
การนำปัญญาประดิษฐ์เข้าสู่วงการแพทย์กำลังเร่งตัวอย่างรวดเร็วด้วยสัญญาณว่าจะช่วยเพิ่มประสิทธิภาพการวินิจฉัยและการรักษา แต่เบื้องหลังความคาดหวังนั้นคือความเสี่ยงจาก "ฮัลูซิเนชัน" — ข้อความหรือข้อสรุปที่โมเดลสร้างขึ้นมาโดยไม่มีความถูกต้องเชิงคลินิก งานวิจัยและการสำรวจระดับนานาชาติชี้ว่าอัตราการเกิดข้อมูลผิดพลาดจากโมเดลภาษาสำหรับงานเฉพาะทางอาจอยู่ในระดับหลักเปอร์เซ็นต์ถึงหลักสิบเปอร์เซ็นต์ ขึ้นกับประเภทข้อมูลและบริบทการใช้งาน ซึ่งหากนำไปใช้ในคลินิกโดยไม่ผ่านการประเมินอย่างเข้มงวดอาจก่อให้เกิดความเสี่ยงต่อผู้ป่วยและเสียความน่าเชื่อถือของระบบสุขภาพได้ง่าย
เพื่อตอบโจทย์ความท้าทายนี้ ราชวิทยาลัยแพทย์จึงร่วมมือกับสตาร์ทอัพเปิดโครงการ "Audit‑AI" ที่มุ่งเบนช์มาร์คการเกิดฮัลูซิเนชันและประเมินความปลอดภัยของโมเดลทางการแพทย์ทั้งในบริบทการรายงานผลห้องปฏิบัติการ รายงานรังสี และระบบสนับสนุนการตัดสินใจทางคลินิก โครงการนี้ไม่เพียงแต่จะทดสอบตัวชี้วัดความถูกต้องและความเสี่ยงเชิงเนื้อหาเท่านั้น แต่ยังเสนอแนวทางการรับรองก่อนนำโมเดลขึ้นใช้จริงในคลินิก เพื่อลดความเสี่ยง เพิ่มมาตรฐาน และสร้างความเชื่อมั่นให้กับบุคลากรทางการแพทย์และผู้ป่วย—ซึ่งบทความนี้จะพาไปดูรายละเอียด เป้าหมาย วิธีทดสอบ ตัวอย่างกรณีศึกษา และผลลัพธ์ที่คาดหวังจากโครงการ Audit‑AI
ภาพรวมโครงการ Audit‑AI
ภาพรวมโครงการ Audit‑AI
โครงการ Audit‑AI เป็นความร่วมมือเชิงยุทธศาสตร์ระหว่าง ราชวิทยาลัยแพทย์ กับ สตาร์ทอัพด้าน AI ทางการแพทย์ ที่มีเป้าหมายร่วมกันในการพัฒนากรอบเบนช์มาร์คเพื่อประเมิน hallucination และความปลอดภัยของโมเดลภาษาที่นำมาใช้ในบริบทคลินิก โดยความร่วมมือนี้ผสานความเชี่ยวชาญทางคลินิกของราชวิทยาลัยกับความสามารถด้านวิศวกรรมและการประเมินประสิทธิภาพของสตาร์ทอัพ เพื่อให้เกิดทั้งมาตรฐานเชิงเทคนิคและแนวปฏิบัติที่สอดคล้องกับการดูแลผู้ป่วยจริง

ความเป็นมาของโครงการเริ่มจากความตระหนักว่าการนำโมเดล AI เข้าสู่การดูแลผู้ป่วยมีความเสี่ยงจากข้อผิดพลาดเชิงเนื้อหา (hallucination) และปัญหาความไม่แน่นอนของโมเดล งานวิจัยเชิงประเมินหลายชิ้นชี้ว่าโมเดลภาษาขนาดใหญ่ในงานทางการแพทย์อาจแสดงข้อเท็จจริงผิดพลาดหรือให้คำแนะนำที่ไม่สอดคล้องกับมาตรฐานทางการแพทย์ในสัดส่วนที่มีนัยสำคัญ (ตัวอย่างเช่นระดับความผิดพลาดโดยประมาณในกลุ่มงานบางประเภทอาจอยู่ระหว่าง 10–30%) ทำให้เกิดความจำเป็นต้องมีเบนช์มาร์คและกระบวนการรับรองก่อนใช้งานจริงในคลินิก
วัตถุประสงค์หลักของโครงการสรุปเป็นข้อๆ ได้ดังนี้
- ตรวจจับ hallucination โดยพัฒนาชุดข้อมูลทดสอบ (benchmark dataset) ที่ประกอบด้วยกรณีตัวอย่างทางคลินิกจริงที่ผ่านการลบข้อมูลระบุตัวบุคคลและตรวจสอบโดยผู้เชี่ยวชาญ เพื่อวัดอัตราความคลาดเคลื่อนของข้อมูลและข้อเสนอแนะที่สร้างโดยโมเดล
- ประเมินความปลอดภัย ทั้งในแง่เนื้อหา (เช่นคำแนะนำการรักษาที่ถูกต้องและไม่เป็นอันตราย) และแง่การทำงาน (เช่นความทนทานต่อคำถามนอกขอบเขต ความสามารถในการระบุความไม่แน่นอน)
- สร้างแนวทางรับรองก่อนขึ้นใช้ในคลินิก ซึ่งรวมถึงเกณฑ์การผ่านการทดสอบ เช่นเกณฑ์ความแม่นยำ/ความผิดพลาดที่ยอมรับได้ การมีระบบตรวจสอบโดยบุคลากรทางการแพทย์ (human‑in‑the‑loop) และแผนการติดตามหลังการใช้งาน (post‑deployment monitoring)
โครงการตั้งเป้าผลลัพธ์เชิงปฏิบัติไว้ชัดเจน ได้แก่ การลดอัตรา hallucination ของโมเดลลงอย่างมีนัยสำคัญก่อน deployment (เป้าหมายเชิงตัวเลขเบื้องต้นคือการลดอัตราความผิดพลาดลงมากกว่า 30% ภายในเฟสการทดสอบแรก) การกำหนดชุดเมตริกความปลอดภัย (เช่น precision/recall สำหรับข้อความเชิงข้อเท็จจริง, calibration error, OOD detection rate) และการออกเอกสารแนวปฏิบัติการรับรองที่สามารถอ้างอิงได้โดยหน่วยงานสาธารณสุขหรือสถานพยาบาล
โครงสร้างการทำงานของ Audit‑AI จะประกอบด้วยส่วนสำคัญคือ
- การจัดทำและตรวจสอบชุดข้อมูลทดสอบโดยทีมแพทย์และนักระบาดวิทยา
- การออกแบบสถานการณ์ทดสอบเชิงปฏิบัติ (clinical vignettes, adversarial prompts, edge cases)
- การประเมินเชิงปริมาณด้วยเมตริกมาตรฐานและเมตริกเฉพาะทางการแพทย์
- การกำหนดขั้นตอนการรับรองก่อนใช้งานจริง รวมทั้งข้อกำหนดด้านการรายงานเหตุการณ์ไม่พึงประสงค์ และกลไก human‑in‑loop
ผลลัพธ์ที่คาดหวังจากโครงการคือ การเพิ่มความน่าเชื่อถือของโมเดล AI ทางการแพทย์ การลดความเสี่ยงต่อผู้ป่วยและสถาบันที่นำระบบไปใช้ และการสร้างมาตรฐานที่ชัดเจนสำหรับการนำระบบ AI ขึ้นใช้ในคลินิกจริงในประเทศ โดยคาดว่าเมื่อผ่านแนวทางของ Audit‑AI แล้ว ผู้ประกอบการและสถานพยาบาลจะมีกรอบการตัดสินใจที่ชัดเจนมากขึ้น ทำให้เวลาในการนำระบบไปใช้ลดลงและความเสี่ยงด้านกฎหมายและจริยธรรมลดลงเช่นกัน
ทำไมต้องแก้ปัญหา hallucination และความปลอดภัยใน AI ทางการแพทย์
ทำไมต้องแก้ปัญหา hallucination และความปลอดภัยใน AI ทางการแพทย์
Hallucination ในบริบทของโมเดลปัญญาประดิษฐ์ทางภาษา หมายถึงการที่โมเดลสร้างข้อเท็จจริงเท็จ ข้อมูลที่ไม่ตรงกับหลักฐานทางการแพทย์ หรือให้คำแนะนำที่ผิดพลาดโดยไม่มีแหล่งอ้างอิงที่ถูกต้อง การเกิด hallucination ไม่ใช่เพียงปัญหาทางภาษาศาสตร์เท่านั้น แต่มีผลโดยตรงต่อการดูแลผู้ป่วยเมื่อเทคโนโลยีเหล่านี้ถูกนำไปใช้ในการสนับสนุนการวินิจฉัย การให้คำแนะนำการรักษา หรือการสื่อสารผลการตรวจกับผู้ป่วย
ความเสี่ยงเชิงปฏิบัติและความปลอดภัยที่เกิดจาก hallucination มีหลายด้านที่ต้องพิจารณาอย่างจริงจัง ได้แก่
- การวินิจฉัยผิดพลาด — ข้อเสนอแนะหรือการตีความผลทดสอบที่ไม่ถูกต้องอาจนำไปสู่การวินิจฉัยที่ผิด ทำให้ผู้ป่วยไม่ได้รับการรักษาที่เหมาะสม
- การให้การรักษาไม่เหมาะสม — คำแนะนำทางยา ขนาดยาหรือการผ่าตัดที่โมเดลเสนอหากผิดพลาดอาจก่อให้เกิดอันตรายต่อผู้ป่วยได้โดยตรง
- การสูญเสียความเชื่อมั่น — ทั้งผู้ป่วยและบุคลากรทางการแพทย์อาจสูญเสียความเชื่อมั่นต่อระบบดิจิทัลและเทคโนโลยีใหม่ ๆ หากเกิดข้อผิดพลาดซ้ำ ๆ
- ภาระและค่าใช้จ่ายต่อระบบสาธารณสุข — การแก้ไขข้อผิดพลาด การทดสอบซ้ำ หรือการรักษาแทรกซ้อนที่เกิดจากข้อมูลเท็จเพิ่มภาระและต้นทุน
งานวิจัยหลายชิ้นแสดงให้เห็นว่าอัตราการเกิด hallucination แตกต่างกันไปตามลักษณะงานและชุดข้อมูลที่ใช้ประเมิน โดยมีรายงานอัตราตั้งแต่ ประมาณ 2–20% ขึ้นไปในงานทดสอบบางประเภท ตัวอย่างเช่น แบบจำลองอาจให้คำตอบผิดพลาดในเชิงข้อเท็จจริงหรือสร้างการอ้างอิงทางวรรณกรรมที่ไม่มีอยู่จริง ซึ่งการเบี่ยงเบนเหล่านี้มักเพิ่มขึ้นเมื่อคำถามต้องการความแม่นยำระดับคลินิกหรือเมื่อต้องอ้างอิงหลักฐานวิชาการที่เฉพาะเจาะจง
มีตัวอย่างและกรณีศึกษาที่ชี้ให้เห็นถึงผลกระทบจริง เช่น รายงานข่าวและการประเมินจากหน่วยงานอิสระที่พบระบบช่วยตัดสินใจทางการแพทย์บางรุ่นให้คำแนะนำไม่สอดคล้องกับแนวทางทางคลินิก และงานทดลองเชิงวิชาการพบว่าโมเดลภาษาใหญ่มักสร้างการอ้างอิงหรือสถิติที่ไม่ได้มีหลักฐานรองรับ ผลกระทบเชิงลบที่อาจตามมารวมถึงการเกิดภาวะแทรกซ้อนเพิ่มขึ้น ความจำเป็นในการรักษาทดแทน และปัญหาทางกฎหมายหรือความรับผิดชอบต่อผู้ป่วย
ด้วยเหตุนี้ การพัฒนาเกณฑ์การตรวจสอบ (audit) และมาตรการรับรองความปลอดภัยก่อนนำโมเดลขึ้นใช้ในคลินิกเป็นเรื่องจำเป็นอย่างยิ่ง โครงการเช่น "Audit‑AI" ที่มุ่งประเมินระดับ hallucination และความปลอดภัยจะช่วยลดความเสี่ยง สร้างความเชื่อมั่น และประกันว่าเทคโนโลยีที่นำมาใช้สอดคล้องกับหลักฐานทางการแพทย์ มาตรฐานด้านจริยธรรม และข้อกำหนดด้านกฎหมาย เพื่อปกป้องผู้ป่วยและรักษาเสถียรภาพของระบบสาธารณสุข
สถาปัตยกรรมการประเมินและเมตริกของ Audit‑AI
ภาพรวมสถาปัตยกรรมการประเมิน (Evaluation Pipeline)
สถาปัตยกรรมการประเมินของโครงการ Audit‑AI ถูกออกแบบเป็น pipeline เชิงระบบที่ประกอบด้วยขั้นตอนตั้งแต่การจัดการข้อมูล (data ingestion) จนถึงการตัดสินผลแบบ decision gate ก่อนนำโมเดลขึ้นใช้ในคลินิก โดยหลักๆ จะแบ่งออกเป็น: การเตรียมชุดข้อมูล (dataset curation and splitting), การทดสอบหน่วย (unit tests), การทดสอบเชิงสถานการณ์ทางคลินิก (scenario‑based clinical vignettes), การทดสอบเชิงปรปักษ์และ edge‑case (adversarial/edge‑case evaluation) และการวัดผลด้วยเมตริกเชิงปริมาณและเชิงคุณภาพ (quantitative & qualitative metrics).
Dataset: การแบ่งชุดข้อมูลและมาตรการคุ้มครองข้อมูล
ชุดข้อมูลสำหรับการประเมินรวมเคสจริงจากหลายโรงพยาบาล (multi‑center) ที่ผ่านการ de‑identified และการอนุมัติเจ้าของข้อมูลแล้ว ตัวอย่างมาตรฐานการจัดสรรชุดข้อมูลภายใน Audit‑AI คือ:
- แหล่งข้อมูล: ตัวอย่างสมมติ: 200,000 encounter records จาก 8–12 โรงพยาบาล ครอบคลุม OPD, ED, inpatient และ PACS images (ถ้ามี)
- การแบ่งสัดส่วน: train 70%, validation 15%, test 15% โดยแยกชุด external holdout ที่มาจากโรงพยาบาลที่ไม่ได้ใช้ในการฝึกจริง (external test set) เพื่อประเมินการ generalize
- การปกป้องข้อมูล: การ de‑identification ตามมาตรฐาน (HIPAA‑like) และการตรวจสอบ re‑identification risk ก่อนนำเข้า pipeline
- การทำสมดุล: oversampling/stratification สำหรับเคสความถี่ต่ำ (rare conditions) เพื่อให้ชุดทดสอบครอบคลุม edge‑case ที่สำคัญ
ขั้นตอนการทดสอบ (Testing Stages)
Pipeline แยกการทดสอบเป็นชั้นชัดเจนเพื่อลดความเสี่ยงก่อนใช้งานจริง:
- Unit tests: ตรวจความสอดคล้องของ input/output, validation ของ input schema, ตรวจ path ของ error handling, tests สำหรับ safety filters และ response time (latency) — ตัวอย่างเช่น ตรวจว่าโมเดลไม่ให้คำแนะนำยาเกินขนาดภายในกรอบคำถามพื้นฐาน
- Scenario‑based clinical vignettes: ชุดบทบาทจำลองเชิงคลินิกที่เขียนขึ้นโดยแพทย์ผู้เชี่ยวชาญ ครอบคลุมเคสปกติ เคสซับซ้อน เคสมีโรคร่วม และเคสที่อาจมีประเด็นทางจริยธรรม เช่น การตัดสินใจก่อนผ่าตัด
- Adversarial / edge‑case evaluation: การโจมตีเชิงปรปักษ์ (prompt injection, out‑of‑distribution inputs, noisy/no‑signal data, corrupted images), การทดสอบ robustness ต่อการเปลี่ยนรูปแบบภาษาหรือหน่วยวัด และการทดสอบ hallucination induction (เช่น ตั้งคำถามที่ปลายเหตุเพื่อยั่วยุให้โมเดลสร้างข้อเท็จจริงปลอม)
- Clinical simulation: การรันในสภาพแวดล้อมจำลองที่มี clinician-in‑the‑loop เพื่อตรวจดู workflow impact, false alarm burden และ usability ในสถานการณ์จริง
เมตริกเชิงปริมาณและเชิงคุณภาพ
การประเมินทั้งเชิงสถิติและเชิงคุณภาพจำเป็นต่อการประกันความปลอดภัยและความน่าเชื่อถือของโมเดลทางการแพทย์:
- สถิติพื้นฐาน: Sensitivity (Recall), Specificity, Positive Predictive Value (PPV), Negative Predictive Value (NPV) — คำนวณพร้อมช่วงความเชื่อมั่น (95% CI) โดยคำนึงถึง prevalence ในแต่ละชุดข้อมูล
- AUC / ROC: ใช้ประเมินความสามารถแยกแยะระหว่างผลบวกและผลลบในเคสที่เป็น continuous or probabilistic outputs
- Calibration metrics: Brier score, Expected Calibration Error (ECE), calibration‑in‑the‑large — ตัวชี้วัดว่า probabilistic output ของโมเดลสอดคล้องกับความน่าจะเป็นจริงหรือไม่ (เช่น ECE ≤ 0.05 เป็นตัวอย่างเกณฑ์ที่ยอมรับได้ในหลายกรณี)
- Hallucination rate: สัดส่วนของคำตอบที่ประกอบด้วยข้อเท็จจริงที่ไม่สามารถยืนยันได้จากข้อมูลอ้างอิง — วัดด้วยการตรวจมือ (human annotation) หรือการเทียบกับ gold standard; เป้าหมายทั่วไป ≤ 1–2% สำหรับระบบที่ให้คำแนะนำทางคลินิก
- Robustness score (เชิงผสม): ดัชนีรวมที่คำนวณจากความเปลี่ยนแปลงของประสิทธิภาพภายใต้ perturbations (noise, OOD, adversarial) เช่น ความต่างของ AUC หรือ sensitivity เมื่อมีการเบลอภาพ/เปลี่ยนหน่วยวัด — ให้คะแนนเป็น 0–100
- เชิงคุณภาพ: Explainability (ความสามารถในการให้เหตุผลที่เข้าใจได้), Clinical plausibility (ความสอดคล้องกับองค์ความรู้ทางการแพทย์), และ human‑review concordance (สัดส่วนที่ผลลัพธ์สอดคล้องกับผู้เชี่ยวชาญ)
การนิยามและตัวอย่างเกณฑ์ผ่าน/ไม่ผ่าน
เพื่อให้การตัดสินชัดเจน Audit‑AI กำหนดเกณฑ์ตัวอย่างสำหรับการผ่านขั้นตอนรับรองก่อน deployment:
- ตัวอย่างเกณฑ์ผ่าน (example pass):
- Sensitivity ≥ 0.90 และ Specificity ≥ 0.85 ในกลุ่มเคส high‑risk screening (พร้อม 95% CI ที่ไม่ทับเกณฑ์ที่กำหนด)
- AUC ≥ 0.92 บน external holdout hospital set
- ECE ≤ 0.05 และ Brier score ลดลงจาก baseline อย่างมีนัยสำคัญทางสถิติ (p < 0.05)
- Hallucination rate ≤ 1% ในชุดทดสอบที่มีการตรวจสอบด้วยมือ
- Robustness score ≥ 80 (การลดประสิทธิภาพไม่เกิน 10% ภายใต้ perturbations ที่กำหนด)
- การประเมินเชิงคุณภาพ: >= 85% concordance กับ panel ของแพทย์ใน vignettes
- ตัวอย่างเกณฑ์ไม่ผ่าน (example fail):
- Sensitivity < 0.80 สำหรับการคัดกรองโรคที่มีความเสี่ยงสูง หรือ drop ของ sensitivity > 15% บน external site
- AUC ลดลงอย่างมีนัยสำคัญเมื่อทดสอบกับ OOD data (เช่น AUC จาก 0.92 → 0.78)
- ECE > 0.10 หรือมีการ over‑/under‑confidence ที่อาจนำไปสู่การตัดสินใจรักษาที่เป็นอันตราย
- Hallucination rate > 5% ในกรณีที่มีการยืนยันข้อเท็จจริงได้ (unacceptable factual errors)
- ความไม่สอดคล้องเชิงคลินิกมากกว่า 20% ใน panel review (clinical plausibility fail)
การวัดความไม่แน่นอนและการทดสอบเชิงสถิติ
Audit‑AI นำแนวปฏิบัติทางสถิติ เช่น bootstrap resampling เพื่อคำนวณความไม่แน่นอนของเมตริก, hypothesis testing สำหรับเปรียบเทียบกับ baseline และการวิเคราะห์ subpopulation (age, sex, ethnicity, comorbidity) เพื่อตรวจสอบ bias และ fairness นอกจากนี้ระบบยังรายงาน failure modes ที่พบพร้อมแผน mitigations ก่อนอนุญาตใช้จริง
บทส่งท้าย
สถาปัตยกรรมการประเมินของ Audit‑AI ออกแบบมาให้เป็นกระบวนการซ้ำ (iterative) ที่ผสานทั้งการวัดเชิงปริมาณและการประเมินเชิงคุณภาพ เพื่อให้มั่นใจว่าโมเดลทางการแพทย์ที่ผ่านการรับรองจะมีความถูกต้อง น่าเชื่อถือ และปลอดภัยเมื่อใช้งานกับผู้ป่วยจริง โดยทุกการผ่านเกณฑ์ต้องมาพร้อมเอกสารพิสูจน์ (audit trail) และแผนการติดตามหลัง deployment (post‑deployment monitoring)
แนวทางรับรองก่อนนำขึ้นใช้ในคลินิก (Certification Workflow)
แนวทางรับรองก่อนนำขึ้นใช้ในคลินิก (Certification Workflow)
เพื่อให้การนำโมเดลปัญญาประดิษฐ์ทางการแพทย์ขึ้นใช้ในสภาพแวดล้อมคลินิกเป็นไปอย่างปลอดภัย มีประสิทธิภาพ และรับผิดชอบ ราชวิทยาลัยฯ ร่วมกับหน่วยงานที่เกี่ยวข้องได้กำหนดกระบวนการรับรอง (Certification Workflow) ที่ครอบคลุมตั้งแต่การประเมินก่อนขึ้นใช้จนถึงการติดตามหลังการขึ้นใช้ โดยเน้นหลักสำคัญ 4 ด้าน ได้แก่ ประสิทธิภาพและมาตรฐานความปลอดภัย (performance & safety), ความโปร่งใสและการอธิบายการตัดสินใจ (explainability), การบริหารข้อมูล (data governance) และบทบาทการแทรกแซงของมนุษย์ (human‑in‑the‑loop) กระบวนการนี้ออกแบบมาเพื่อรองรับทั้งโมเดลที่มีความเสี่ยงปานกลางถึงสูง และสามารถปรับเกณฑ์ตามลักษณะการใช้งาน (intended use) ได้อย่างยืดหยุ่น
Pre‑deployment checklist — ก่อนออกใบอนุญาตใช้งาน จะต้องผ่านรายการตรวจสอบที่เป็นข้อบังคับซึ่งประกอบด้วยข้อกำหนดเชิงปริมาณและเชิงคุณภาพ ดังนี้
- เกณฑ์ประสิทธิภาพเชิงสถิติ (Performance thresholds): กำหนดค่าเกณฑ์ขั้นต่ำที่ชัดเจนตามผลกระทบทางคลินิก เช่น sensitivity, specificity, positive predictive value (PPV), negative predictive value (NPV), area under ROC (AUC) และ calibration error โดยตัวอย่างเช่น สำหรับระบบคัดกรองที่มีผลต่อการตัดสินใจทางการแพทย์ขั้นต้น อาจกำหนด sensitivity ≥ 90% หรือ AUC ≥ 0.85 ขึ้นกับความเสี่ยงของผิดพลาด แต่ต้องมีการระบุเกณฑ์เฉพาะใน Intended Use Statement
- การทดสอบความปลอดภัย (Safety tests): ประเมิน failure modes, worst‑case scenarios, adversarial robustness, และ stress‑testing ต่อกลุ่มผู้ป่วยย่อย (subpopulations) โดยต้องทดสอบกับชุดข้อมูลภายนอกจากสถานพยาบาล ≥ 2 แห่ง และขนาดตัวอย่างที่เหมาะสม (ตัวอย่างเช่นอย่างน้อย 1,000 เคสสำหรับโมเดลความเสี่ยงปานกลาง และ ≥ 3,000 เคสสำหรับระบบความเสี่ยงสูง)
- ความโปร่งใสและการอธิบายผล (Explainability): ต้องมีเครื่องมืออธิบายการตัดสินใจที่เหมาะสม เช่น saliency maps, feature‑attribution, counterfactual examples และมาตรการประเมินคุณภาพคำอธิบาย เพื่อให้ผู้ใช้งานทางการแพทย์เข้าใจขอบเขตความเชื่อมั่นและข้อจำกัดของคำตอบ
- การบริหารข้อมูลและความเป็นส่วนตัว (Data governance): ระบุแหล่งที่มาของข้อมูล (provenance), การทำให้เป็นนิรนาม (de‑identification), นโยบายการเก็บรักษา, การจัดการ bias และการทำ audit trail ของการใช้ข้อมูลตามกฎหมายคุ้มครองข้อมูลส่วนบุคคล
- การทดสอบการทำงานร่วมกับระบบคลินิก (Integration testing): ตรวจสอบการทำงานกับ EMR/PACS, latency ในการตอบกลับ, และการจัดการข้อผิดพลาดเมื่อระบบภายนอกล้มเหลว
การทดสอบที่ต้องทำ (Required tests) — รายงานการทดสอบต้องรวมผลการทดสอบเชิงปริมาณและเชิงคุณภาพ ได้แก่ validation ภายนอก (external validation), subgroup analysis (ตามเพศ อายุ เชื้อชาติ/ชาติพันธุ์ โรคประจำตัว), temporal validation, robustness checks ต่อสภาวะข้อมูลที่เปลี่ยนแปลง และการทดสอบการใช้งานจริงในสภาพแวดล้อมคลินิก (prospective clinical pilot) โดยการทดลองภาคสนามควรมีตัวชี้วัดด้านผลลัพธ์ผู้ป่วย (patient‑level outcomes) เช่น การลดเวลาในการวินิจฉัยหรือการเปลี่ยนแปลงแนวทางการรักษา
Human‑in‑the‑loop และระดับการแทรกแซงของบุคลากรทางการแพทย์
- ระดับ Advisory (คำแนะนำ): โมเดลทำหน้าที่ให้ข้อมูลเชิงสนับสนุนแก่แพทย์ — ผลลัพธ์ถูกนำเสนอพร้อมเหตุผลหรือหลักฐานสนับสนุน แพทย์เป็นผู้ตัดสินใจสุดท้าย เหมาะกับงานที่มีความเสี่ยงต่ำถึงปานกลาง
- ระดับ Assisted‑Decision (ช่วยตัดสินใจ): โมเดลเสนอการตีความผลที่มีน้ำหนักและแจ้งเตือนเมื่อมีความเสี่ยงสูง แพทย์ต้องยืนยันหรือปรับผลก่อนดำเนินการทางคลินิก — เหมาะกับงานที่มีผลต่อการรักษาโดยตรง
- ระดับ Human‑confirmation / Gatekeeping (ยืนยันโดยมนุษย์): ผลการประมวลผลไม่สามารถนำไปใช้โดยอัตโนมัติ ต้องได้รับการยืนยันจากบุคลากรที่ได้รับอนุญาตก่อนดำเนินการใด ๆ — เหมาะกับระบบที่มีความเสี่ยงสูงหรือมีผลต่อชีวิตผู้ป่วย
- ระดับ Autonomous with monitoring (อัตโนมัติภายใต้การเฝ้าติดตาม): เฉพาะกรณีที่มีหลักฐานประสิทธิภาพและความปลอดภัยสูงมาก พร้อมแผนการเฝ้าระวังขั้นสูงและกลไก rollback อัตโนมัติเมื่อพบเบี่ยงเบน
การจัดการความรับผิดชอบ (Accountability & Governance) — ก่อนให้อนุญาตใช้งานต้องระบุความรับผิดชอบของแต่ละฝ่ายอย่างชัดเจน ได้แก่ ผู้พัฒนา (developer), ผู้ให้บริการระบบ (vendor), ผู้ดำเนินการคลินิก (healthcare provider) และบุคลากรทางการแพทย์ โดยต้องกำหนดนโยบายการรายงานเหตุการณ์ไม่พึงประสงค์ (adverse event reporting), กลไกการชดเชย (liability/indemnity), และแผนรับมือเมื่อโมเดลทำงานผิดพลาด (incident response plan)
เอกสารรับรองที่ออกโดยราชวิทยาลัย — เมื่อตรวจสอบครบถ้วน ราชวิทยาลัยจะออกเอกสารรับรองที่ประกอบด้วยอย่างน้อย:
- รายงานการทดสอบฉบับเต็ม (Test Report): สรุปผลการ validation, subgroup analysis, stress tests และการทดลองภาคสนาม รวมถึงตัวอย่างข้อมูลที่ใช้ทดสอบและเมตริกที่ยอมรับได้
- เงื่อนไขการใช้งาน (Conditions of Use / Intended Use Statement): ระบุขอบเขตการใช้งานที่อนุญาต (indications, contraindications), กลุ่มประชากรที่เหมาะสม และข้อห้ามชัดเจน
- แผนการติดตามหลังขึ้นใช้ (Post‑deployment Monitoring Plan): กำหนดตัวชี้วัด (KPIs) สำหรับการติดตามความถูกต้องและความปลอดภัยแบบเรียลไทม์, ความถี่ในการรีพอร์ต, เกณฑ์การแจ้งเตือน และกระบวนการรีคาร์ตีฟิเคชัน (re‑certification) เช่น การประเมินซ้ำเป็นประจำทุกปีหรือเมื่อมีการเปลี่ยนแปลงโมเดล
นอกจากนี้ ราชวิทยาลัยอาจออกใบรับรองแบบมีเงื่อนไข (conditional approval) สำหรับการนำร่องในระยะสั้น โดยมีข้อผูกมัดด้านการเก็บข้อมูลเพิ่มเติมและการส่งผลการใช้จริงกลับมาเป็นประเด็นหนึ่งของการพิจารณาอนุญาตถาวร สำหรับโมเดลที่มีคุณสมบัติการเรียนรู้ต่อเนื่อง (continuous learning) จะต้องมีกระบวนการควบคุมการเปลี่ยนแปลง (change management) รวมถึงขอบเขตที่ต้องได้รับการอนุมัติใหม่ก่อนปล่อยใช้งาน
โดยสรุป กระบวนการรับรองก่อนนำขึ้นใช้ในคลินิกของโครงการ Audit‑AI มุ่งเน้นความเป็นระบบ โปร่งใส และมีความรับผิดชอบสูง เพื่อให้การประยุกต์ใช้ AI ในการดูแลผู้ป่วยเกิดประโยชน์สูงสุด ลดความเสี่ยงต่อผู้ป่วย และสร้างความเชื่อมั่นให้กับบุคลากรทางการแพทย์และสาธารณชน
ผลลัพธ์นำร่องและสถิติที่น่าสนใจ
ผลลัพธ์นำร่องและสถิติที่น่าสนใจ
การทดสอบนำร่องของโครงการ Audit‑AI ดำเนินการบนชุดข้อมูลจำลองและข้อมูลทางคลินิกจริงรวมกัน (ชุดนำร่อง: n=1,200 คำถามคลินิก และชุดย่อยในห้องฉุกเฉิน n=450 กรณี) โดยมุ่งประเมินทั้งความถูกต้องของคำตอบ ความสอดคล้องของการคาดการณ์ (calibration) และอัตรา hallucination ก่อน–หลังการปรับแต่งโมเดลและการติดตั้งกลไกการตรวจสอบของผู้เชี่ยวชาญ ผลการทดสอบชี้ให้เห็นการเปลี่ยนแปลงเชิงบวกที่เป็นรูปธรรม ทั้งในการลดความผิดพลาดประเภทให้ข้อมูลเท็จ และการปรับปรุงสมรรถนะเชิงวินิจฉัยที่มีนัยยะต่อการใช้งานในคลินิก
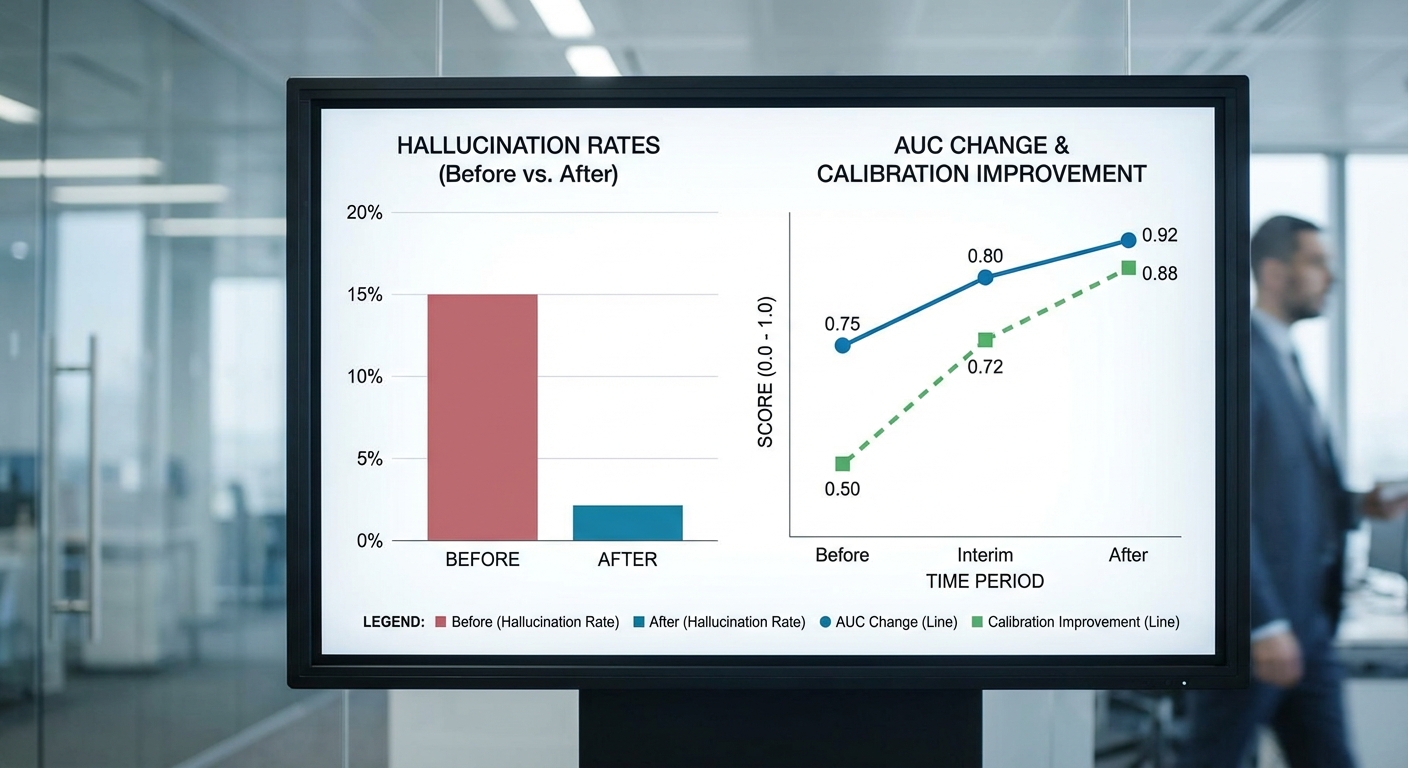
สรุปผลเชิงตัวเลขที่สำคัญ ได้แก่การลดอัตรา hallucination จากเดิม 12% ลดลงเป็น 3% หลังการนำระบบตรวจสอบร่วมกับผู้เชี่ยวชาญและการปรับค่า threshold ของโมเดลไว้ในกระบวนการ (pre‑post comparison ในชุดนำร่อง) ขณะเดียวกันค่าประสิทธิภาพเชิงจำแนก (AUC) ปรับเพิ่มขึ้นโดยเฉลี่ย +0.05 และค่าความผิดพลาดด้านการปรับเทียบ (calibration error) ลดลงประมาณ 30% ซึ่งสะท้อนว่าค่าความเสี่ยงที่โมเดลรายงานมีความสอดคล้องกับความน่าจะเป็นจริงมากขึ้น
- Hallucination: ลดจาก 12% → 3% หลังการปรับและการตรวจสอบด้วย clinician-in-the-loop
- AUC (Area Under ROC): เพิ่มขึ้นเฉลี่ย +0.05 (ค่าความแตกต่างมีความสำคัญทางคลินิกในหลายงานคัดกรอง)
- Calibration error: ลดลงประมาณ 30% ทำให้การตีความความเสี่ยงเป็นไปในเชิงปฏิบัติได้มากขึ้น
- การตอบสนองในห้องฉุกเฉิน (ED): เวลาการตัดสินใจโดยเฉลี่ยลดลงอย่างมีนัยสำคัญ แต่การยืนยันโดยแพทย์ยังคงจำเป็น
กรณีศึกษาเชิงคลินิกจากชุดย่อยห้องฉุกเฉิน (n=450) แสดงให้เห็นว่าเมื่อใช้โมเดลเป็นตัวช่วยคัดกรองเบื้องต้น เวลาเฉลี่ยในการตัดสินใจเบื้องต้นลดลงประมาณ 20% (ตัวอย่างเช่น จากเฉลี่ย 40 นาที เหลือ 32 นาที) โดยโมเดลจะนำเสนอ differential diagnosis และระดับความเสี่ยงพร้อมสัญญาณเตือนสำหรับเคสที่มีความไม่แน่นอนสูง อย่างไรก็ตาม ทีมแพทย์ที่ร่วมทดสอบยืนยันว่า การยืนยันโดย clinician เป็นขั้นตอนบังคับก่อนการเปลี่ยนแปลงแผนการรักษา เพื่อป้องกันผลลัพธ์ที่เกิดจาก hallucination หรือการตีความผิดของโมเดลในบริบทเฉพาะเคส
ผลลัพธ์นำร่องนี้ให้ข้อสรุปเชิงนโยบายที่ชัดเจน: แม้เทคนิคการปรับแต่งและการตรวจสอบจะสามารถลดความเสี่ยงและยกระดับประสิทธิภาพของโมเดลได้อย่างมีนัยสำคัญ การนำไปใช้จริงในคลินิกต้องมีกระบวนการรับรองที่รวม clinician‑in‑the‑loop, การมอนิเตอร์ต่อเนื่อง และเกณฑ์การปล่อยใช้งานที่ชัดเจน ข้อแนะนำเชิงปฏิบัติสำหรับรอบถัดไปคือการขยายการทดสอบกับข้อมูลจากหน่วยบริการที่หลากหลาย เพิ่มขนาดตัวอย่างเพื่อตรวจสอบความคงที่ของผล และพัฒนาชุดมาตรฐานการวัดที่รองรับการรับรองก่อนนำขึ้นใช้งานจริง
การนำ Audit‑AI ไปสู่การใช้งานจริงในคลินิกและการฝึกอบรม
การติดตั้งและการเชื่อมต่อระบบ (Integration)
ก่อนนำระบบ Audit‑AI ขึ้นใช้ในคลินิก ต้องออกแบบสถาปัตยกรรมการเชื่อมต่อกับระบบสารสนเทศสุขภาพของโรงพยาบาล (EHR) อย่างรัดกุม โดยคำนึงถึงมาตรฐานการสื่อสารข้อมูล เช่น HL7 FHIR, SMART on FHIR สำหรับข้อมูลเชิงโครงสร้าง และ DICOM สำหรับภาพถ่ายทางการแพทย์ ระบบควรให้การเข้าถึงผ่าน RESTful API ที่รองรับการพิสูจน์ตัวตนด้วยมาตรฐานเช่น OAuth2/ OpenID Connect เพื่อความปลอดภัยในการเข้าถึงข้อมูลผู้ป่วย
การนำข้อมูลไปใช้เพื่อประเมินและปรับปรุงโมเดลจะต้องใช้ข้อมูลที่ de‑identified หรือผ่านกระบวนการ pseudonymization ตามนโยบายคุ้มครองข้อมูลส่วนบุคคลของประเทศ ตัวอย่างการปฏิบัติที่แนะนำได้แก่ การ hash/replace รหัสประจำตัวผู้ป่วย การลบข้อมูลที่สามารถระบุตัวตนได้ และการเก็บ log การเข้าถึงข้อมูลเป็น audit trail เพื่อการตรวจสอบย้อนหลัง
การฝึกอบรมบุคลากร (Training & Competency)
การฝึกอบรมต้องเป็นระบบ มีทั้งทฤษฎีและการปฏิบัติจริง โดยจัดเป็นชุดกิจกรรมขั้นต่ำ:
- Workshop เบื้องต้น — แนะนำหลักการทำงานของ Audit‑AI, ข้อจำกัด, และแนวทางการตีความผลลัพธ์ (ครอบคลุมทั้งแพทย์ พยาบาล และทีมไอที)
- Simulation — ฝึกสถานการณ์จำลอง (เช่น เคสฉุกเฉินหรือเคสที่ AI ให้ผลขัดแย้งกับการวินิจฉัยของแพทย์) เพื่อฝึกการตัดสินใจร่วมมนุษย์‑เครื่อง
- Checklist สำหรับ clinician — แบบฟอร์มยืนยันผล (pre‑action checklist) ที่ clinician ต้องกรอกก่อนยอมรับคำแนะนำจาก AI เช่น ยืนยันว่าได้ตรวจภาพ/ผลทางห้องปฏิบัติการประกอบ และระบุเหตุผลหากไม่ยอมรับผล AI
ตัวอย่าง checklist สั้น ๆ สำหรับการใช้ AI ในการอ่านภาพรังสี:
- ยืนยันตัวผู้ป่วยและชนิดภาพถูกต้อง
- ตรวจสอบ confidence score ของโมเดล (ถ้ามี) และประกอบด้วยข้อมูลทางคลินิกหรือไม่
- หากผล AI ขัดแย้งกับการประเมินของแพทย์ ให้บันทึกเหตุผลและเลือกดำเนินการตรวจซ้ำหรือขอความคิดเห็นที่สอง
การวัดผลการฝึกอบรมควรมีทั้งแบบฟอร์มประเมินความสามารถ (competency assessment) และการทดสอบตามสถานการณ์จริง โดยตั้งเป้าให้บุคลากรสำเร็จการฝึกภายใน 4–8 สัปดาห์หลังติดตั้งระบบ และทวนอบรมประจำปี
ระบบมอนิเตอร์หลังขึ้นใช้ (Post‑deployment Monitoring)
หลังการขึ้นใช้ Audit‑AI ต้องมีชั้นการมอนิเตอร์ที่ครอบคลุมทั้งแบบเรียลไทม์และเป็นระยะ เพื่อจับสัญญาณการเสื่อมของประสิทธิภาพ (model drift) และเหตุการณ์ความไม่ปลอดภัย
- Real‑time alert — เมื่อระบบตรวจพบความผิดปกติ เช่น confidence score ต่ำกว่าค่าเกณฑ์, ความไม่สอดคล้องระหว่างผล AI กับ EHR (discrepancy), หรืออัตราการปฏิเสธผลจาก clinician สูงเกินกว่าพื้นฐาน ระบบควรส่งแจ้งเตือนไปยังทีมคลินิกและทีมไอทีทันที
- Periodic re‑audit — การตรวจสอบเชิงคุณภาพอย่างเป็นระบบที่กำหนดความถี่ เช่น รายเดือนสำหรับตัวชี้วัดสำคัญ และเชิงลึกทุกไตรมาสหรือทุก 2,000–5,000 เคส ขึ้นกับปริมาณการใช้งาน โดยเก็บตัวชี้วัด (KPIs) เช่น concordance rate ระหว่าง AI กับผลการวินิจฉัยของแพทย์, false positive/false negative rates, และเวลาการตอบสนอง
- Feedback loop — ฝังกลไกที่ clinician สามารถส่ง feedback เกี่ยวกับผล AI (ยอมรับ/ปฏิเสธพร้อมเหตุผล) ซึ่งถูกนำไปรวมในชุดข้อมูลสำหรับการ retraining หรือการปรับโมเดล โดยกระบวนการนี้ต้องควบคุมด้วย data governance และ version control
ตัวอย่างเกณฑ์ตรวจสอบเชิงปฏิบัติ ได้แก่ การตั้ง threshold หาก concordance กับผลผู้เชี่ยวชาญลดลงมากกว่า 10% ภายในหนึ่งเดือน ให้หยุดการใช้งานครั้งชั่วคราวและเริ่มกระบวนการ re‑audit ทันที
การจัดการเหตุฉุกเฉินเมื่อระบบทำงานผิดพลาด (Incident Response)
ต้องมีแผนตอบสนองเหตุฉุกเฉินที่ชัดเจนและทดสอบได้ ซึ่งประกอบด้วย:
- ขั้นตอนการแยกระบบ (isolation) — หากพบการผิดพลาดร้ายแรง ให้สามารถสั่งปิดการเชื่อมต่อกับ EHR หรือสลับกลับเป็นกระบวนการที่มนุษย์เป็นผู้รับผิดชอบทั้งหมด (manual fallback)
- การแจ้งเตือนผู้เกี่ยวข้อง — ระบุรายชื่อผู้รับผิดชอบ (clinical lead, safety officer, CTO) และช่องทางการสื่อสารฉุกเฉิน เช่น SMS/Email/หน้าจอ dashboard
- การบันทึก and รายงานเหตุการณ์ — รวบรวม incident log, ผลกระทบต่อผู้ป่วย และทำ root cause analysis พร้อมคู่มือ corrective action ที่ต้องดำเนินการภายในกรอบเวลา เช่น ภายใน 72 ชั่วโมงต้องมีแผนป้องกันซ้ำ
- การแจ้งหน่วยงานกำกับดูแลและผู้ป่วย — หากเกิดความเสี่ยงต่อความปลอดภัยของผู้ป่วย ต้องมีแนวทางการรายงานตามกฎระเบียบท้องถิ่นและการสื่อสารกับผู้ป่วยอย่างโปร่งใส
แนวทางการนำไปปฏิบัติและการประเมินผลระยะยาว
การนำ Audit‑AI ขึ้นใช้อย่างปลอดภัยในคลินิกเป็นกระบวนการที่ต่อเนื่อง ไม่ใช่การติดตั้งครั้งเดียวเสร็จสิ้น ควรกำหนด governance board ประกอบด้วยตัวแทนจากแพทย์ เจ้าหน้าที่ความปลอดภัยข้อมูล และฝ่ายไอที เพื่อทบทวนรายงานประสิทธิภาพเป็นประจำ โดยตั้ง KPI ตัวอย่างเช่น:
- Concordance rate เป้าหมาย ≥ 90%
- ลดเวลารอการอ่านผลภาพลง 20% ภายใน 6 เดือน
- จำนวน incident ต่อ 10,000 เคสต้องต่ำกว่าเกณฑ์ที่กำหนด
การประเมินผลควรประกอบด้วยการสำรวจความพึงพอใจของ clinician และการวัดผลด้านความปลอดภัยของผู้ป่วย ซึ่งงานวิจัยเชิงสังเกตชี้ว่าองค์กรที่มีระบบ monitoring และ feedback loop ที่แข็งแรงสามารถลดข้อผิดพลาดที่เกี่ยวข้องกับ AI ได้อย่างมีนัยสำคัญ (ตัวเลขขึ้นกับบริบทและการดำเนินงาน)
สุดท้ายนี้ การนำ Audit‑AI เข้าสู่คลินิกอย่างสมบูรณ์ต้องอาศัยการร่วมมือข้ามสาขาระหว่างทีมคลินิก ฝ่ายปฏิบัติการไอที และหน่วยกำกับดูแล เพื่อให้เกิดสมดุลระหว่างนวัตกรรม ความปลอดภัย และการคุ้มครองข้อมูลผู้ป่วย
ผลกระทบเชิงนโยบาย จริยธรรม และทิศทางในอนาคต
ผลกระทบเชิงนโยบาย จริยธรรม และทิศทางในอนาคต
โครงการ Audit‑AI ที่ริเริ่มโดยราชวิทยาลัยแพทย์ร่วมกับภาคสตาร์ทอัพมีศักยภาพเปลี่ยนกรอบการกำกับดูแลระบบปัญญาประดิษฐ์ทางการแพทย์จากการทดสอบภายในสู่การรับรองเชิงองค์กรและระดับชาติ โดยเฉพาะเมื่อระบบ AI ถูกนำขึ้นใช้ในคลินิก ความจำเป็นของการตรวจสอบก่อนขึ้นระบบ (pre‑deployment validation) และการตรวจติดตามหลังขึ้นระบบ (post‑market surveillance) จะกลายเป็นมาตรฐานปฏิบัติการใหม่ ตัวอย่างเช่น แนวปฏิบัติของ U.S. FDA ที่เสนอกรอบการกำกับแบบเฉพาะสำหรับ AI/ML และแนวคิดของ EU AI Act แสดงให้เห็นถึงทิศทางของการกำกับที่ให้ความสำคัญกับความปลอดภัย ความเป็นธรรม และการโปร่งใส ซึ่ง Audit‑AI สามารถทำหน้าที่เป็นแพลตฟอร์มเบนช์มาร์คที่สอดคล้องกับเกณฑ์เหล่านี้ได้
ในมิติด้านนโยบาย การประสานงานระหว่างหน่วยงานกำกับดูแล เช่น องค์การอาหารและยา (อย.) หน่วยงานสาธารณสุข และหน่วยงานมาตรฐาน จะเป็นกุญแจสำคัญต่อการกำหนดเกณฑ์รับรองก่อนนำระบบไปใช้จริง Governance ที่ชัดเจนควรรวมถึง: ข้อกำหนดด้านการตรวจวัดประสิทธิภาพ (sensitivity, specificity, calibration), เกณฑ์ความเสี่ยงตามบริบทการใช้งาน, และ การรายงานเหตุการณ์ไม่พึงประสงค์ แบบเดียวกับแนวทางของอุปกรณ์การแพทย์ โดย Audit‑AI สามารถจัดเตรียมรายงานเบนช์มาร์คที่รับรองได้เพื่อใช้ในการยื่นขออนุญาตหรือการรับรองจากหน่วยงานที่เกี่ยวข้อง
ด้านจริยธรรม โครงการต้องวางมาตรการคุ้มครองข้อมูลผู้ป่วยอย่างเข้มงวด ทั้งการใช้เทคนิคการ de‑identification ที่เป็นไปตามมาตรฐาน การดำเนินการภายใต้หลักการ data minimization และการควบคุมการเข้าถึงข้อมูล (access controls) เพื่อป้องกันการเชื่อมโยงย้อนกลับไปยังตัวบุคคล นอกจากนี้ ความโปร่งใสของโมเดล (model explainability) และการชี้แจงความรับผิดชอบ (accountability) เป็นสิ่งจำเป็น เช่น การจัดทำ model cards และ datasheets สำหรับแต่ละโมเดลซึ่งระบุข้อมูลเกี่ยวกับชุดข้อมูลฝึก สถานการณ์ที่เหมาะสมต่อการใช้งาน ข้อจำกัดของโมเดล และผลการทดสอบเบนช์มาร์คด้านความเอนเอียง (bias) และความเป็นธรรม (fairness) เพื่อให้ทั้งแพทย์ ผู้ป่วย และผู้กำกับดูแลเข้าใจความเสี่ยงและข้อจำกัดได้อย่างชัดเจน
ในการวางโร้ดแม็ปสู่การขยายใช้งานระดับชาติและสากล ควรจัดลำดับขั้นตอนเชิงยุทธศาสตร์ดังนี้:
- เฟสที่ 1 — พิสูจน์แนวคิด (Pilot & Certification): นำ Audit‑AI ไปใช้ในเครือข่ายคลินิกตัวอย่าง รวบรวมผลการทดสอบจริง และพัฒนากระบวนการรับรองร่วมกับหน่วยงานกำกับ เช่น การกำหนดชุดเกณฑ์ขั้นต่ำสำหรับการขึ้นใช้ในคลินิก
- เฟสที่ 2 — มาตรฐานระดับชาติ: ทำงานร่วมกับหน่วยงานมาตรฐาน (เช่น สถาบันมาตรฐานแห่งชาติ) เพื่อแปลงเกณฑ์และเมตริกของ Audit‑AI เป็นข้อกำหนดอย่างเป็นทางการที่สอดคล้องกับมาตรฐานทางการแพทย์และการคุ้มครองข้อมูล
- เฟสที่ 3 — ความร่วมมือระหว่างประเทศ: เปิดช่องทางแลกเปลี่ยนเบนช์มาร์คและแนวปฏิบัติระหว่างประเทศ ผ่านข้อตกลงการยอมรับร่วม (mutual recognition) กับองค์กรระหว่างประเทศ เช่น WHO หรือหน่วยงานกำกับในกลุ่มประเทศ เพื่อเร่งการยอมรับข้ามพรมแดน
- เฟสที่ 4 — การแชร์ข้อมูลแบบปลอดภัย: ส่งเสริมการสร้าง repository ของเบนช์มาร์คและชุดข้อมูลเปิดแบบ de‑identified ที่ผ่านการคัดกรองและควบคุมการเข้าถึง โดยผสมผสานเทคโนโลยีเช่น federated learning และ differential privacy เพื่อลดความเสี่ยงจากการเปิดเผยข้อมูลผู้ป่วย
สุดท้าย Audit‑AI ควรถูกออกแบบให้รองรับการบำรุงรักษาโมเดลในวงจรชีวิตจริง (model lifecycle management) ได้แก่ การติดตามการเสื่อมของประสิทธิภาพ (performance drift), การจัดเวอร์ชันของโมเดล, และนโยบายการรีเทรนอย่างเป็นระบบ ซึ่งจะช่วยลดความเสี่ยงด้านความปลอดภัยและเพิ่มความน่าเชื่อถือ ตัวอย่างทางปฏิบัติ ได้แก่ การกำหนด SLA สำหรับการรีวิวโมเดลทุก 6–12 เดือน และการตั้งระบบแจ้งเตือนเมื่อประสิทธิภาพลดลงมากกว่าเกณฑ์ที่ยอมรับได้ (เช่น AUC ลดลง >5%) ทั้งนี้ การประสานงานระหว่างภาครัฐ ภาคเอกชน และสถาบันวิชาการจะเป็นปัจจัยสำคัญในการผลักดัน Audit‑AI ให้กลายเป็นมาตรฐานที่ยอมรับได้ระดับชาติและสากล
บทสรุป
โครงการ Audit‑AI เป็นก้าวสำคัญที่ผสานความเชี่ยวชาญทางการแพทย์กับเทคโนโลยีปัญญาประดิษฐ์ เพื่อสร้างกรอบมาตรฐานด้านความปลอดภัยและการประเมินความเสี่ยงของโมเดลทางการแพทย์ก่อนนำขึ้นใช้ในคลินิก โครงการเน้นการทดสอบเชิงเบนช์มาร์คเพื่อจับและลดปัญหา hallucination รวมถึงการกำหนดเกณฑ์การรับรองเชิงปฏิบัติที่ชัดเจน ซึ่งจะช่วยลดความคลาดเคลื่อนในการให้ข้อมูลทางการแพทย์และป้องกันผลกระทบต่อผู้ป่วยและการตัดสินใจของแพทย์
ในเชิงอนาคต การผนึกกำลังระหว่างราชวิทยาลัยแพทย์และสตาร์ทอัพพร้อมแนวทางรับรองจริงจังที่มาพร้อมระบบ monitoring, การรายงานเหตุผิดพลาด และการฝึกอบรมบุคลากร จะเสริมสร้างความน่าเชื่อถือของ AI ทางการแพทย์และเอื้อให้เกิดการขยายการใช้งานอย่างรับผิดชอบ ทั้งในรูปแบบการทดลองภาคสนาม การทำมาตรฐานร่วมกับหน่วยงานกำกับดูแล และการติดตามผลเชิงต่อเนื่อง เพื่อให้เทคโนโลยีนี้กลายเป็นเครื่องมือที่ปลอดภัยและมีประโยชน์ต่อการรักษาผู้ป่วยในวงกว้าง



