา:
- Surrogate model: Gaussian Process Regression (GPR) with heteroscedastic noise handling
- Kernel: Matern 5/2 with ARD (automatic relevance determination); initial lengthscales set per‑dimension จาก domain priors
- Noise model: observation noise σ_i estimatedจาก replicates; GP likelihood = Gaussian with input‑dependent noise
- Acquisition function: Expected Improvement (EI)
- EI formula (conceptual): EI(x) = E[max(0, f(x) − f_best − ξ)]
- exploration parameter ξ (xi) = 0.01 (conservative) หรือ 0.1 (more exploratory)
- สำหรับ batch selection ใช้ q‑EI หรือ greedy penalization เพื่อกระจายจุด
- Optimization of acquisition: multi‑start gradient descent (20 starts) หรือ Bayesian optimization ในโซลูชัน acquisition inner loop
- Batch size: K = 4 (ขึ้นกับ throughput ของหุ่นยนต์และเครื่องมือ)
- Stopping criteria:
- target metric achieved (เช่น IC50 ≤ target) OR
- budget (number of experiments) reached OR
- no significant improvement (f_best change < ε) ใน M = 5 รอบติดต่อกัน
แนวปฏิบัติด้านความน่าเชื่อถือและความโปร่งใส
ระบบที่ใช้งานในสภาพแวดล้อมห้องปฏิบัติการต้องออกแบบเพื่อความปลอดภัยและการตรวจสอบได้: เก็บผลสำเนาของ raw data, เก็บเวอร์ชันของโมเดลและพารามิเตอร์ acquisition, บันทึกการตัดสินใจของระบบอัตโนมัติเป็น audit trail และให้ผู้เชี่ยวชาญสามารถ override หรือหยุดวงจรได้ทุกเมื่อ นอกจากนี้การประเมินความไม่แน่นอนเชิงปริมาณอย่างต่อเนื่อง (uncertainty‑aware measurement) ช่วยให้การตัดสินใจของ BO คำนึงถึงความเชื่อมั่นของข้อมูลจริง ไม่ใช่เพียงค่าคาดหมายเพียงอย่างเดียว
สรุปคือ การผสานกันของการออกแบบแคมเปญที่รอบคอบ, การเชื่อมต่อเครื่องมือ/ LIMS อย่างแน่นหนา, การตรวจสอบคุณภาพข้อมูล และการประยุกต์ Bayesian Optimization (โดยใช้ GP + EI และการจัดการ uncertainty) คือหัวใจของการลดรอบทดลองให้เหลือประมาณ 1/5 ในเคสจริง — ทั้งยังรักษาความน่าเชื่อถือและความสามารถในการติดตามผลสำหรับงานวิจัยทางเภสัชกรรม
ความเสี่ยง ข้อจำกัด และประเด็นเชิงจริยธรรม/กฎระเบียบ
ความเสี่ยง ข้อจำกัด และประเด็นเชิงจริยธรรม/กฎระเบียบ
ข้อจำกัดทางเทคนิคและความเสี่ยงเชิงโมเดล — การใช้ surrogate models ร่วมกับ Bayesian optimization และ active learning ให้ประสิทธิภาพสูงในการลดจำนวนรอบทดลอง แต่มีข้อจำกัดสำคัญเมื่อระบบมีความซับซ้อนทางมิติข้อมูล (high dimensionality) และเมื่อตัวแปรการทดลองหลายตัวมีปฏิสัมพันธ์เชิงไม่เชิงเส้น ตัวอย่างเช่น โมเดลแบบ Gaussian Process หรือ Kriging มักมีความยากลำบากในการสเกลเมื่อจำนวนมิติพารามิเตอร์เกินระดับหนึ่ง (มักพบปัญหาได้บ่อยเมื่อมีตัวแปรในระดับหลายสิบถึงร้อยตัว) ซึ่งจะส่งผลต่อเวลาในการเทรน ความเที่ยงตรงของการพยากรณ์ และความแม่นยำของการประเมิน uncertainty นอกจากนี้ ความไวของโมเดลต่อ measurement noise เป็นความเสี่ยงเชิงระบบ: หากข้อมูลการวัดมี noise สูง (เช่น coefficient of variation ที่ไม่สามารถยอมรับได้สำหรับแอปพลิเคชันนั้น) จะทำให้การคัดเลือกตัวอย่างถัดไป (acquisition) บิดเบี้ยวและอาจนำไปสู่การล้มเหลวในการค้นหาพื้นที่ของพารามิเตอร์ที่ดีที่สุด
ความท้าทายเชิงปฏิบัติการของการบูรณาการระบบ — การนำหุ่นยนต์จัดของเหลวและวงจร active learning ไปเชื่อมต่อกับระบบแลบเดิม เช่น LIMS (Laboratory Information Management System), ระบบเครื่องมือเครื่องวัด (instrument control) และฐานข้อมูลผลการทดลอง มีความซับซ้อนทั้งด้านเทคนิคและกระบวนการ ตัวอย่างปัญหาได้แก่ ความไม่เข้ากันของรูปแบบข้อมูล (heterogeneous data formats), การสื่อสารแบบเรียลไทม์ระหว่าง API, การจัดการคิวงานทดลอง และการทำงานร่วมกับเครื่องมือที่ต้องการการสอบเทียบเฉพาะ (calibration) การบำรุงรักษาหุ่นยนต์เองก็เป็นความเสี่ยงที่ต้องคำนึง—การสึกหรอของหัวจ่าย (pipette tips), การอุดตัน, การลื่นไถลของปั๊ม, หรือปัญหาไฟฟ้าอาจทำให้การทดลองเสียหายหรือปนเปื้อนตัวอย่างได้ และหากไม่มีแผนบำรุงรักษาเชิงป้องกัน (preventive maintenance) หรือการตรวจสอบความถูกต้อง (qualification: IQ/OQ/PQ) อย่างเป็นระบบ จะเสี่ยงต่อการหยุดชะงักและต้นทุนซ่อมแซมสูง
ประเด็นด้านความปลอดภัย จริยธรรม และกฎระเบียบ — งานวิจัยและการทดลองที่เกี่ยวข้องกับการค้นคว้ายา ต้องปฏิบัติตามมาตรฐานด้านกฎระเบียบและข้อกำหนดการตรวจสอบ (compliance) เช่น ข้อกำหนด GLP/GMP, แนวปฏิบัติ FDA 21 CFR Part 11 (สำหรับระบบบันทึกอิเล็กทรอนิกส์และลายเซ็น), รวมถึง Annex 11 ของ EU GMP สำหรับระบบคอมพิวเตอร์ ความเสี่ยงด้านกฎระเบียบรวมถึงการขาด audit trail ที่ครบถ้วน, การบันทึกข้อมูลที่ไม่สามารถตรวจสอบย้อนกลับ (lack of provenance), และปัญหา data integrity (เช่นการแก้ไขข้อมูลโดยไม่ได้รับอนุญาตหรือการสูญหายของข้อมูล) ซึ่งจะส่งผลต่อ reproducibility ของผลการทดลองและความสามารถในการผ่านการตรวจสอบจากหน่วยงานกำกับดูแล
คำแนะนำเชิงปฏิบัติและมาตรการลดความเสี่ยง — เพื่อบรรเทาความเสี่ยงที่กล่าวมา ควรนำแนวปฏิบัติดังต่อไปนี้มาใช้ในเชิงปฏิบัติการและการกำกับดูแล:
- ออกแบบการตรวจสอบความไม่แน่นอน (UQ) และ validation metrics — ใช้การวัดความเที่ยงตรงและความคลาดเคลื่อนเช่น RMSE/MAE ควบคู่กับการประมาณความไม่แน่นอนเชิงสถิติ และตั้งเกณฑ์คุณภาพ (acceptance thresholds) ก่อนนำผลไปตัดสินใจทดลองถัดไป
- ลดมิติหรือเลือก feature อย่างระมัดระวัง — ใช้เทคนิคลดมิติ เช่น PCA, feature selection หรือ incorporation ของ prior knowledge เพื่อลดภาระของ surrogate models และหลีกเลี่ยง overfitting ในสภาพข้อมูลมิติสูง
- ใช้ ensemble models และโมเดลที่ทนต่อ noise — การใช้งาน ensemble หรือการผสมผสานโมเดลที่มีการประมาณความไม่แน่นอนจะช่วยให้การคาดการณ์มีความเสถียรยิ่งขึ้นเมื่อข้อมูลมี noise
- มาตรการตรวจสอบทางห้องปฏิบัติการ — กำหนด SOP สำหรับการสอบเทียบเครื่องมือและหุ่นยนต์ (เช่น ตาราง calibration รายวัน/สัปดาห์), ใช้ QC samples และการวัดซ้ำ (replicates) ในชุดทดสอบเพื่อจับ anomalous measurements
- บูรณาการข้อมูลแบบปลอดภัยและมีมาตรฐาน — เชื่อมต่อกับ LIMS ผ่าน API ที่มีการรับรองความปลอดภัย (เช่น HTTPS, OAuth2) และใช้มาตรฐาน metadata/format เช่น AnIML หรือ Allotrope เพื่อรองรับ interoperability และ provenance ของข้อมูล
- บันทึก audit trail และการจัดการเวอร์ชัน — เก็บ log ทุกการเปลี่ยนแปลงข้อมูล, การตัดสินใจของโมเดล, เวอร์ชันของซอฟต์แวร์และโมเดล รวมถึงลายเซ็นอิเล็กทรอนิกส์เมื่อต้องการการอนุมัติ เพื่อให้สอดคล้องกับ 21 CFR Part 11 และข้อกำหนดที่คล้ายกัน
- ควบคุมการเข้าถึงและสำรองข้อมูล — ใช้การบริหารจัดการสิทธิ์แบบ role-based, encryption ข้อมูลขณะพักและขณะส่ง, ระบบสำรองและการเก็บข้อมูลแบบ WORM สำหรับข้อมูลสำคัญ
- กระบวนการทวนสอบและมนุษย์ในวงจร (human-in-the-loop) — ระบุจุดที่ต้องมีการตรวจทานโดยผู้เชี่ยวชาญก่อนเริ่มรอบทดลองสำคัญ และตั้งเกณฑ์การยกเลิก/stop criteria อัตโนมัติเมื่อพบความเบี่ยงเบนที่สำคัญ
- การบำรุงรักษาเชิงป้องกันและการฝึกอบรม — จัดตาราง preventive maintenance, stock ชิ้นส่วนสำรอง, และฝึกอบรมบุคลากรด้านการซ่อมและการปฏิบัติการเชิงระบบหุ่นยนต์อย่างสม่ำเสมอ
- แผนการบริหารความเสี่ยงเชิงกฎระเบียบ — จัดทำ DQ/IQ/OQ/PQ สำหรับระบบอัตโนมัติ, แผนการตรวจสอบภายในเป็นระยะ, และเอกสารประกอบเพื่อรองรับการตรวจจากหน่วยงานกำกับดูแล
โดยสรุป การนำ LabBench‑AI มาใช้เพื่อเร่งรัดกระบวนการทดลองยาสามารถลดรอบทดลองและต้นทุนได้อย่างมีนัยสำคัญ แต่ต้องคำนึงถึงข้อจำกัดทางเทคนิค การปฏิบัติการ และข้อกำกับดูแลอย่างรอบคอบ การผสมผสานมาตรการทางวิศวกรรม ข้อกำหนดการบำรุงรักษา การตรวจสอบคุณภาพข้อมูล และนโยบายด้านกฎระเบียบ จะช่วยลดความเสี่ยงและเพิ่มความน่าเชื่อถือของผลลัพธ์ในการนำไปใช้เชิงพาณิชย์หรือเพื่อการขออนุมัติจากหน่วยงานที่เกี่ยวข้อง
ผลกระทบเชิงอุตสาหกรรมและแนวทางขยายผลในอนาคต
ผลกระทบเชิงอุตสาหกรรมและแนวทางขยายผลในอนาคต
การนำระบบอย่าง LabBench‑AI ที่รวม active learning, หุ่นยนต์จัดของเหลว และ Bayesian optimization มาใช้ในห้องปฏิบัติการวิจัยยาได้แสดงให้เห็นถึงศักยภาพในการพลิกโฉมกระบวนการค้นคว้ายาอย่างชัดเจน โดยเคสจริงที่รอบการทดลองลดเหลือ 1/5 หมายถึงการลดเวลาในการค้นหาและทดสอบสมมุติฐานลงถึงประมาณ 80% เมื่อเทียบกับกระบวนการดั้งเดิม ผลลัพธ์เช่นนี้นำไปสู่การลดต้นทุนในเชิงตรง (reagents, consumables, ชั่วโมงเครื่องมือ และแรงงาน) รวมทั้งต้นทุนในเชิงอ้อม (เวลาจัดการข้อมูลและการวิเคราะห์) — แนวประเมินอนุรักษ์นิยมชี้ว่าโครงการคัดกรอง/ปรับปรุงโมเลกุลหนึ่งโครงการอาจลดต้นทุนได้ประมาณ 40–70% ขึ้นกับชนิดการทดลองและขนาดโครงการ ซึ่งเทียบได้กับการประหยัดตั้งแต่หลักแสนไปจนถึงหลักล้านบาทต่อโครงการสำหรับสถาบันวิจัยหรือบริษัทสตาร์ทอัพขนาดกลาง
ในมุมมองเชิงอุตสาหกรรม การลดรอบทดลองและการเพิ่มความสามารถในการทดลองแบบ high‑throughput จะช่วยให้เกิดการเปลี่ยนแปลงในหลายระดับ: เพิ่มจำนวนโครงการที่สามารถรันพร้อมกัน, เร่งระยะเวลาเข้าสู่การทดสอบก่อนคลินิก, และลดความเสี่ยงด้านงบประมาณสำหรับการลงทุนระยะยาว ผลกระทบนี้มีความสำคัญโดยเฉพาะต่อภูมิภาคเอเชียตะวันออกเฉียงใต้ที่ยังต้องการการเพิ่มขีดความสามารถทางชีวการแพทย์ — สถาบันวิจัยและ CRO ในไทยสามารถใช้เทคโนโลยีดังกล่าวเป็นจุดขายเพื่อดึงงานจากบริษัทต่างชาติและสร้างห่วงโซ่คุณค่าในภูมิภาคได้มากขึ้น
เชิงพาณิชย์ โอกาสทางธุรกิจที่ชัดเจนได้แก่การให้บริการ automation‑as‑a‑service (AaaS) แก่หน่วยงานวิจัยและบริษัทเวชภัณฑ์ที่ไม่มีทุนซื้อระบบอัตโนมัติเต็มรูปแบบ รวมถึงการพัฒนา แพลตฟอร์ม optimization ที่ให้ลูกค้าเช่าใช้อัลกอริทึม Bayesian และโมดูล active learning บนฐานข้อมูลการทดลองจริง รูปแบบรายได้ที่เป็นไปได้ได้แก่
- โมเดลการให้บริการเป็นรายโครงการ (project‑based pricing) สำหรับงานคัดกรองและ lead‑optimization
- แพลตฟอร์มเป็นบริการ (SaaS) ที่คิดค่าบริการตามจำนวนรันการทดลองหรือทรัพยากรคำนวณ
- การให้สิทธิ์การใช้งาน (licensing) ของซอฟต์แวร์ optimization แก่ CRO และห้องปฏิบัติการระดับภูมิภาค
- ข้อมูลและโมเดลเป็นสินค้า (data/ML model licensing) สำหรับงานพัฒนาโมเลกุลหรือการทำนายคุณสมบัติทางเภสัชกรรม
ในด้านเทคนิคและการวิจัยต่อไป ควรขยายขอบเขตจากการแก้ปัญหาเชิงเดี่ยวไปสู่การแก้ปัญหาเชิงซ้อนด้วยแนวทางต่อไปนี้: การนำ multi‑objective optimization มาผสานเพื่อให้ระบบสามารถปรับจูนพารามิเตอร์หลายมิติพร้อมกัน (เช่น ความเป็นพิษ, ความมีประสิทธิภาพ, ความละลายน้ำ) ซึ่งจะช่วยลดความจำเป็นต้องแลกเปลี่ยนระหว่างคุณสมบัติที่ขัดกัน การบูรณาการกับโมเดล ML ทางชีวภาพที่ทันสมัย เช่น การพยากรณ์โครงสร้างโปรตีนหรือโมเดลเชิงกลไก จะเพิ่มความสามารถในการประมาณผลลัพธ์เชิงชีวภาพและทำให้การตัดสินใจเชิงทดลองมีความแม่นยำยิ่งขึ้น นอกจากนี้ transfer learning จะช่วยให้โมเดลที่ผ่านการเทรนจากชุดข้อมูลหนึ่งสามารถปรับใช้กับแอสเซย์ใหม่ๆ ได้รวดเร็ว ลดเวลาสร้างข้อมูลฝึกสอนบนปัญหาเฉพาะ
การขยายผลสู่ขั้นตอนการผลิตก็เป็นแนวทางที่มีศักยภาพสูง: เทคนิค Bayesian optimization และระบบปิดวงจร (closed‑loop) สามารถนำมาใช้ในกระบวนการวิศวกรรมของการผลิตชีวภาพ เช่น การปรับพารามิเตอร์การเพาะเลี้ยงเซลล์ การควบคุมคุณภาพผลิตภัณฑ์ และการปรับสเกลจากห้องทดลองสู่โรงงาน ผลลัพธ์คือการลดเวลาช่วงเปลี่ยนผ่าน (scale‑up) ลดการใช้วัตถุดิบ และเพิ่มสเถียรภาพของกระบวนการผลิต
เพื่อให้การประยุกต์ใช้นวัตกรรมเหล่านี้ขยายตัวอย่างยั่งยืน ข้อเสนอเชิงนโยบายที่สำคัญ ได้แก่
- สนับสนุนทางการเงินและแรงจูงใจทางภาษี: ทุนสนับสนุน (grants) และเครดิตภาษีสำหรับการลงทุนในระบบอัตโนมัติและ AI‑driven R&D เพื่อลดความเสี่ยงเริ่มต้นของหน่วยงานวิจัยและสตาร์ทอัพ
- มาตรฐานข้อมูลและการแชร์ข้อมูล: ส่งเสริมมาตรฐาน metadata และการสร้างคลังข้อมูลเปิด (หรือแบบมีการควบคุม) เพื่อให้โมเดล ML สามารถเรียนรู้จากชุดข้อมูลที่มีคุณภาพและข้ามสถาบันได้
- กรอบกำกับดูแลที่เหมาะสม: วางหลักเกณฑ์สำหรับการยอมรับผลการทดลองที่ได้จากระบบอัตโนมัติและ AI ในขั้นตอนการอนุมัติวิจัยและการขึ้นทะเบียน เพื่อสร้างความเชื่อมั่นแก่ผู้ผลิตและหน่วยงานกำกับ
- พัฒนากำลังคนและความร่วมมือภาคประชา‑เอกชน: ลงทุนในการฝึกอบรมทักษะด้านวิศวกรรมชีวการแพทย์, วิทยาศาสตร์ข้อมูล และการพัฒนา AI พร้อมส่งเสริมทุนวิจัยร่วมระหว่างมหาวิทยาลัย สถาบันวิจัย และอุตสาหกรรม
- สร้างโครงการนำร่องและศูนย์ทดสอบ: จัดตั้ง testbed และศูนย์ประเมินเทคโนโลยีที่เปิดให้สตาร์ทอัพและสถาบันทดลองการใช้งานจริงก่อนการนำไปใช้ในวงกว้าง
โดยสรุป LabBench‑AI และเทคโนโลยีที่เกี่ยวข้องมีศักยภาพสูงในการย่นระยะเวลาและลดต้นทุนสำหรับการวิจัยยาในระดับชาติและภูมิภาค หากผนวกกับกลยุทธ์เชิงพาณิชย์ที่เหมาะสมและนโยบายสาธารณะที่สนับสนุน จะช่วยสร้างระบบนิเวศนวัตกรรมด้านชีวการแพทย์ที่เข้มแข็ง เพิ่มความสามารถในการแข่งขันของประเทศไทยในสายงานวิทยาศาสตร์ชีวภาพ และเปิดช่องทางการเติบโตเชิงเศรษฐกิจจากการแปรผลงานวิจัยสู่ผลิตภัณฑ์เชิงพาณิชย์
บทสรุป
เคสจากสถาบันวิจัยที่ใช้แพลตฟอร์ม LabBench‑AI แสดงให้เห็นว่า การผสานกันของ Active Learning สำหรับเลือกการทดลองที่มีประโยชน์สูงสุด, หุ่นยนต์จัดของเหลว (liquid‑handling robots) สำหรับการปฏิบัติการซ้ำได้และแม่นยำ และ Bayesian Optimization ในการปรับพารามิเตอร์เชิงประสิทธิภาพ สามารถย่อลูปการทดลองยาได้เหลือเพียง 1/5 ของรอบเดิม (คิดเป็นการลดเวลาและต้นทุนประมาณ 80%; ตัวอย่างเช่น ชุดการทดลองเดิม 100 รายการสามารถย่อลงเหลือประมาณ 20 รายการด้วยการเลือกเชิงคณิตศาสตร์และการอัตโนมัติ) พร้อมกับผลลัพธ์ที่มีความแม่นยำและความสามารถในการทำซ้ำ (reproducibility) เพิ่มขึ้นจากการควบคุมการจ่ายสารและการเลือกตัวอย่างเชิงข้อมูลอย่างเป็นระบบ
ทั้งนี้ แม้เทคโนโลยีดังกล่าวจะแสดงศักยภาพชัดเจน แต่ยังเผชิญข้อจำกัดทั้งด้านเทคนิคและกฎระเบียบ เช่น ความท้าทายในการผสานฮาร์ดแวร์หลายยี่ห้อ การประกันคุณภาพของแผ่นทดสอบ/แอนทิบอดี การจัดการข้อมูลขนาดใหญ่ตามหลัก FAIR และการยืนยันตามมาตรฐาน GLP/GMP เพื่อใช้ในเชิงคลินิก การออกแบบการทดลองที่ดี (Design of Experiments), การวางระบบจัดการข้อมูล (LIMS/ELN, metadata มาตรฐาน) และการทำงานร่วมกันแบบใกล้ชิดระหว่างนักวิจัยทดลองกับนักพัฒนาเทคโนโลยี/วิศวกรซอฟต์แวร์ เป็นปัจจัยชี้ขาดในการขยายผลสู่เชิงพาณิชย์และการประยุกต์ใช้ในวงกว้าง
มุมมองอนาคตชี้ว่าแพลตฟอร์มแบบผสมผสานนี้มีศักยภาพลดเวลาในการค้นยาและปรับปรุงกระบวนการพัฒนาได้อย่างมีนัยสำคัญ หากมีการลงทุนในมาตรฐานการตรวจสอบ การรับรองเวิร์กโฟลว์ และระบบบูรณาการข้อมูล คาดว่าจะเห็นการนำไปใช้มากขึ้นในห้องปฏิบัติการวิจัย, สตาร์ทอัพชีวเภสัชภัณฑ์ และผู้ให้บริการวิจัยเชิงสัญญา (CDMOs) ภายใน 2–5 ปีข้างหน้า โดยกุญแจสำคัญคือการออกแบบการทดลองเชิงสถิติ การบริหารข้อมูลที่เข้มแข็ง และความร่วมมือข้ามฝ่ายเพื่อเปลี่ยนผลลัพธ์จากเคสพิเศษให้กลายเป็นกระบวนการที่เชื่อถือได้และพร้อมสำหรับการนำไปใช้อย่างกว้างขวาง



