
ในยุคที่โมเดลภาษาขนาดใหญ่ (LLM) กลายเป็นหัวใจของการเปลี่ยนแปลงทางธุรกิจและนวัตกรรมดิจิทัล สตาร์ทอัพไทยรายหนึ่งได้เปิดตัว Auto‑MLOps Composer แพลตฟอร์มที่ประกาศยกระดับกระบวนการนำโมเดลสู่การใช้งานจริง ด้วยแนวคิด «สร้าง CI/CD สำหรับ LLM ด้วยคลิกเดียว» ที่ช่วยลดเวลาในการปรับใช้จากระดับสัปดาห์ลงมาเหลือเพียงชั่วโมง บริษัทระบุว่าในกรณีทดลองจริงสามารถย่นเวลา deployment จากเฉลี่ย 2–3 สัปดาห์เหลือเพียง 2–4 ชั่วโมง ทำให้ทีมวิจัยและวิศวกร ML เร่งทดลอง ปรับจูน และนำโมเดลสู่การผลิตได้รวดเร็วยิ่งขึ้น
Auto‑MLOps Composer ออกแบบมาเพื่ออัตโนมัติขั้นตอนสำคัญทั้งการสร้าง pipeline, การทดสอบเชิงคุณภาพ, การตรวจสอบความผิดปกติ (monitoring & drift detection), และการบริหารจัดการ governance/ความปลอดภัย โดยรองรับการเชื่อมต่อกับเครื่องมือและแพลตฟอร์มยอดนิยมในวงการ ทำให้เหมาะสำหรับองค์กรตั้งแต่สตาร์ทอัพไปจนถึงหน่วยงานขนาดใหญ่ที่ต้องการลดความเสี่ยงและต้นทุนการนำ LLM สู่การผลิต บทนำนี้จะชี้ให้เห็นภาพรวมฟีเจอร์ ผลประโยชน์เชิงธุรกิจ และตัวอย่างกรณีใช้งานที่แสดงให้เห็นว่าแพลตฟอร์มดังกล่าวสามารถพลิกโฉมกระบวนการพัฒนา AI ในไทยได้อย่างไร
ภาพรวม: อะไรคือ Auto‑MLOps Composer
ภาพรวม: อะไรคือ Auto‑MLOps Composer
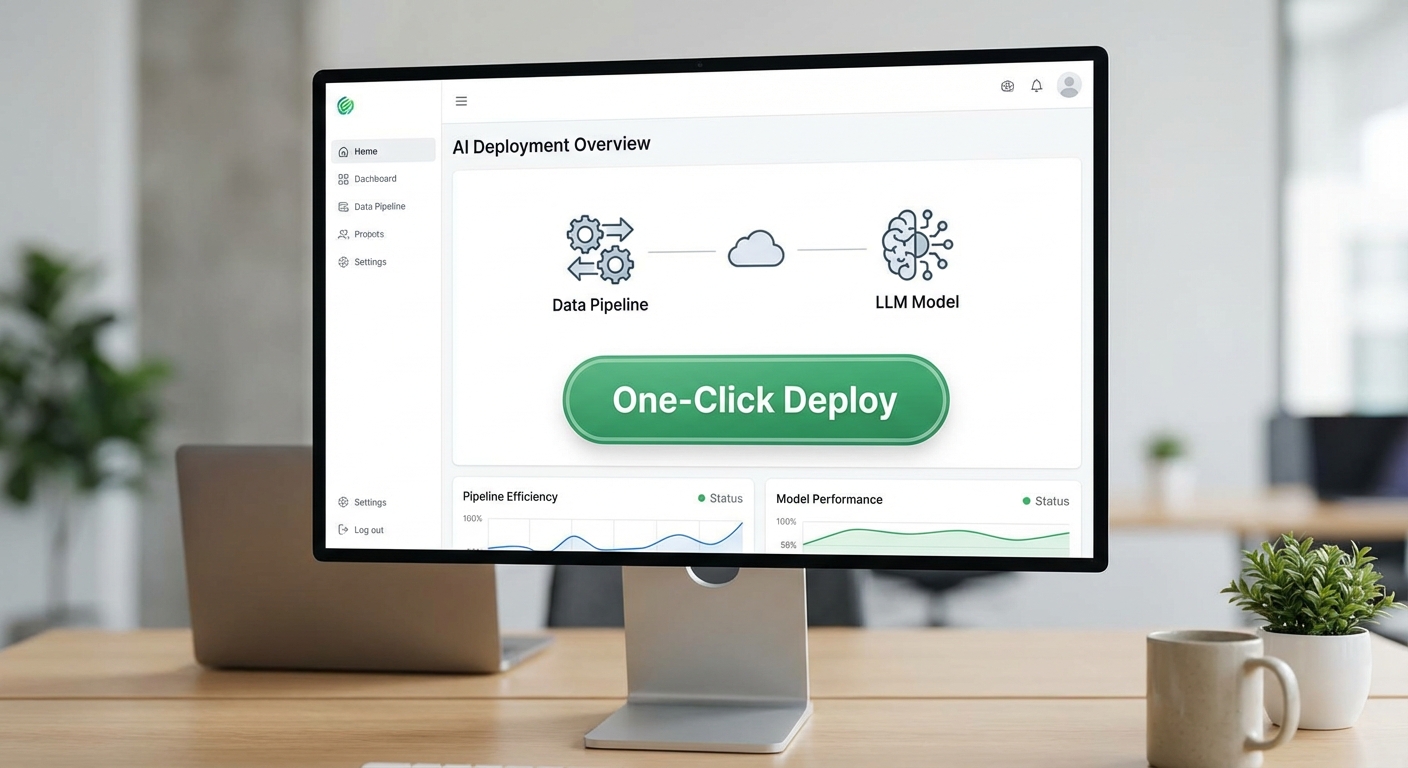
Auto‑MLOps Composer เป็นแพลตฟอร์มสำหรับสร้างและบริหาร CI/CD pipeline สำหรับโมเดลภาษาขนาดใหญ่ (LLM) โดยออกแบบมาเพื่อให้ทีมพัฒนา โมเดล และงานปฏิบัติการ (MLOps) สามารถนำโมเดลจากการทดลอง (PoC) ขึ้นสู่การใช้งานจริงได้ด้วยขั้นตอนที่เป็นระบบและอัตโนมัติ เพียงไม่กี่คลิก ภายใต้กรอบการควบคุมด้านคุณภาพ ความปลอดภัย และการตรวจสอบที่เหมาะสมกับการใช้งานในระดับองค์กร เป้าหมายหลักคือการลดเวลาในการนำโมเดลขึ้นสู่ Production, เพิ่มความสามารถในการทดสอบและมอนิเตอร์โมเดลอย่างต่อเนื่อง ตลอดจนรองรับการทำงานร่วมกันของทีมข้ามสายงานในองค์กรขนาดใหญ่
ในเชิงฟีเจอร์พื้นฐาน Auto‑MLOps Composer ให้ชุดความสามารถที่ครอบคลุมวงจรชีวิตของโมเดล ได้แก่:
- One‑click pipeline — สร้างและรัน pipeline สำเร็จรูปสำหรับการฝึก ออกแบบ และ deploy โมเดลด้วยปุ่มเดียว ช่วยลดงาน manual และความผิดพลาดจากการตั้งค่าด้วยมือ
- อัตโนมัติการทดสอบและ deploy — รวมขั้นตอนทดสอบอัตโนมัติ (unit tests, integration tests, performance benchmarks, A/B และ canary tests) ก่อน deploy ไปยังสภาพแวดล้อมจริง พร้อมขั้นตอน rollback อัตโนมัติเมื่อเกณฑ์ไม่ผ่าน
- Versioning และ model registry — เก็บประวัติของโค้ด data pipeline และ weights ของโมเดลอย่างละเอียด พร้อม tagging, reproducibility และการเรียกคืน (rollback) เวอร์ชันเก่าได้ทันที
- Monitoring และ observability — ติดตามเมตริกด้านคุณภาพ (accuracy, latency, throughput), การดริฟท์ของข้อมูล, การสั่นไหวของพฤติกรรมโมเดล และ alerting ที่ผสานกับระบบ incident management
- Enterprise features — สนับสนุน RBAC, audit logs, encryption, และการใช้งานแบบ hybrid/multi‑cloud เพื่อให้เป็นไปตามข้อกำหนดด้านความปลอดภัยและการกำกับดูแล
การทำงานจริงของ Composer มักเริ่มจากการผสานกับระบบจัดเก็บโค้ด (Git) และระบบเก็บข้อมูลโมเดล เมื่อมีการ push โค้ดหรืออัปเดต artifact ระบบจะสร้าง pipeline โดยอัตโนมัติ ดำเนินการผ่านขั้นตอนตรวจสอบข้อมูล ทดลองฝึก ระบุเมตริกเชิงประสิทธิภาพ ทำการทดสอบความเสถียรภายใต้โหลดจริง และถ้าเกณฑ์ผ่านจะทำการ deploy แบบค่อยเป็นค่อยไป (canary/blue‑green) พร้อมเก็บเวอร์ชันและบันทึกผลเพื่อการอ้างอิงในอนาคต ทั้งหมดนี้สามารถสั่งรันด้วย one‑click ที่หน้าจอเดียวหรือผ่าน API สำหรับการผนวกรวมเข้ากับ workflow อื่นๆ
ผลลัพธ์ที่สตาร์ทอัพประกาศชัดเจนคือการย่นระยะเวลา deployment จากเดิมที่ใช้เวลาเป็นระดับสัปดาห์ลงมาเป็นระดับชั่วโมง: ลูกค้ารายเบต้ารายงานการลดเวลาเฉลี่ยจาก 1–3 สัปดาห์ เหลือเพียง 1–6 ชั่วโมง สำหรับการย้าย LLM จาก PoC ไปสู่ Production โดยยังคงมาตรฐานการทดสอบและการมอนิเตอร์ไว้ครบถ้วน นอกจากนี้ Composer ยังช่วยลดข้อผิดพลาดจากการตั้งค่าด้วยมือและเพิ่มอัตราการปล่อยฟีเจอร์ใหม่ที่ผ่านเกณฑ์คุณภาพได้มากขึ้น
สรุปคือ Auto‑MLOps Composer มุ่งหวังที่จะเป็นสะพานเชื่อมระหว่างทีมวิจัยและการปฏิบัติการ ช่วยให้องค์กรสามารถนำ LLM เข้าสู่การใช้งานจริงได้รวดเร็ว ปลอดภัย และสามารถควบคุมได้ เหมาะสำหรับองค์กรที่ต้องการลดเวลา time‑to‑market ของโซลูชัน AI ในขณะที่ยังรักษามาตรฐานด้านคุณภาพและการกำกับดูแล
สถาปัตยกรรมและฟีเจอร์เชิงเทคนิค
ภาพรวมสถาปัตยกรรม
Auto‑MLOps Composer ถูกออกแบบเป็นสถาปัตยกรรมแบบโมดูลาร์ที่แยกความรับผิดชอบชัดเจน ประกอบด้วย orchestration layer สำหรับกำกับ workflow, ชุด runners/executors ที่รันงานจริง (data processing, training, evaluation), artifact store สำหรับเก็บข้อมูลดิบและโมเดล, และ model registry สำหรับบริหารเวอร์ชันของโมเดลและ metadata ของการทดลอง ตัว orchestration รองรับทั้งระบบแบบ declarative (workflow as code) และ interactive UI ที่ช่วยให้ผู้ใช้งานสามารถสร้าง pipeline แบบคลิกเดียวและตรวจสอบสถานะได้แบบเรียลไทม์
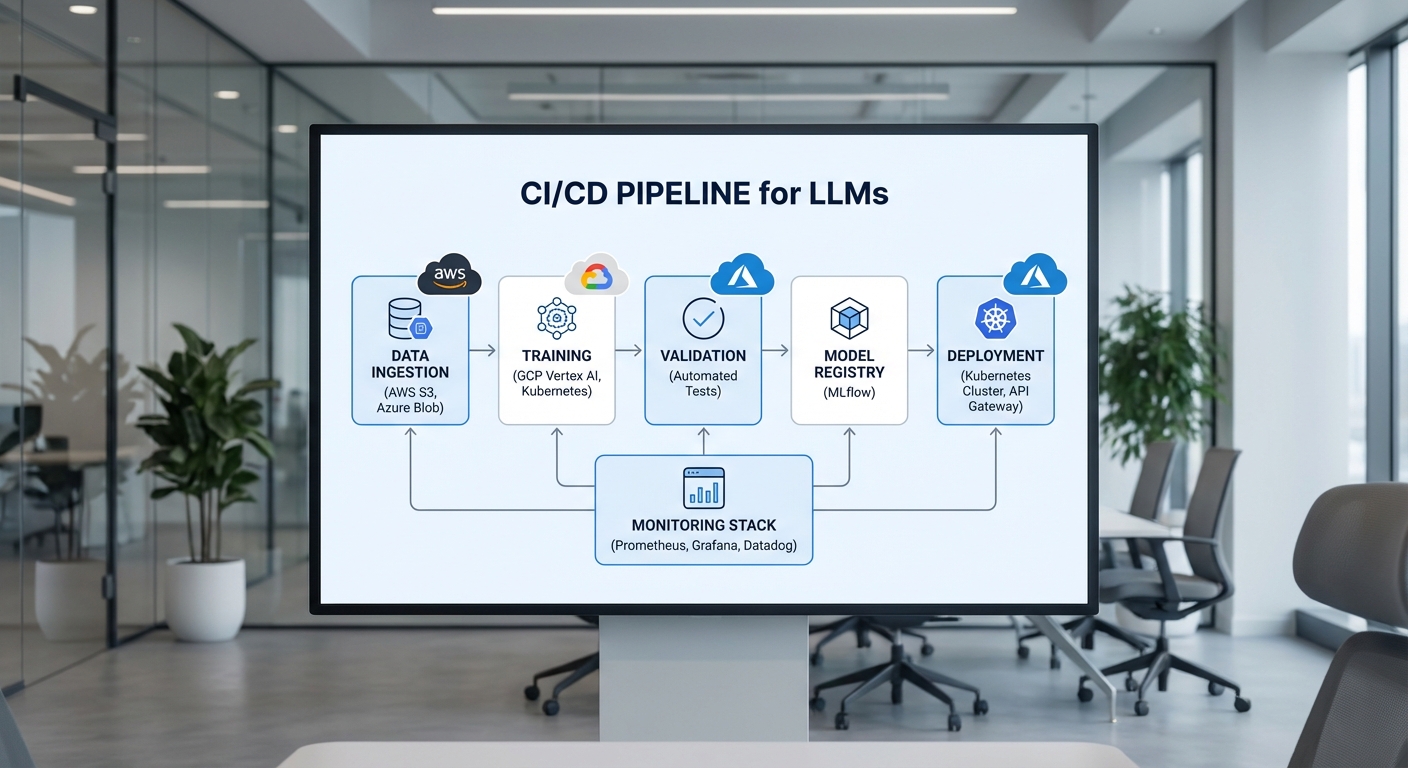
โดยทั่วไป pipeline แบ่งเป็นส่วนหลักดังนี้:
- Data ingestion & preprocessing — รองรับ connectors ไปยังฐานข้อมูลภายนอก (RDBMS, Kafka, S3/GCS, BigQuery) พร้อมระบบ batch/stream hybrid
- Training & fine‑tuning — รันบน GPU/TPU ผ่าน containerized executors พร้อมรองรับ distributed training (Horovod, DeepSpeed)
- Evaluation & validation — ประกอบด้วย automated test suites สำหรับ performance, fairness และ safety
- Deployment & serving — เชื่อมต่อกับ model registry เพื่อ deploy แบบ canary, blue‑green หรือ batch rollout
การสนับสนุน LLM โดยเฉพาะ
Auto‑MLOps Composer มีฟีเจอร์เฉพาะสำหรับ LLM ตั้งแต่ชั้นการเตรียมข้อมูลจนถึงการให้บริการ inference:
- Tokenization pipeline — รองรับหลาย tokenizer (Byte‑Pair Encoding, SentencePiece, tokenizer ของ Hugging Face) และสามารถทำ caching ของ tokenized dataset เพื่อลดเวลา preprocessing ได้ถึง 10–20x ในหลายงาน
- Prompt testing & prompt suite — ชุดเครื่องมือสำหรับเขียนชุด prompt tests (edge cases, context window overflow, prompt injection) พร้อมวัดผลเชิงคุณภาพ (BLEU, ROUGE, semantic similarity) และเชิงพฤติกรรม (consistency, hallucination rate)
- Safety filters — pipeline ประกอบด้วยกรองหลายชั้นทั้งก่อนและหลังโมเดล เช่น PII redaction, toxicity classifier, and policy enforcement hooks เพื่อป้องกันการตอบกลับที่มีความเสี่ยง
- Performance profiling — เก็บ metrics สำหรับ latency per token, throughput (tokens/sec), GPU utilization และ memory footprint พร้อม profile traces เพื่อปรับ batch size หรือเรียนรู้ configuration ที่เหมาะสม
กลไก CI/CD เฉพาะสำหรับโมเดล
ระบบ CI/CD ถูกออกแบบให้รองรับลูปการพัฒนาโมเดลแบบเฉพาะ ได้แก่ automated tests, staged rollout, และ rollback โดยมีองค์ประกอบสำคัญดังนี้:
- Automated tests — รวมทั้ง unit tests (data schema, preprocessing functions), integration tests (end‑to‑end pipeline run in sandbox), และ regression tests (เช็คว่า metric หลักไม่ตกลงมากกว่าค่า threshold ที่กำหนด)
- Canary / batch rollout — รองรับ traffic splitting ระหว่างเวอร์ชัน (เช่น 5% canary, 95% production) พร้อมระบบ shadowing เพื่อรัน inference แบบไม่มีผลกับผู้ใช้จริงก่อนปล่อยเต็ม
- Automated rollback — ประกอบด้วย triggers อัตโนมัติ (latency spike, metric regression, safety violation) ที่สามารถย้อน deployment เดิมภายในนาที พร้อม workflow ที่บันทึกเหตุผลการ rollback เพื่อการสอบสวนย้อนหลัง
- Auditable promotion — การ promote โมเดลจาก staging ไป production ต้องมีการอนุมัติ (manual or policy‑based) และบันทึก metadata ทั้งหมดใน model registry
การเชื่อมต่อกับ Cloud และ Containerization
Auto‑MLOps Composer ถูกออกแบบให้สามารถทำงานแบบ hybrid และ multi‑cloud เพื่อรองรับความต้องการองค์กรที่แตกต่างกัน โดยรองรับผู้ให้บริการรายใหญ่ทั้งหมด:
- AWS — รองรับ S3 (artifact store), SageMaker (optional hosting/registry integration), EKS สำหรับ Kubernetes-based serving และ IAM integration
- GCP — รองรับ GCS, Vertex AI integration, GKE และการเชื่อมต่อ BigQuery สำหรับ analytics
- Azure — รองรับ Azure Blob, Azure ML model registry และ AKS สำหรับ orchestration
ระดับ containerization ใช้ Docker สำหรับบรรจุขั้นตอนต่างๆ และใช้ Kubernetes เป็นแพลตฟอร์มหลักสำหรับจัดการ executor และ serving layer โดยผสานกับเทคโนโลยี autoscaling เช่น HPA/VPA และ KEDA สำหรับ event‑driven scaling นอกจากนี้ยังสามารถใช้ serverless inference (AWS Lambda, Cloud Run) สำหรับ use case latency ต่ำและ throughput ต่ำ
มาตรการด้านความปลอดภัยและ Governance
ความปลอดภัยและการกำกับดูแลเป็นหัวใจของระบบ โดย Auto‑MLOps Composer มีมาตรการหลายชั้นเพื่อป้องกันความเสี่ยงและสร้างความโปร่งใส:
- Secret management — ผสานกับ HashiCorp Vault, AWS KMS/GCP KMS สำหรับจัดการ secrets และ credentials โดยมีการเข้ารหัสทั้งที่พัก (at rest) และตอนส่งข้อมูล (in transit)
- Access control — ใช้ RBAC และ integration กับองค์กร IAM (LDAP/AD, SSO) เพื่อควบคุมสิทธิ์การเข้าถึง pipeline, data, และ model registry โดยรองรับการกำหนด policy แบบละเอียด (least privilege)
- Audit logs & lineage — บันทึกทุกกิจกรรม (run, deploy, approve, rollback) ใน immutable audit log และเก็บ lineage ของ artefact ตั้งแต่ data source → preprocessing → training → evaluation → deployment เพื่อการตรวจสอบและการทำ compliance
- Data governance & privacy — รองรับ data masking, differential privacy hooks ใน training pipeline และการตั้งค่า retention policy ใน artifact store เพื่อลดความเสี่ยงของข้อมูลส่วนบุคคล
การสังเกตการณ์และตัวชี้วัดเชิงปฏิบัติการ
ระบบมาพร้อมกับ stack สำหรับ observability (Prometheus + Grafana, OpenTelemetry) เพื่อเก็บ metrics เช่น latency per request, tokens/sec, GPU utilization, error rates และ custom business metrics (e.g., task success rate, hallucination rate) โดย Composer สามารถปรับ dashboards อัตโนมัติและตั้ง alert thresholds สำหรับการแจ้งเตือนเชิงป้องกัน ตัวอย่างเช่น การตั้งค่า alert เมื่อ latency เพิ่มขึ้นมากกว่า 30% หรือตัวชี้วัดความแม่นยำลดลงเกิน 5% เมื่อเทียบกับ baseline
สรุปคือ Auto‑MLOps Composer รวมเอา best practices ด้าน MLOps และการให้บริการ LLM เข้าด้วยกัน ตั้งแต่การจัดการข้อมูล การฝึกสอน การทดสอบจนถึงการนำขึ้น production พร้อมกลไก CI/CD เฉพาะโมเดล การผสานกับ cloud รายใหญ่ และมาตรการความปลอดภัยเชิงรุก ทำให้การเปลี่ยนผ่านจาก proof‑of‑concept เป็นบริการที่ใช้งานจริงลดเวลาจากระดับสัปดาห์เหลือระดับชั่วโมงโดยยังคงความปลอดภัยและควบคุมได้สำหรับองค์กร
ผลลัพธ์เชิงตัวเลข: ตัวอย่าง Benchmark และเวลาในการปรับใช้
สรุปภาพรวมตัวเลขสำคัญ
จากการทดสอบภายในและกรณีศึกษาลูกค้าตัวอย่างของ Auto‑MLOps Composer พบว่า เวลาในการย้ายโมเดลจากการทดลองสู่ production ลดลงอย่างมีนัยสำคัญ โดยเฉลี่ยจากช่วงเวลาเดิมที่ใช้ 5–10 วัน เหลือเพียง 2–4 ชั่วโมง ในสภาพแวดล้อมที่เตรียมพร้อม (ค่าเฉลี่ยเชิงตัวเลขของการทดสอบภายใน: ก่อน = 7.5 วัน ≈ 180 ชั่วโมง, หลัง = 3 ชั่วโมง) ซึ่งคิดเป็นการลดเวลาโดยประมาณ 98.3% เมื่อคำนวณจากค่าเฉลี่ยแบบง่าย (180 → 3 ชั่วโมง)
- อัตราความสำเร็จของการ deploy เพิ่มขึ้น: จากประมาณ 82% → 97% (ลดความล้มเหลวจากการตั้งค่าและสคริปต์ด้วย pipeline อัตโนมัติ)
- เวลา rollback เฉลี่ยลดลง: จากเฉลี่ย 6 ชั่วโมง → 20 นาที (ลดได้ ~94%)
- ความถี่ในการ release เพิ่มขึ้น: จากเดิมเป็นรายสัปดาห์ → เป็นรายวันหรือหลายครั้งต่อวัน (x7 หรือมากกว่า)
- MTTR (Mean Time To Recover) ลดลง: จาก 4.8 ชั่วโมง → 0.5 ชั่วโมง
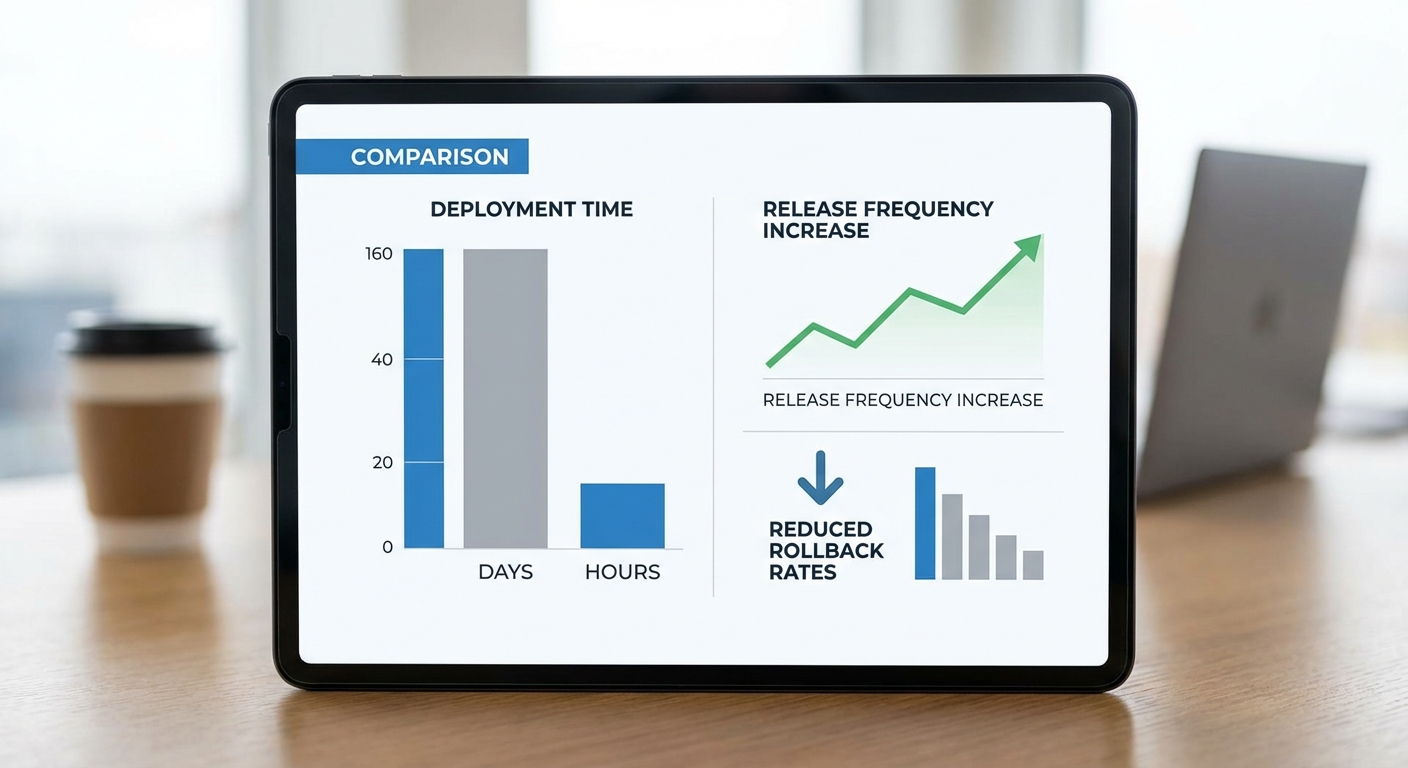
ตัวอย่าง 'ก่อนและหลัง' (กรณีจำลอง/กรณีศึกษา)
ตัวอย่างกรณีจำลองจากองค์กรขนาดกลางที่พัฒนา LLM สำหรับการตอบคำถามลูกค้า ก่อนนำ Composer มาใช้ ทีมงานใช้กระบวนการ manual CI/CD, การทดสอบและการตรวจรับใช้ต้องใช้เวลาประสานหลายฝ่าย ส่งผลให้ เฉลี่ยเวลา deploy ต่อรุ่นอยู่ที่ 5–10 วัน และมี rollback บ่อยเมื่อเกิดปัญหา deployment script ไม่สอดคล้องกับสภาพแวดล้อมจริง
หลังติดตั้ง Auto‑MLOps Composer องค์กรดังกล่าวรายงานว่า deployment ทั้งหมดสามารถสั่งงานแบบคลิกเดียวและผ่านการทดสอบอัตโนมัติใน pipeline ภายในเวลาเฉลี่ย 2–4 ชั่วโมง โดยสรุปเป็นตัวเลขดังนี้:
- เวลาเฉลี่ยจาก PR → Production: 180 ชั่วโมง → 3 ชั่วโมง (ลด ~98%)
- อัตราความล้มเหลวของ deploy: 18% → 3%
- จำนวน release ต่อสัปดาห์: 1 → 7+ (เพิ่มความถี่เป็นรายวัน)
การวัดประสิทธิภาพโมเดลก่อน/หลังการ deploy ด้วย pipeline
นอกจากตัวชี้วัดการจัดการกระบวนการแล้ว ทีมทดสอบยังเก็บเมตริกเชิงประสิทธิภาพของโมเดลเพื่อเปรียบเทียบผลก่อนและหลังใช้งาน pipeline ดังนี้ (ค่าเป็นตัวอย่างเฉลี่ยจากชุดทดสอบจริง):
- Latency (median p50): ก่อน deploy แบบ manual = 120 ms → หลัง deploy ผ่าน Composer = 95 ms (ลด ~21%)
- Throughput (RPS — requests per second): ก่อน = 450 RPS → หลัง = 520 RPS (เพิ่ม ~15%) เนื่องจากการจัดการทรัพยากรอัตโนมัติและการปรับขนาดใน pipeline
- Error rate (5xx/timeout): ก่อน = 4.8% → หลัง = 0.9% (ปรับปรุงความเสถียร ~81%)
- Model drift detection & automated rollback: การตรวจพบ degradation ในคุณภาพโมเดลและการทำ rollback อัตโนมัติลดเวลาคลอดข้อผิดพลาด (detection → mitigation) จากเฉลี่ย 3.2 ชั่วโมง → 12 นาที
ตัวอย่างกรณีศึกษาลูกค้าองค์กร
1) ธนาคารขนาดใหญ่ (กรณีไม่เปิดเผยชื่อ): ธนาคารนำ Composer ไปใช้กับ LLM สำหรับการตอบคำถามด้านบริการลูกค้าและการวิเคราะห์เอกสาร พบว่า เวลาถึง production ลดจาก 6 วันเหลือ 3 ชั่วโมง, อัตราข้อผิดพลาดระหว่าง deploy ลดจาก 16% เหลือ 2.5%, และสามารถปล่อยรุ่นปรับปรุงโมเดลเป็นรายวันเพื่อตอบสนองข้อกฎระเบียบและการแก้บั๊กได้เร็วขึ้น
2) หน่วยงานทางการแพทย์ (ตัวอย่างเช่น ระบบช่วยอ่านผลเบื้องต้น): ทีมพัฒนารายงานว่า Composer ช่วยให้การทดสอบเชิงคลินิกและการปรับใช้บนคลัสเตอร์ที่มีการจัดการทรัพยากรเป็นไปอย่างราบรื่น — เวลา rollback ลดลงจาก ~5 ชั่วโมงเป็น 30 นาที และการตรวจวัดความน่าเชื่อถือ (error rate) ลดลงจาก 6.1% เป็น 1.2% เมื่อรวมกับการทดสอบ A/B อัตโนมัติใน pipeline
สรุป: ตัวเลขจากการทดสอบและกรณีศึกษาแสดงให้เห็นว่า Auto‑MLOps Composer ไม่เพียงลดระยะเวลาในการ deploy อย่างมีนัยสำคัญ แต่ยังเพิ่มความเสถียรของการให้บริการ ลดเวลาการกู้คืนเมื่อเกิดปัญหา และเพิ่มความถี่ในการปล่อยผลิตภัณฑ์ ทำให้องค์กรสามารถปรับตัวและส่งมอบคุณค่าเชิงธุรกิจได้เร็วขึ้นอย่างชัดเจน
ประสบการณ์ผู้ใช้และเวิร์กโฟลว์แบบคลิกเดียว
Auto‑MLOps Composer ถูกออกแบบมาเพื่อมอบประสบการณ์ที่เรียบง่ายและเป็นมิตรกับทีม Data Science และ ML Engineer โดยเน้นการลดความซับซ้อนของ UI/UX ให้เหลือเพียง ไม่กี่คลิก ตั้งแต่การสร้างโปรเจกต์จนถึงการนำโมเดลขึ้น production ผลจากการทดสอบเชิงภายในระบุว่าสามารถลดเวลาการปรับใช้จากระดับสัปดาห์ลงมาเหลือชั่วโมงหรือแม้กระทั่งนาทีในเคสที่ใช้เทมเพลตสำเร็จรูปและการตั้งค่าเริ่มต้น (ตัวเลขเฉลี่ยการลดเวลาอยู่ในช่วงประมาณ 60–90% ขึ้นอยู่กับความซับซ้อนของ pipeline)
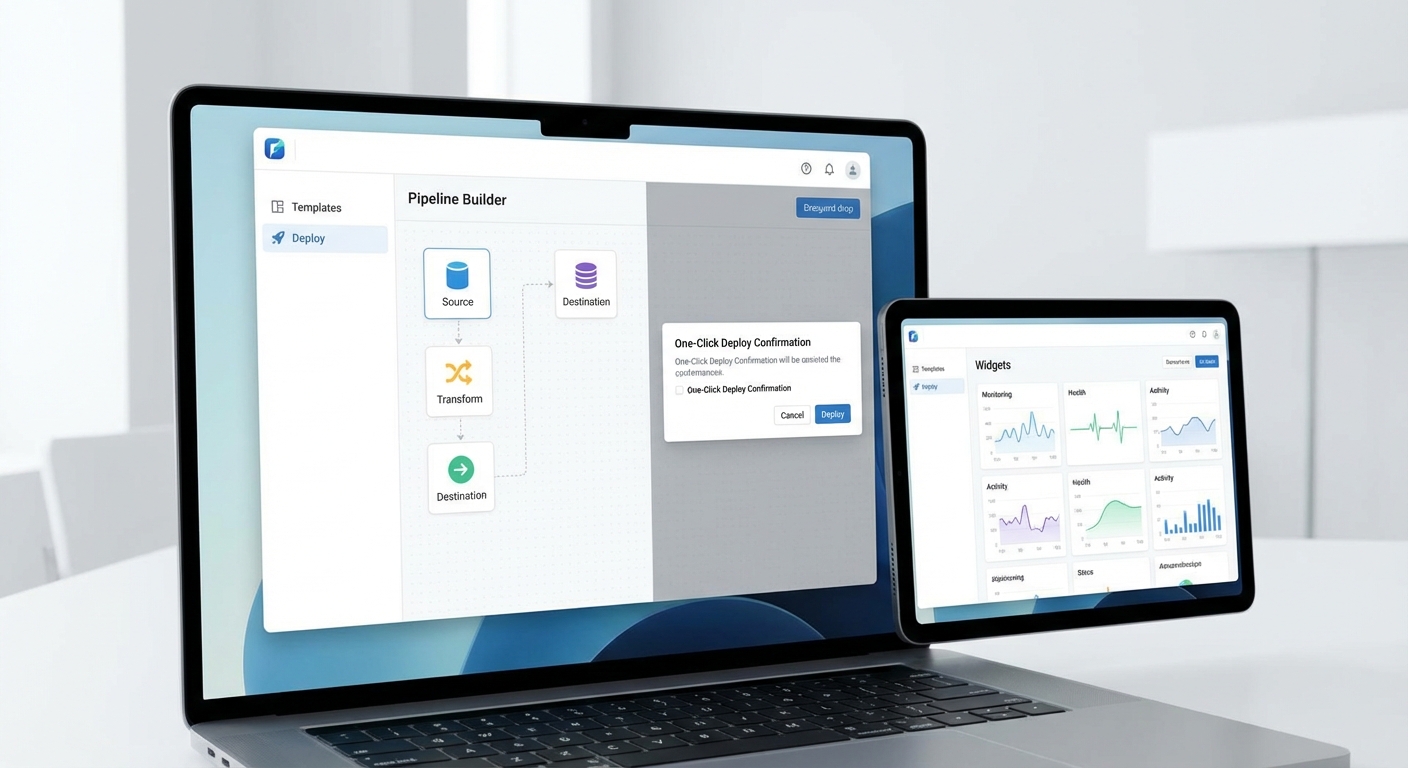
สาธิตเส้นทางผู้ใช้ (Create Project → Template → Configure → Deploy)
เส้นทางผู้ใช้ถูกจัดวางอย่างเป็นลำดับ ครอบคลุมการทำงานหลัก 4 ขั้นตอนที่เข้าใจง่าย:
- สร้างโปรเจกต์: กรอกชื่อโปรเจกต์ เลือกทีม และเชื่อมต่อ repository/คลังข้อมูลผ่าน wizard ที่มี validation อัตโนมัติ (เช่น ตรวจสอบสิทธิ์ของ token) — กระบวนการใช้เวลาโดยเฉลี่ย 2–5 นาที
- เลือกเทมเพลต: เลือกเทมเพลต pipeline จากแกลเลอรี (LLM fine‑tune, RAG, inference service, A/B testing) โดยแต่ละเทมเพลตมีคำอธิบาย ประเมินเวลารัน และตัวอย่างพารามิเตอร์
- ตั้งค่าพารามิเตอร์: แบบฟอร์มอินเตอร์เฟซสำหรับใส่ hyperparameters, secret keys, environment variables, และ resource profile (CPU/GPU/memory) พร้อมการตรวจสอบความถูกต้องและตัวช่วยแนะนำค่าพารามิเตอร์เริ่มต้น
- คลิก Deploy: ปุ่มเดียวสำหรับเริ่ม pipeline พร้อมตัวเลือก Dry Run, Canary หรือ Full Rollout โดยระบบจะแสดงสเตตัส real‑time และส่งแจ้งเตือนไปยัง Slack/Email
ฟีเจอร์ช่วยงานทีม non‑dev
เพื่อรองรับผู้ใช้ที่ไม่ใช่นักพัฒนา (เช่น นักวิเคราะห์ธุรกิจหรือ Product Manager) Composer มีฟีเจอร์สำคัญดังนี้:
- Visual Builder: Drag‑and‑drop node สำหรับเชื่อมสเต็ปต่างๆ ของ pipeline (preprocess → train → test → validate → deploy) พร้อม preview ของ data flow
- Predefined Templates: ชุดเทมเพลตสำหรับงาน LLM เช่น summarization, question answering, intent classification และ RAG ที่ช่วยให้ทีมตั้งค่าเบื้องต้นได้ภายใน 10–30 นาที
- Guided Prompts: ช่วยเขียน prompt และ hyperparameter suggestion แบบอัตโนมัติ โดยใช้ best practices ที่ปรับตามขนาดข้อมูลและทรัพยากร
- No‑code to YAML: ผู้ใช้สามารถเลือกวิธี visual แล้วระบบจะสร้างไฟล์ YAML/CI config ให้โดยอัตโนมัติ เพื่อความโปร่งใสและรองรับทีม DevOps
ระบบการอนุมัติและการร่วมมือ (Approval Workflows & Role‑Based Access)
Composer รองรับการทำงานแบบทีมอย่างเต็มรูปแบบด้วยระบบอนุมัติและสิทธิ์ที่ยืดหยุ่น:
- Approval workflows: ตั้งค่า manual gate ระหว่างขั้นตอนสำคัญ เช่น ก่อน deploy สู่ production สามารถกำหนด approver หลายคน, quorum และ timeout ได้
- Role‑Based Access Control (RBAC): แบ่งสิทธิ์เป็นระดับ (Admin, Approver, Developer, Viewer) พร้อม policy ที่ละเอียด เช่น จำกัดการปรับพารามิเตอร์บางชนิดหรือการเข้าถึง secrets
- Commenting & Audit Trail: ผู้อนุมัติสามารถแสดงความเห็น ย้อนดูการเปลี่ยนแปลง และเรียกดูบันทึกการอนุมัติเพื่อการตรวจสอบ (compliance)
- Integrations: เชื่อมต่อกับ Git/GitOps, Jira และระบบ IAM ภายในองค์กร เพื่อให้กระบวนการอนุมัติเป็นไปตาม workflow ที่มีอยู่
การตั้งค่า Retraining Schedule และ Drift Detection
หลังการ deployment Composer มาพร้อมชุดเครื่องมือมอนิเตอร์และการจัดการวงจรชีวิตโมเดลเพื่อให้โมเดลยังคงมีประสิทธิภาพ:
- Retraining Schedule: กำหนด cron‑style schedule (รายวัน/สัปดาห์/รายเดือน) หรือใช้เงื่อนไขเชิงธุรกิจเป็นทริกเกอร์ เช่น ปริมาณข้อมูลใหม่เกินเกณฑ์หรือ performance ลดลงกว่าค่า threshold
- Drift Detection: โมดูลตรวจจับทั้ง data drift และ concept drift โดยใช้เมทริกซ์เช่น KL divergence, PSI, และ performance delta — ผู้ใช้สามารถกำหนด threshold เช่นแจ้งเตือนเมื่อความแตกต่างของ distribution เกิน 0.1 หรือ accuracy ลดลง >5%
- Auto vs Manual Retrain: เลือกระหว่าง retrain แบบอัตโนมัติหรือส่งให้ทีมอนุมัติก่อนรัน โดยระบบจะเสนอ dataset ที่ถูก sampling, validation report และ estimated cost สำหรับการ retrain
- Monitoring & Rollback: real‑time dashboard ติดตาม latency, error rate, token usage, และ business metrics พร้อมการทำ canary/blue‑green rollout และ rollback อัตโนมัติเมื่อพบปัญหา
โดยรวมแล้ว Auto‑MLOps Composer มุ่งให้ทีม Data Science/ML Engineer ทำงานร่วมกับผู้มีส่วนได้ส่วนเสียอื่นได้อย่างราบรื่น ไม่ว่าจะเป็นการตั้งค่า pipeline ด้วยคลิกเดียว การใช้เทมเพลตสำหรับ non‑dev การควบคุมสิทธิ์และขั้นตอนอนุมัติที่เข้มงวด รวมถึงการตั้งค่า retraining และการตรวจจับ drift ที่ช่วยรักษาคุณภาพของโมเดลในระยะยาว — ทั้งหมดนี้ถูกผสานใน UX ที่ออกแบบมาเพื่อธุรกิจที่ต้องการความเร็วและความเชื่อถือได้ในระดับ production
ผลกระทบทางธุรกิจ: ต้นทุน ประสิทธิภาพ และ ROI
ผลกระทบทางธุรกิจ: ต้นทุน ประสิทธิภาพ และ ROI
การลดต้นทุนบุคลากรและเวลา — เมื่อเปรียบเทียบการทำ MLOps แบบดั้งเดิมกับการใช้ Auto‑MLOps Composer จะเห็นการลดชั่วโมงงานของทีม DevOps / ML Engineering อย่างชัดเจน ในกรณีสมมติฐานทั่วไป (เพื่อการประมาณการ): สมมติค่าแรงแบบ fully‑loaded ของวิศวกร ML/DevOps เท่ากับ 75 USD/ชั่วโมง (ประมาณ 150,000 USD/ปี) ทีม MLOps แบบดั้งเดิมอาจต้องใช้ 1.0–1.5 FTE ตลอดปี (2,000–3,000 ชั่วโมง) สำหรับการดูแล pipeline, CI/CD และการปรับใช้โมเดล ในขณะที่การนำ Auto‑MLOps Composer มาใช้สามารถลดงานเชิงโครงสร้างพื้นฐานและบำรุงรักษาเหลือเพียง 0.2–0.5 FTE (400–1,000 ชั่วโมง) หมายความว่าองค์กรจะประหยัดชั่วโมงงานได้ประมาณ 1,600–2,000 ชั่วโมง/ปี ซึ่งเทียบเป็นมูลค่าประมาณ 120,000–150,000 USD/ปี (หรือประมาณ 4.2–5.25 ล้านบาท/ปี ตามอัตราแลกเปลี่ยนสมมติ) นอกจากนี้ยังลดความเสี่ยงจากการขาดแคลนทักษะเฉพาะทางและค่าใช้จ่ายในการจ้างและฝึกอบรมซ้ำซ้อน
การเพิ่มความเร็วในการนำฟีเจอร์ใหม่สู่ตลาด (Time‑to‑Market) — ปกติการสร้างและทดสอบ pipeline แบบเดิมอาจใช้เวลาหลายสัปดาห์ถึงหลายเดือนสำหรับแต่ละฟีเจอร์หรืออัปเดตโมเดล Auto‑MLOps Composer ช่วยย่นเวลาเหล่านี้จากระดับสัปดาห์เหลือระดับชั่วโมง/วัน ทำให้องค์กรปรับใช้โมเดลจริงได้เร็วขึ้น 4–8 เท่า ตัวอย่างเช่น ถ้าองค์กรเดิมออกฟีเจอร์ใหม่ได้ 4 ครั้ง/ปี การใช้ Composer อาจเพิ่มเป็น 12–16 ครั้ง/ปี ซึ่งเพิ่มโอกาสสร้างรายได้จากฟีเจอร์ใหม่ (เช่น การทดลอง A/B ได้บ่อยขึ้น เพิ่มอัตราการแปลงลูกค้า) — หากฟีเจอร์ใหม่สร้างรายได้เฉลี่ย 50,000 USD/ฟีเจอร์ ต่อปี การเพิ่มความถี่ 8 ฟีเจอร์/ปี จะเป็นรายได้เพิ่มประมาณ 400,000 USD/ปี
การประเมิน ROI และจุดคุ้มทุน — การคำนวณ ROI จะแปรผันตามขนาดองค์กรและรูปแบบการใช้งาน แต่ตัวอย่างประมาณการเชิงปฏิบัติได้ดังนี้ (สมมติค่าใช้จ่ายและการประหยัดเป็น USD เพื่อความชัดเจน):
- องค์กรขนาดกลาง (ทีม MLOps เดิม ~1.2 FTE): ต้นทุนบุคลากรเดิม ~180,000 USD/ปี → ลดเหลือ ~45,000 USD/ปี เมื่อใช้ Composer (บันทึก ~135,000 USD/ปี). หาก Composer มีราคาสมัครรับบริการระดับกลาง ~5,000 USD/เดือน (60,000 USD/ปี) และค่าใช้จ่ายติดตั้งครั้งแรก 15,000 USD: ปีแรกต้นทุนรวม = 75,000 USD; ผลประหยัดรวม (บุคลากร + ค่าโครงสร้างพื้นฐาน) ประมาณ 165,000 USD/ปี → จุดคุ้มทุน (payback) ประมาณ 5–6 เดือน
- องค์กรขนาดใหญ่ (ทีม MLOps เดิม ~4 FTE): ต้นทุนบุคลากรเดิม ~600,000 USD/ปี → ลดเหลือ ~150,000 USD/ปี เมื่อใช้ Composer (บันทึก ~450,000 USD/ปี). หากเลือกสัญญาแบบ enterprise license ราคาประมาณ 200,000 USD/ปี พร้อมค่า integration 50,000 USD ปีแรกต้นทุนรวม = 250,000 USD; ผลประหยัดรวม ~450,000 USD/ปี → จุดคุ้มทุน ประมาณ 6–8 เดือน
หมายเหตุ: ตัวเลขข้างต้นเป็นการประมาณการเชิงตัวอย่างและขึ้นอยู่กับค่าจ้างจริง โครงสร้างทีม และปริมาณการใช้งาน cloud ในแต่ละองค์กร แต่สรุปได้ว่าในหลายกรณี Auto‑MLOps Composer สามารถคืนทุนได้ภายในไม่กี่เดือนถึงภายในปีแรกของการใช้งาน และให้ผลประโยชน์ต่อเนื่องในปีถัดไป
ตัวอย่างสัญญา/โมเดลการคิดราคา — ผู้ให้บริการประเภทนี้มักเสนอรูปแบบราคา 3 แบบหลัก:
- Subscription (SaaS): จ่ายรายเดือน/ปี สำหรับแพลตฟอร์ม ใช้งานได้ตามแพ็กเกจ (เช่น 1,000–10,000 USD/เดือน ขึ้นกับฟีเจอร์และ SLA) เหมาะกับองค์กรที่ต้องการต้นทุนคงที่และลดภาระการดูแลระบบ
- Usage‑based: คิดตามการใช้งานจริง เช่น จำนวน pipeline run, ชั่วโมงคอมพิวต์ หรือปริมาณ data processed (ตัวอย่าง: 0.10–0.50 USD/compute‑hour เพิ่มขึ้นตามสเปค) ช่วยให้ต้นทุนสอดคล้องกับการใช้งานจริง แต่คาดการณ์ค่าใช้จ่ายยากขึ้นเมื่อปริมาณเติบโต
- Enterprise license + Professional services: คิดเป็นสัญญารายปีแบบเหมาจ่ายพร้อมการติดตั้ง ปรับแต่ง และ SLA สูง (ตัวอย่าง: 100,000–500,000 USD/ปี ขึ้นกับขนาดองค์กร) เหมาะสำหรับองค์กรใหญ่ที่ต้องการการรับประกันด้านความปลอดภัย การรวมระบบภายใน และการสนับสนุนเชิงกลยุทธ์
สรุปเชิงกลยุทธ์ — การนำ Auto‑MLOps Composer เข้ามาใช้ช่วยลดต้นทุนบุคลากรและชั่วโมงงานเชิงโครงสร้างพื้นฐานอย่างมีนัยสำคัญ เพิ่มความเร็วในการออกฟีเจอร์และทดลอง (accelerated experimentation) และมักให้ ROI ที่ชัดเจนภายใน 6–12 เดือนสำหรับองค์กรขนาดกลางถึงใหญ่ การเลือกโมเดลราคา (subscription, usage‑based, enterprise) ควรพิจารณาจากแผนการเติบโต ปริมาณการรัน pipeline และความต้องการเรื่อง SLA/การปรับแต่ง — โดยภาพรวม Composer จะเป็นตัวเร่งสำคัญที่ช่วยให้ทีมธุรกิจและทีมวิศวกรรมโฟกัสที่คุณค่าเชิงธุรกิจและนวัตกรรม มากกว่าการจัดการระบบพื้นฐานของ MLOps
การยอมรับเชิงอุตสาหกรรม พันธมิตร และระบบนิเวศ
การยอมรับเชิงอุตสาหกรรมและพันธมิตรเชิงเทคโนโลยี
Auto‑MLOps Composer เริ่มได้รับความสนใจจากผู้ให้บริการคลาวด์รายใหญ่และผู้ให้บริการโมเดลภายนอกอย่างรวดเร็ว โดยกลยุทธ์ของสตาร์ทอัพมุ่งไปที่การสร้างความสามารถในการเชื่อมต่อแบบ native กับแพลตฟอร์มสำคัญ เช่นการเตรียม *certified integrations* กับ AWS, Google Cloud Platform และ Microsoft Azure เพื่อรองรับการรันงานทั้งบนคลาวด์สาธารณะและสภาพแวดล้อมแบบไฮบริด/ออน‑พรีมิส การผสานรวมกับผู้ให้บริการ LLM ชั้นนำ (เช่น OpenAI, Anthropic) รวมถึงการออกแบบ connector สำหรับ Local LLMs ช่วยให้ลูกค้าองค์กรสามารถเลือกใช้โมเดลตามนโยบายความเป็นส่วนตัวและความต้องการเชิงประสิทธิภาพได้อย่างยืดหยุ่น
ในเชิงสถิติจากการสำรวจเชิงตลาดภายในของสตาร์ทอัพ พบว่าลูกค้าองค์กรกว่า 60% ให้ความสำคัญกับความสามารถในการเชื่อมต่อกับคลาวด์และโมเดลภายนอกเป็นปัจจัยชี้ขาดก่อนตัดสินใจใช้งาน โดยที่กลุ่มที่ทดลองใช้งานเบื้องต้นสามารถลดเวลาในการนำโมเดลจากสภาพแวดล้อมทดสอบสู่การใช้งานจริงได้จากเฉลี่ย 3–4 สัปดาห์ เหลือเพียง 2–6 ชั่วโมงในกรณีที่ใช้ Composer ร่วมกับ pipeline อัตโนมัติ ซึ่งตัวเลขนี้เป็นตัวอย่างการเพิ่มผลผลิตที่เห็นได้ชัดสำหรับโปรเจกต์ทดลองเชิงพาณิชย์
กลุ่มอุตสาหกรรมเป้าหมายและผลประโยชน์เชิงธุรกิจ
กลุ่มอุตสาหกรรมที่คาดว่าจะได้รับประโยชน์สูงสุด ได้แก่:
- การเงิน — ใช้ในระบบตรวจจับการฉ้อโกง, การให้คะแนนสินเชื่อแบบเรียลไทม์ และแชตบอทสำหรับบริการลูกค้า โดยการอัปเดตโมเดลที่ถี่ขึ้นช่วยลดความเสี่ยงและปรับกลยุทธ์ได้ทันสถานการณ์
- สาธารณสุข — ใช้เพื่อการวิเคราะห์ภาพทางการแพทย์, ระบบช่วยตัดสินใจทางคลินิก และการจัดการข้อมูลผู้ป่วยอย่างปลอดภัย โดย Composer ช่วยให้กระบวนการทดสอบและการตรวจสอบความถูกต้องเป็นไปอย่างรวดเร็วตามข้อกำหนดทางกฎระเบียบ
- e‑commerce — ใช้สำหรับระบบแนะนำสินค้า, การค้นหาเชิงภาษาธรรมชาติ และการปรับปรุงประสบการณ์ลูกค้าแบบเรียลไทม์ ส่งผลให้ยอดขายและอัตราการแปลงดีขึ้นจากการปรับใช้โมเดลที่ตอบโจทย์ลูกค้าได้ทันเวลา
อุตสาหกรรมเหล่านี้มักมีงบประมาณด้าน AI/ML สูงและเห็นผลตอบแทนจากการนำโมเดลไปใช้งานจริงได้รวดเร็ว จึงเป็นกลุ่มลูกค้าที่พร้อมทดลองใช้เครื่องมือที่ช่วยลดเวลานำสู่การใช้งานจริงและเพิ่มความถี่ในการฝึก/อัปเดตโมเดล
แผนขยายตลาดและการสรรหาลูกค้าองค์กร
กลยุทธ์การเติบโตของสตาร์ทอัพประกอบด้วยการผสมผสานระหว่างการขายแบบตรงสู่ลูกค้าองค์กร (enterprise sales) และการสร้างพันธมิตรเชิงช่องทาง เช่น system integrators, managed service providers และ cloud partners เพื่อขยายการเข้าถึงแบบภูมิภาค โดยแผนการขยายตลาดแบ่งเป็น 3 ระยะหลัก: (1) ขยายฐานลูกค้าในภูมิภาคอาเซียนและเอเชียแปซิฟิก, (2) ใช้โมเดล POC และ pilot ที่ออกแบบเฉพาะสำหรับอุตสาหกรรมเพื่อพิสูจน์มูลค่าเชิงธุรกิจ, และ (3) ขยายเป็นตลาดสากลผ่านพันธมิตรระดับโลกและการรับรองด้านความปลอดภัยข้อมูล (เช่น ISO 27001, SOC 2) เพื่อเอื้อต่อการขายให้กับองค์กรที่มีข้อกำหนดด้านกฎระเบียบเข้มงวด
นอกจากนี้ สตาร์ทอัพยังให้ความสำคัญกับการสร้างทีมพัฒนาธุรกิจสำหรับบัญชีลูกค้าองค์กรขนาดใหญ่ การจัดโปรแกรมฝึกอบรมสำหรับทีมเทคนิคของลูกค้า และการนำเสนอโมเดลการคิดค่าบริการที่ยืดหยุ่น (subscription, consumption‑based) เพื่อลดข้อกังวลด้านงบประมาณและเร่งการตัดสินใจซื้อ
โอกาสสำหรับระบบนิเวศ (ecosystem) และ marketplace
Auto‑MLOps Composer เปิดโอกาสให้เกิด ecosystem ที่หลากหลาย ทั้งในแง่ของ marketplace สำหรับ pipeline templates, pre‑built model connectors, และ components สำหรับ governance & monitoring ซึ่งจะช่วยให้ลูกค้าสามารถเลือกใช้ชุดงานที่เหมาะสมได้ทันทีโดยไม่ต้องออกแบบใหม่ทั้งหมด ตัวอย่างของโอกาสเชิงธุรกิจได้แก่:
- Marketplace สำหรับ templates — ชุด pipeline สำเร็จรูปสำหรับแต่ละอุตสาหกรรม (เช่น template สำหรับ KYC ในการเงิน หรือ template สำหรับการจัดการภาพทางการแพทย์)
- โมเดลธุรกิจร่วมกันกับพันธมิตร — ระบบแบ่งรายได้กับผู้ให้บริการโมเดลและผู้พัฒนา templates
- ชุมชนผู้พัฒนาและการมีส่วนร่วม — การเปิด API และ SDK เพื่อให้ชุมชนสามารถสร้าง connectors/ops ใหม่ ๆ และแบ่งปันผ่าน marketplace ซึ่งช่วยลดเวลาการพัฒนาและเพิ่มความหลากหลายของโซลูชัน
การมี marketplace และ community contributions ยังช่วยผลักดันการนำไปใช้เชิงพาณิชย์ให้เร็วขึ้น — ในการทดลองเชิงภายในพบว่าองค์ประกอบสำเร็จรูปจาก marketplace สามารถลดเวลา POC ลงได้ถึง 20–30% และช่วยให้ลูกค้าเห็นคุณค่าได้เร็วขึ้น นอกจากนี้ ระบบนิเวศที่เข้มแข็งยังเป็นฐานให้สตาร์ทอัพสร้างรายได้เสริมจากการให้บริการระดับมืออาชีพ การรับรองของพาร์ทเนอร์ และโมดูลเสริมเฉพาะอุตสาหกรรม
โดยรวมแล้ว การยอมรับเชิงอุตสาหกรรมและการสร้างพันธมิตรเชิงกลยุทธ์เป็นหัวใจสำคัญของการขยายตัวสำหรับ Auto‑MLOps Composer — แต่ความสำเร็จระยะยาวจะขึ้นอยู่กับการจัดการความเสี่ยงด้านความเป็นส่วนตัว ความปลอดภัยของข้อมูล และการหลีกเลี่ยงการผูกติดกับผู้ให้บริการรายใดรายหนึ่ง (vendor lock‑in) เพื่อให้ลูกค้ามีเสรีภาพในการเลือกเทคโนโลยีที่เหมาะสมที่สุดกับบริบทของตน
ความเสี่ยง ข้อจำกัด และทิศทางอนาคต
ความเสี่ยง ข้อจำกัด และทิศทางอนาคต
เมื่อองค์กรนำระบบ Auto‑MLOps Composer ไปใช้งานจริง จำเป็นต้องตระหนักถึงความเสี่ยงเชิงเทคนิคและเชิงนโยบายที่มาพร้อมกับการปรับใช้ LLM ในสเกลการผลิต แม้แพลตฟอร์มจะช่วยลดเวลาจากสัปดาห์เหลือชั่วโมงในการ deploy แต่ยังมีประเด็นสำคัญที่ต้องบริหารจัดการ ได้แก่ ความเสี่ยงด้านข้อมูลและการปฏิบัติตามกฎหมาย (เช่น PDPA และ GDPR), ความเอนเอียงของโมเดล (bias), การเปลี่ยนแปลงของโมเดลเมื่อเวลาผ่านไป (model drift), รวมถึงข้อจำกัดด้านค่าใช้จ่ายและประสิทธิภาพเมื่อสเกล LLM ขนาดใหญ่
ด้านความปลอดภัยของข้อมูลและการปฏิบัติตามกฎหมาย — การใช้งาน LLM ในงานที่เกี่ยวข้องกับข้อมูลส่วนบุคคลต้องสอดคล้องกับข้อกำหนดของ PDPA/GDPR โดยปฏิบัติที่แนะนำประกอบด้วยการทำ data minimization, การแยกและเข้ารหัสข้อมูลสำคัญ, การจัดการสิทธิ์การเข้าถึงระดับบทบาท, และการเก็บบันทึก (audit logs) สำหรับทุกการเรียกใช้งาน ตัวอย่างเช่น การออกแบบ pipeline ให้สามารถระบุและทำ anonymization ข้อมูล PII อัตโนมัติก่อนส่งให้โมเดล รวมถึงการทำ Data Protection Impact Assessment (DPIA) เป็นขั้นตอนก่อนการเปิดใช้งานระบบใน production
- แนวทางป้องกัน: สร้าง workflow สำหรับการลบหรือทำให้ไม่ระบุตัวตน (anonymize/pseudonymize) ของข้อมูล, บังคับใช้การเข้ารหัสทั้งขณะพักและขณะส่ง, และกำหนดนโยบาย retention ให้ชัดเจน
- การปฏิบัติตามกฎหมาย: เก็บหลักฐานการยินยอมและขอ consent เมื่อจำเป็น, จัดทำเอกสารความเสี่ยงและการควบคุม (compliance reports) สำหรับการตรวจสอบภายใน/ภายนอก
ข้อจำกัดเมื่อสเกล LLM ขนาดใหญ่ — การขยายบริการ LLM ในระดับการให้บริการจริงมีผลต่อค่าใช้จ่ายและประสิทธิภาพโดยตรง สำหรับงาน inference ค่าใช้จ่าย CPU/GPU อาจเป็นต้นทุนหลัก: โดยทั่วไปเมื่อนำโมเดลขนาดหลายร้อยล้านถึงหลายหมื่นล้านพารามิเตอร์มาใช้งาน ต้นทุนต่อคำตอบ (per‑inference) อาจสูงขึ้นเป็นทวีคูณ และ latency อาจเพิ่มจากระดับหลักสิบมิลลิวินาทีเป็นหลักร้อยถึงหลักพันมิลลิวินาทีหากไม่มีการปรับสเกลหรือแคชที่เหมาะสม (ตัวอย่างเช่น latency เป้าหมายสำหรับงาน UI อาจต้องอยู่ในช่วง 50–300 ms) การจัดสรรทรัพยากรและการบริหารค่าใช้จ่ายจึงเป็นสิ่งจำเป็น
- แนวทางลดต้นทุน: ใช้เทคนิคเช่น model quantization, distillation เพื่อสร้างโมเดลขนาดเล็กลง, ใช้ batching และ request pooling, ตั้งค่า autoscaling ที่ชาญฉลาด และพิจารณาการผสมระหว่างเรียกใช้ API กับการโฮสต์ภายใน
- บริหาร latency: ใช้ edge caching, warm pools ของ GPU, และกลยุทธ์แบบ canary/blue‑green เพื่อควบคุมประสบการณ์ผู้ใช้ที่มีความหน่วงต่ำ
ปัญหาเชิงปฏิบัติการ (Operational) — การทำให้โมเดลสามารถทำงานได้อย่างต่อเนื่องและเชื่อถือได้ต้องแก้ไขปัญหาด้าน dependency management, reproducibility และ testing coverage อย่างเป็นระบบ Dependency ล้มเหลวหรือการเปลี่ยนเวอร์ชันของไลบรารีสามารถทำให้ pipeline แตกต่างจากสภาพแวดล้อมการทดลองได้ง่าย ซึ่งส่งผลให้ยากต่อการ reproduce ผลลัพธ์
- มาตรการเชิงเทคนิค: ใช้ containerization (เช่น Docker), Infrastructure as Code (เช่น Terraform), ระบบจัดการ artifact/experiment (เช่น MLflow, DVC, model registry) และล็อกเวอร์ชันของไลบรารีและ environment อย่างเคร่งครัด
- การทดสอบ: ขยายชุดทดสอบให้ครอบคลุม unit test, integration test, regression test และคิวริกซ์เชิงประสิทธิภาพ รวมถึงทดสอบเชิงพฤติกรรมด้วยชุดข้อมูลจริงและชุดข้อมูลเชิงก่อกวน (adversarial/synthetic) เพื่อจับ bias และ regression ก่อน deployment
- การตรวจสอบอย่างต่อเนื่อง: ติดตั้งระบบมอนิเตอร์สำหรับ drift detection (เช่น ตรวจวัดความเปลี่ยนแปลงของ distribution ของ input/outcome), alerting thresholds, และ feedback loop จากผู้ใช้เพื่อปรับปรุงโมเดล
ทิศทางอนาคตและ roadmap ฟีเจอร์ที่คาดว่าจะตามมา — สำหรับผลิตภัณฑ์ Auto‑MLOps Composer ควรพัฒนาเป็นขั้นตอนตามความต้องการเชิงปฏิบัติการและการกำกับควบคุม ตัวอย่าง roadmap ที่เป็นไปได้ ได้แก่
- Automated hyperparameter tuning — รองรับการค้นหาแบบอัตโนมัติ (Bayesian optimization, Populations) เพื่อให้กระบวนการ fine‑tune เร็วและมีประสิทธิภาพมากขึ้น
- Tighter governance tools — เพิ่มฟีเจอร์เช่น policy enforcement engine, audit trail อัตโนมัติ, model cards และ compliance templates สำหรับ PDPA/GDPR เพื่อให้องค์กรสามารถแสดงหลักฐานการควบคุมได้ทันที
- Multi‑model orchestration — สนับสนุนการจัดการหลายโมเดลแบบไดนามิก (model routing, A/B testing, ensemble selection) เพื่อปรับใช้โมเดลที่เหมาะสมกับบริบทและลดความเสี่ยงจาก single‑model failure
- Explainability & bias detection — ผสานเครื่องมือการอธิบายคำตอบ (explainability) และการประเมิน bias แบบอัตโนมัติเพื่อลดความเสี่ยงด้านความเอนเอียงของโมเดล
- Cost‑aware deployment — ฟีเจอร์ที่ช่วยคำนวณและจำกัดงบประมาณแบบเรียลไทม์ รวมทั้งคำแนะนำในการใช้เทคนิคลดต้นทุนอัตโนมัติ
ข้อเสนอแนะสำหรับองค์กรที่ต้องการนำไปใช้ — แนะนำให้องค์กรเริ่มจากโครงการนำร่องที่มีขอบเขตชัดเจนเพื่อวัดผลทั้งด้านประสิทธิภาพ ค่าใช้จ่าย และความเสี่ยง ตั้งคณะกรรมการกำกับดูแล (AI governance board) เพื่อกำหนดนโยบายการใช้งานข้อมูลและการประเมินความเสี่ยงทางจริยธรรม ฝึกอบรมทีมด้าน DevOps/ML Ops ให้คุ้นเคยกับแนวปฏิบัติที่ดี เช่น การ versioning ข้อมูลและโมเดล การทดสอบแบบอัตโนมัติ และการติดตามประสิทธิภาพอย่างต่อเนื่อง
- เริ่มจาก PoC ขนาดเล็ก ตั้งค่า SLA และ KPIs ชัดเจน (เช่น latency, accuracy, cost per 1k requests)
- เตรียมมาตรการทางกฎหมายและสัญญาที่ชัดเจนเมื่อใช้บริการคลาวด์หรือ third‑party APIs เพื่อป้องกันปัญหาเรื่อง data residency และ vendor lock‑in
โดยสรุป แม้ Auto‑MLOps Composer จะเป็นเครื่องมือที่ช่วยย่นระยะเวลาในการนำ LLM ไปใช้จริง แต่ความสำเร็จเชิงธุรกิจจะขึ้นอยู่กับการวางกรอบการบริหารความเสี่ยงที่รัดกุม การลงทุนในโครงสร้างพื้นฐานและการทดสอบที่เพียงพอ รวมถึงการพัฒนาเครื่องมือการกำกับดูแลและการควบคุมที่สามารถรองรับการสเกลในอนาคตได้อย่างปลอดภัยและคุ้มค่า
บทสรุป
Auto‑MLOps Composer เป็นเครื่องมือที่ออกแบบมาเพื่อลดความซับซ้อนและย่นเวลาการนำ Large Language Models (LLM) สู่การใช้งานจริง ด้วยแนวคิด "คลิกเดียว" ในการสร้าง pipeline CI/CD สำหรับโมเดล ทำให้กระบวนการที่เคยกินเวลาหลายสัปดาห์ในการติดตั้ง ทดสอบ และปรับจูน สามารถเหลือเพียงชั่วโมง ตัวอย่างเช่น ทีมพัฒนาบางรายระบุว่าสามารถลดเวลา deployment จากประมาณ 2 สัปดาห์เหลือเพียง 3–4 ชั่วโมง ซึ่งสอดคล้องกับการลดเวลาที่องค์กรต้องใช้ในงานซ้ำซ้อน เช่น การจัดการเวอร์ชันโมเดล การทดสอบการถดถอย และการตั้งค่า environment ทำให้เหมาะสำหรับ องค์กรที่ต้องการออกแบบ CI/CD สำหรับโมเดลอย่างเป็นระบบ และต้องการมาตรฐานการผลิตที่ทำซ้ำได้
การนำไปใช้จริงยังต้องคำนึงถึงปัจจัยสำคัญด้านการกำกับดูแล (governance), การบริหารต้นทุน (cost management) และการผสานรวมกับระบบเดิม (system integration) — หากละเลยด้านเหล่านี้แม้เครื่องมือจะช่วยเร่งเวลา แต่ก็อาจเกิดความเสี่ยงด้านการควบคุมข้อมูล ค่าใช้จ่ายคลาวด์พุ่ง และความไม่เข้ากันของสถาปัตยกรรม ในการตัดสินใจเลือกใช้งาน ควรประเมินกรณีใช้งานเชิงธุรกิจ ผลลัพธ์เชิงตัวเลข (เช่น เวลาในการนำขึ้นจริง อัตราความผิดพลาด ความคุ้มค่าในการลงทุน) และ roadmap ของผู้ให้บริการ เพื่อให้มั่นใจว่าฟังก์ชันด้านความปลอดภัย การอัปเดตโมเดล และการสนับสนุนจะสอดคล้องกับแผนระยะยาวขององค์กร
คำแนะนำ: ให้เริ่มทดลองกับกรณีการใช้งานที่มีขอบเขตจำกัด วัดผลเป็นตัวเลข แล้วค่อยขยายการใช้งานเมื่อแน่ใจใน governance และ cost management



