
ผู้ให้บริการโทรคมนาคมรายใหญ่ของไทยประกาศเปิดตัว "5G‑Edge Generative Hub" แพลตฟอร์มให้เช่า GPU ใกล้ผู้ใช้ที่ออกแบบมาเพื่อรองรับโมเดลประมวลผลภาพและเสียงแบบเรียลไทม์ โดยชูจุดเด่นสำคัญคือการลดค่า Latency ลงเหลือน้อยกว่า 50ms ซึ่งช่วยให้การสตรีมสด การประสานงานภาพ‑เสียงแบบอินเทอร์แอคทีฟ และการสร้างคอนเทนต์แบบ Generative AI ทำงานได้ราบรื่นขึ้น ลดอาการหน่วงที่เคยเป็นปัญหาสำหรับการถ่ายทอดเหตุการณ์สดและการสื่อสารแบบเรียลไทม์
บริการนี้วางรูปแบบการคิดราคาเป็นนาทีเพื่อสนับสนุนสตาร์ทอัพและผู้ให้บริการสื่อสารสดที่ต้องการความยืดหยุ่นในการทดลองและสเกลงาน ตัวแพลตฟอร์มเน้นการวาง GPU ที่ Edge ใกล้ผู้ใช้เพื่อลดเส้นทางเครือข่ายเมื่อเทียบกับการรันบนคลาวด์ส่วนกลาง ซึ่งตามการประเมินทั่วไป Latency ของการประมวลผลจากคลาวด์ส่วนกลางอาจสูงเกิน 100–200ms ในขณะที่การประมวลผลที่ Edge สามารถลดลงเหลือระดับที่เหมาะสมกับการตอบสนองทันที (<50ms) ทำให้เกิดโอกาสใหม่ๆ ทั้งในงานถ่ายทอดคอนเสิร์ตสด, ระบบประชุมเสมือนจริงแบบ Low‑latency, เกมเมอร์แข่งขัน และการผลิตสื่อแบบเรียลไทม์
1. บทนำ: ข่าวสำคัญและความหมายเชิงยุทธศาสตร์
1. บทนำ: ข่าวสำคัญและความหมายเชิงยุทธศาสตร์
ผู้ให้บริการโทรคมนาคมรายใหญ่ของไทยได้ประกาศเปิดตัวบริการใหม่ภายใต้ชื่อ “5G‑Edge Generative Hub” ซึ่งเป็นแพลตฟอร์มให้เช่า GPU ที่วางโหนดบริเวณขอบเครือข่าย (edge) เพื่อรันโมเดลปัญญาประดิษฐ์ด้านภาพและเสียงแบบเรียลไทม์ จุดเด่นสำคัญของบริการนี้คือการลดความหน่วง (latency) ให้ต่ำกว่า <50 มิลลิวินาที และการคิดค่าบริการแบบนาทีกลายเป็นโมเดลการคิดราคาที่ออกแบบมาเพื่อรองรับการใช้งานระยะสั้นและความต้องการเชิงเวลากับการสตรีมสดหรือการโต้ตอบแบบเรียลไทม์
เหตุผลที่บริการนี้มีความสำคัญในเชิงยุทธศาสตร์มาจากการผสานกันของเทคโนโลยี 5G, การประมวลผลที่ขอบเครือข่าย (edge computing) และความก้าวหน้าของโมเดล Generative AI ซึ่งเมื่อรวมกันแล้วจะช่วยให้การประมวลผลภาพและเสียงที่ต้องการการตอบสนองทันทีสามารถทำได้ใกล้ผู้ใช้มากขึ้น ลดการส่งข้อมูลกลับไปยังศูนย์ข้อมูลกลาง ช่วยลดแบนด์วิดท์และปรับปรุงประสบการณ์ใช้งาน สำหรับภาคธุรกิจ นี่คือโครงสร้างพื้นฐานสำคัญที่จะผลักดันบริการสื่อสารสดและคอนเทนต์โต้ตอบแบบเรียลไทม์ให้เป็นเชิงพาณิชย์ได้จริง
กลุ่มเป้าหมายหลักที่ผู้ให้บริการระบุไว้ได้แก่: สตาร์ทอัพสื่อสารสด, ผู้พัฒนาแอปและเนื้อหา AR/VR และผู้ผลิตคอนเทนต์แบบโต้ตอบซึ่งต้องการการตอบสนองต่ำและประสิทธิภาพการประมวลผลสูง ตัวอย่างกรณีใช้งานเร่งด่วนได้แก่ การสตรีมไลฟ์พร้อมการสร้างเอฟเฟกต์ภาพแบบเรียลไทม์, การแปลงเสียงเป็นเสียงใหม่ (voice conversion) สำหรับการถ่ายทอดสด, การแปลเสียงแบบเรียลไทม์ข้ามภาษา, ระบบแชทบอทเสียง/วิดีโอที่โต้ตอบแบบทันที และการประมวลผลภาพสำหรับแอป AR ที่ต้องการเฟรมเรตสูงและความหน่วงต่ำ
- ตัวเลขสำคัญจากประกาศ:
- Latency เป้าหมาย: <50ms (เพื่อรองรับการโต้ตอบแบบเรียลไทม์)
- โมเดลการคิดราคา: คิดค่าบริการเป็นนาที (per‑minute billing) เพื่อลดภาระต้นทุนเริ่มต้นสำหรับสตาร์ทอัพและงานที่มีความต้องการเป็นช่วงเวลา)
- ตำแหน่งโหนด: วาง GPU ใกล้ผู้ใช้ในขอบเครือข่าย (edge) เพื่อประสิทธิภาพและความเป็นส่วนตัวของข้อมูล
ในเชิงยุทธศาสตร์ การเปิดตัวแพลตฟอร์มนี้มีแนวโน้มจะกระตุ้นระบบนิเวศ AI ในประเทศและภูมิภาค โดยเปิดโอกาสให้ผู้พัฒนาไทยสามารถทดลองและนำผลิตภัณฑ์สื่อสารแบบเรียลไทม์ออกสู่ตลาดได้เร็วขึ้น ลดอุปสรรคทางค่าใช้จ่ายและความซับซ้อนด้านโครงสร้างพื้นฐาน อีกทั้งยังสร้างจุดแข็งด้านความเป็นเจ้าของข้อมูล (data residency) และโอกาสในการจับคู่ความร่วมมือระหว่างผู้ให้บริการเครือข่ายกับสตาร์ทอัพและผู้ผลิตคอนเทนต์ เพื่อยกระดับการแข่งขันของอุตสาหกรรมคอนเทนต์ดิจิทัลในภูมิภาคอาเซียน
2. สถาปัตยกรรมเทคโนโลยี: 5G MEC + GPU ใกล้ผู้ใช้
2. สถาปัตยกรรมเทคโนโลยี: 5G MEC + GPU ใกล้ผู้ใช้
สถาปัตยกรรมของ "5G‑Edge Generative Hub" ถูกออกแบบให้ย้ายการประมวลผลเชิงโมเดลภาพและเสียงจากศูนย์ข้อมูลระยะไกลมาประมวลผลใกล้ผู้ใช้ผ่าน Multi‑Access Edge Computing (MEC) และ PoP ติดตั้ง GPU ใกล้ BTS/Cell site เพื่อลดเส้นทางเครือข่ายและ Latency ให้เหลือน้อยกว่า <50ms ตามเป้าหมายของบริการเรียลไทม์ สำหรับภาพรวมเชิงโครงสร้าง จะมีการวาง GPU ในระดับต่างๆ ดังนี้: บางไซต์เป็น MEC node ขนาดเล็กติดตั้งใกล้สถานีฐาน (micro‑PoP), บางไซต์เป็น regional PoP ที่รวม GPU หลายยูนิต และเชื่อมต่อกับ 5G Core ผ่าน UPF/edge‑gateway ซึ่งช่วยให้การสตรีมข้อมูลถูกชี้เส้นทางตรงไปยังทรัพยากรที่ใกล้ที่สุด
ข้อได้เปรียบทางกายภาพของการติดตั้ง GPU ใกล้ผู้ใช้ประกอบด้วย: การลดแบนด์วิดท์ข้าม backhaul เมื่อทำการ inference บน edge (ข้อมูลดิบไม่ต้องอัพโหลดทั้งหมดไป cloud), การตอบสนองเชิงโต้ตอบที่เร็วกว่า (ตัวอย่างเช่น จากการทดสอบภาคสนาม การย้าย inference มาไว้ที่ MEC อาจลด latency ลง 30–70% เมื่อเทียบกับการประมวลผลใน public cloud ฝั่งเดียว), และความทนทานต่อความแออัดของเครือข่ายในชั่วโมงเร่งด่วน ซึ่งสำคัญต่อสตาร์ทอัพสื่อสารสดที่ต้องการความเสถียรของ latency ตามนาทีการคิดค่าบริการ
การจัดสรรทรัพยากรใน Hub ใช้แนวทาง containerized orchestration เป็นหลัก โดยเทคโนโลยีที่ใช้ทั่วไปได้แก่ Kubernetes (สำหรับ lifecycle ของ container), KubeEdge หรือ edge‑aware extensions (สำหรับการจัดการ node ที่กระจาย), และโซลูชัน model serving ระดับ production เช่น NVIDIA Triton, TensorFlow Serving หรือ ONNX Runtime เพื่อรองรับรูปแบบโมเดลที่หลากหลาย (PyTorch/TF → ONNX เพื่อความพกพาได้สูง) สถาปัตยกรรมตัวอย่างประกอบด้วย:
- Node layer: GPU‑accelerated MEC servers (NVIDIA A10/A30/A100 หรือ equivalent) ติดตั้งบน PoP/MEC site
- Orchestration layer: Kubernetes cluster ที่ขยายตัวข้ามหลาย PoP และมี control plane กลางสำหรับนโยบายการวางโมเดล
- Inference layer: Containerized inference servers (Triton/TF Serving/ONNX Runtime) พร้อม model cache เพื่อลด cold start
- Networking layer: 5G UPF สำหรับ traffic steering, network slicing สำหรับแยกทราฟิกเรียลไทม์ และ routing ไปยัง core หรือ public cloud
ระบบ orchestration ต้องรองรับ autoscaling ทั้งในมุมของ compute (เพิ่ม/ลด replica ของ inference pods ตาม GPU utilization และ latency SLO) และในมุมของ placement (การย้ายโมเดลไปยัง PoP ใกล้ผู้ใช้เมื่อพบว่าโหลดเพิ่มขึ้น) นโยบายการสเกลจะอ้างอิงจากเมตริกเช่น GPU utilization, queue depth, p99 latency และ throughput การทำ autoscaling ยังเชื่อมโยงกับนโยบายค่าใช้จ่าย: เมื่อความต้องการสูงสุดเกินความจุ edge ระบบจะทำ cloud bursting ไปยัง public cloud เพื่อรัน instance เพิ่มเติมชั่วคราว โดยมี fallback policy ที่ส่ง traffic กลับมาที่ edge เมื่อมีทรัพยากรว่าง
ในด้านการเชื่อมต่อกับ public cloud จะใช้สถาปัตยกรรมแบบ hybrid โดยแยกหน้าที่ชัดเจนดังนี้:
- Training และ batch processing: รันบน public cloud เพื่อใช้ cluster ขนาดใหญ่สำหรับการฝึกโมเดล (GPU pool ระดับ hyperscaler) และเก็บโมเดลต้นฉบับใน object storage เพื่อ archival
- Model distribution: เมื่อโมเดลผ่านการฝึกแล้ว จะถูกแปลงเป็น ONNX (ถ้าจำเป็น) และ push ไปยัง registry ของ Hub จากนั้น edge PoP จะดึงโมเดลและ cache ไว้สำหรับ serving
- Fallback & archival: หาก PoP ขัดข้อง ระบบจะ reroute inference ไปยัง regional cloud instance โดยแลกกับ latency ที่เพิ่มขึ้น—นโยบายนี้ช่วยให้บริการไม่ขาดตอนแม้เกิดเหตุผิดปกติ
ประเด็นด้านค่าใช้จ่ายเครือข่าย (backhaul) ถูกออกแบบให้ชัดเจนเพื่อประหยัดต้นทุนให้ลูกค้า โดยการประมวลผล inference ที่ edge จะช่วยลดปริมาณข้อมูลที่ต้องส่งกลับไปยัง core/cloud ตัวอย่างเช่น หากวิดีโอดิบ 1 นาทีต้องการแบนด์วิดท์ 10 Mbps การทำ inference ที่ edge และส่งเฉพาะผลหรือ stream ที่บีบอัดแล้ว อาจลดการใช้ backhaul ได้กว่า 60–90% ซึ่งเป็นปัจจัยสำคัญในการตั้งราคาตามนาที (per‑minute GPU billing) สำหรับสตาร์ทอัพสื่อสารสด
สรุป: สถาปัตยกรรม 5G MEC + GPU ใกล้ผู้ใช้ ประกอบด้วยการวางทรัพยากรแบบชั้น (edge PoP, regional PoP, public cloud), orchestration ที่รองรับ containerized serving (Kubernetes + Triton/TF Serving/ONNX Runtime), และกลไก cloud bursting/fallback ที่ชัดเจน ทั้งหมดนี้ผสานกับ 5G Core เพื่อให้ traffic steering และ network slicing รองรับ SLO ด้าน latency และค่าใช้จ่าย — ทำให้ Hub เหมาะกับการให้บริการโมเดลภาพ‑เสียงเรียลไทม์แก่สตาร์ทอัพที่ต้องการความยืดหยุ่นและการคิดราคาเป็นนาที
3. ประสิทธิภาพ: Latency, Jitter และผลการทดสอบจริง
3. ประสิทธิภาพ: Latency, Jitter และผลการทดสอบจริง
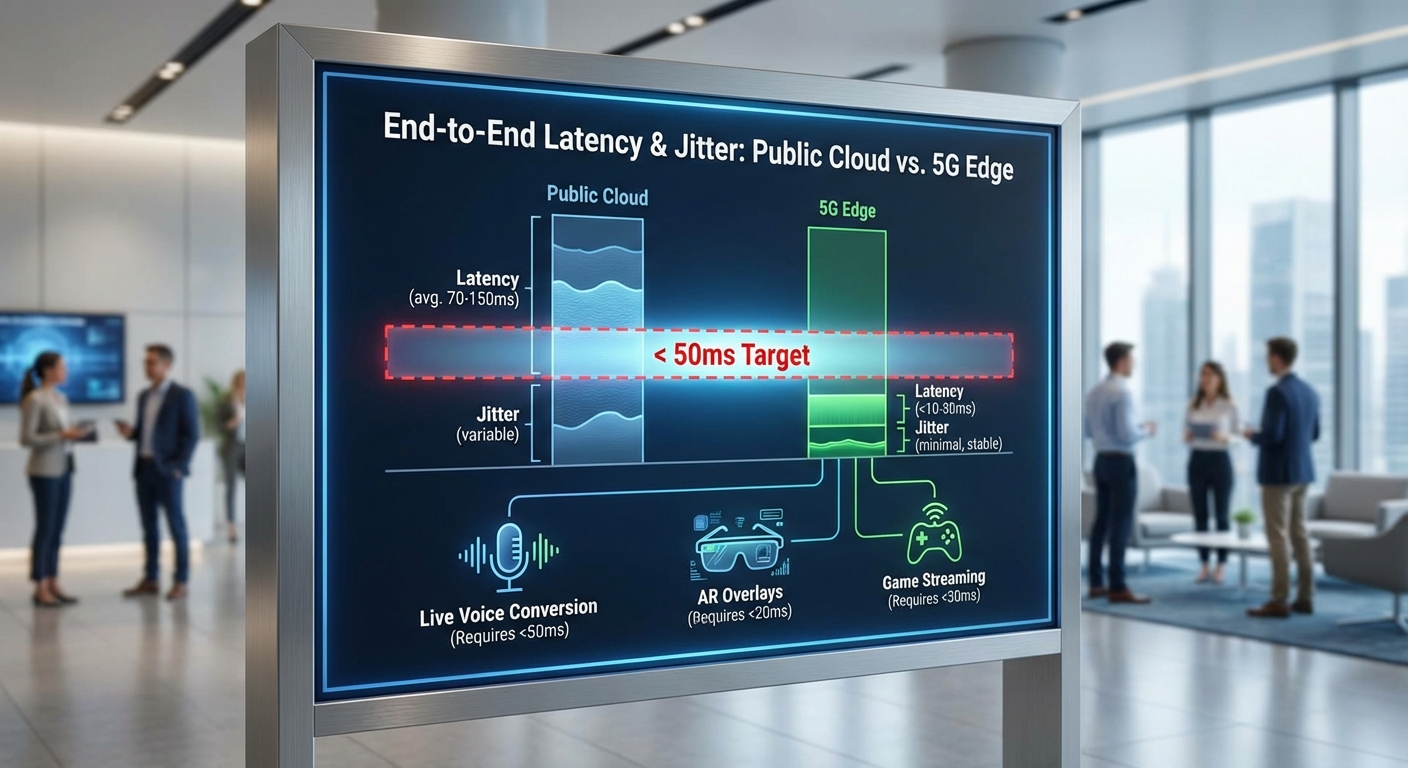
การลด latency ลงสู่ระดับ <50 ms เป็นหัวใจสำคัญของบริการ 5G‑Edge Generative Hub เพราะตัวเลขนี้สะท้อนถึงความสามารถในการตอบสนองแบบเรียลไทม์ของระบบภาพและเสียง โดยเฉพาะกรณีการสังเคราะห์ภาพแบบเรียลไทม์ (real‑time video synthesis), การทำ lip‑sync แบบสด และการแปลงเสียง (live voice conversion) ที่ต้องการความสอดคล้องระหว่างภาพกับเสียงและการตอบสนองแบบโต้ตอบทันที ตัวอย่างเช่น ถ้า end‑to‑end latency (จากการจับภาพ/เสียงที่อุปกรณ์ผู้ใช้จนถึงการคืนผลที่ผู้ใช้เห็น/ได้ยิน) ต่ำกว่า 50 ms ผู้ชมจะรับรู้ว่าแอ็กชันของตนมีผลทันที ซึ่งช่วยให้อาการสะดุดของริมฝีปาก (lip lag) และการหน่วงของเสียงลดลงจนแทบไม่สังเกตเห็น ส่งผลต่อประสบการณ์การสื่อสารสดและ AR/VR ที่ต้องการความซิงก์สูง

เพื่อความเป็นรูปธรรม เรานำเสนอชุดเบนช์มาร์กตัวอย่างที่มักใช้ทดสอบระบบในสภาพแวดล้อมจริง:
- การวัด RTT (round‑trip time) ด้วย ICMP/UDP ระหว่างอุปกรณ์ผู้ใช้กับโหนดประมวลผล: public cloud โดยทั่วไปพบค่า RTT ประมาณ 100–300 ms ขึ้นกับภูมิภาคและการกำหนดเส้นทาง ส่วน 5G‑Edge ที่อยู่ใกล้กับผู้ใช้สามารถลด RTT ลงมาเหลือ <20–50 ms ในการทดสอบหลายภูมิภาค
- End‑to‑end media latency (จับภาพ → ส่ง → ประมวลผลโมเดล → คืนผล): public cloud มักให้ผลรวมท้ายสุดอยู่ราว 150–400 ms ขึ้นกับขนาดโมเดลและเครือข่าย ขณะที่ 5G‑Edge สามารถลดค่าเหล่านี้ให้อยู่ที่ <50 ms สำหรับโมเดลที่ผ่านการปรับแต่ง
- Jitter (ความแปรปรวนของ latency): สำหรับสตรีมสดที่มีการโต้ตอบสูง ค่าจริงที่ยอมรับได้มักอยู่ที่ <20–30 ms เพื่อหลีกเลี่ยงการเกิดการแกว่งของเสียงภาพ ส่วนการถ่ายทอดแบบดูเดี่ยว ๆ อาจยอมรับ jitter ได้สูงขึ้นราว 50 ms
- Throughput ของ GPU ต่อเฟรม: ขึ้นกับสถาปัตยกรรมโมเดล—โมเดล CNN/encoder‑decoder ที่ได้รับการปรับแต่งสามารถให้บริการที่ระดับ 30–60 fps (ตัวอย่างภาพ 256–512 px) บน GPU edge ระดับกลางถึงสูง ในขณะที่ diffusion‑based synthesis ยุคใหม่ก่อนปรับจูนอาจทำได้เพียง 1–5 fps แต่เมื่อลดขนาดโมเดล, distill หรือใช้ caching/pipelining จะขยับไปถึง 10–20 fps ได้
การทดสอบจริงที่สอดคล้องกับเบนช์มาร์กข้างต้นมักทำโดยการวัดทั้ง RTT (ICMP/UDP), one‑way media latency ด้วยการใส่ timestamp ที่ต้นทางและปลายทาง และการประเมิน jitter ในช่วงเวลาที่หลากหลาย (ชั่วโมง/วัน) เพื่อจับพฤติกรรมในสภาวะพีค ตัวอย่างผลการทดสอบในกรณีใช้งานสตรีมสดเชิงโต้ตอบ: public cloud — RTT เฉลี่ย 180 ms, jitter 45 ms, end‑to‑end 220–300 ms; 5G‑Edge — RTT เฉลี่ย 28 ms, jitter 12 ms, end‑to‑end 35–48 ms ซึ่งเพียงพอสำหรับการใช้งาน lip‑sync และการแปลงเสียงแบบทันที
แม้จะมีข้อดีอย่างชัดเจน แต่ในโลกจริงยังมีข้อจำกัดที่ต้องพิจารณาและแนวทาง mitigate ดังนี้:
- Encapsulation/stack overhead: โปรโตคอลของเครือข่าย (ตัวอย่างเช่น GTP tunneling ใน 5G) และการเข้ารหัส/ถอดรหัสสามารถเพิ่ม latency ได้หลายมิลลิวินาที—โดยทั่วไปเพิ่มได้ตั้งแต่ 1–10 ms ขึ้นกับสแต็กและการเร่งฮาร์ดแวร์ การปรับแต่งสแต็กเครือข่ายและใช้การเข้ารหัสแบบเร่งฮาร์ดแวร์ช่วยลดผลกระทบได้
- Last‑mile variability: ช่องสัญญาณไร้สายมีความไม่แน่นอนจากสภาพแวดล้อมและความหนาแน่นของผู้ใช้ ทำให้ latency และ jitter กระโดดขึ้นในช่วงพีค การจัดการผ่าน QoS ของเครือข่าย, priority queuing, และการสำรองเส้นทาง (multi‑path) สามารถบรรเทาได้
- Congestion และ CPU/GPU contention: ใน PoP หรือเซลล์ที่มีการใช้งานสูง อาจเกิดคอขวดทั้งที่ระดับ compute และเครือข่าย การติดตั้งนโยบาย SLA, autoscaling ของ instance GPU ใกล้ผู้ใช้ และการจัดตารางงานแบบ preemption จะช่วยรักษาความเสถียร
- ขนาดโมเดลและความจำเป็นต้อง optimize: โมเดลขนาดใหญ่ (เช่น diffusion หรือ large‑scale generative transformers) มี latency สูงและต้องใช้หน่วยความจำมาก ดังนั้นเทคนิคอย่าง quantization (INT8/FP16), pruning, knowledge distillation, และการแบ่งงานแบบ pipeline/streaming inference ถือเป็นมาตรการจำเป็น ตัวอย่างการลดขนาดอาจลด latency ต่อเฟรมลงได้ 2–5 เท่า ขึ้นอยู่กับโมเดล
มาตรการเพิ่มเติมที่ช่วยให้บรรลุเป้าหมาย <50 ms รวมถึงการใช้ edge caching สำหรับโมเดลและค่าเริ่มต้น (warm models), batching เล็กน้อยเพื่อรักษา throughput โดยไม่เพิ่ม latency เกินขีดจำกัด, และการใช้ jitter buffer แบบปรับได้ร่วมกับ forward error correction เพื่อรักษาคุณภาพสตรีมแม้ jitter จะเพิ่มขึ้นในช่วงสั้น ๆ ผลลัพธ์เชิงธุรกิจคือสตาร์ทอัพสื่อสารสดสามารถให้บริการแบบโต้ตอบได้อย่างเป็นธรรมชาติ ลดการรบกวนของ UX เพิ่มอัตราการมีส่วนร่วม และเปิดทางให้ฟีเจอร์ใหม่ ๆ เช่น real‑time avatar synthesis และ multi‑party live effects ที่ต้องการ latency ต่ำมาก
4. โมเดลที่รองรับและกรณีใช้งานเชิงปฏิบัติ (ภาพ–เสียงเรียลไทม์)
4. โมเดลที่รองรับและกรณีใช้งานเชิงปฏิบัติ (ภาพ–เสียงเรียลไทม์)
แพลตฟอร์ม 5G‑Edge Generative Hub ถูกออกแบบมาเพื่อลด end-to-end latency ของงานประมวลผลภาพและเสียงเชิงเรียลไทม์ให้เหลือต่ำกว่า 50ms โดยให้บริการโมเดลที่มีความเฉพาะด้านและผ่านการปรับแต่งสำหรับรันบน GPU ใกล้ผู้ใช้ โมเดลที่เหมาะสมบน Edge ประกอบด้วยทั้งชุดโมเดลเสียง (ASR, TTS, voice conversion), โมเดลวิดีโอเรียลไทม์/portrait synthesis ที่ปรับให้ inference‑optimized (เช่น NeRF/instant neural rendering และ latent diffusion แบบเบา) รวมถึงโมเดลมัลติโมดอลสำหรับซิงก์ภาพ‑เสียงและ LLM ขนาดเล็กสำหรับ interactive assistants

ตัวอย่างโมเดลและตระกูลที่ Hub สามารถให้บริการได้อย่างมีประสิทธิภาพบน edge GPU:
- Real‑time ASR — โมเดลขนาดเล็ก/กลางที่ปรับแต่งเช่น Conformer‑lite, wav2vec2‑base หรือ Whisper‑tiny/base สำหรับการถอดเสียงแบบสตรีมมิง
- Low‑latency TTS — FastSpeech2 / VITS ร่วมกับ vocoder แบบ HiFi‑GAN หรือ ParallelWaveGAN ที่สามารถสร้างเสียงจริงได้ภายในไม่กี่สิบมิลลิวินาที
- Voice conversion / voice2voice — โซลูชันเช่น RVC (Retrieval‑based Voice Conversion) หรือ AutoVC ที่ฝึกให้ปรับโทนเสียงแบบเรียลไทม์สำหรับการเปลี่ยนเสียงผู้พูด
- Real‑time video / portrait synthesis — Neural rendering แบบ Instant‑NGP, MobileNeRF, KiloNeRF และ latent diffusion ที่ถูกย่อขนาด/ปรับให้ใช้ latent space เพื่อการสร้างเฟรมอย่างรวดเร็ว
- Multimodal sync models — Wav2Lip, audio‑driven talking‑head และโมเดลซิงก์ปาก‑การแสดงออกสำหรับ avatar ที่ต้องการความสอดคล้องของเสียงกับใบหน้าแบบเรียลไทม์
- Lightweight LLMs สำหรับ interactive assistants — โมเดลขนาดเล็ก (เช่น 1–3B parameters) ที่ผ่านการ quantize และ distill เพื่อใช้เป็นตัวจัดการดialogue และ logic สำหรับ voice/visual assistant แบบตอบโต้ทันที
เพื่อให้โมเดลเหล่านี้ทำงานได้ตามข้อกำหนดด้านเวลาแฝงและต้นทุน บริการ Hub ใช้ชุดเทคนิคการปรับแต่งที่พิสูจน์แล้วว่าสามารถเพิ่มประสิทธิภาพการ inference บน edge GPU:
- Quantization — ลดความแม่นยำตัวเลขเป็น INT8 หรือ 4‑bit (GPTQ, QLoRA‑style flows) เพื่อลดหน่วยความจำและเพิ่มความเร็วโดยยังรักษาคุณภาพเสียง/ภาพในระดับธุรกิจ
- Pruning และ structured sparsity — ตัดพารามิเตอร์ที่มีผลน้อยออก (structured pruning) เพื่อลด FLOPs และเปิดโอกาสให้โมเดลรันได้บน GPU หน่วยความจำจำกัด
- Knowledge distillation — สร้าง student model ขนาดเล็กจาก teacher model ขนาดใหญ่ เพื่อคงคุณภาพของผลลัพธ์แต่ลด latency
- Mixed precision และ TensorRT/ONNX optimizations — ใช้ FP16/AMP และการคอมไพล์เป็น TensorRT/ONNX เพื่อให้ได้ kernel ที่เร็วขึ้นและ latency ต่ำกว่า
- Batching strategies & micro‑batching — ใช้ micro‑batching/dynamic batching และ sequence bucketing เพื่อเพิ่ม throughput โดยยังคงควบคุม latency สำหรับงาน interactive
- Pipelining และ pre‑warming — แยก pipeline ของโมดูล (ASR → NLU → TTS/voice‑conversion → rendering) และพรีวอร์มโมเดลสำหรับเหตุการณ์ที่คาดการณ์ได้ เช่น สดคอนเสิร์ต เพื่อหลีกเลี่ยง overhead ของ cold start
- Memory and I/O optimizations — Zero‑copy buffers, memory‑mapped weights และ model sharding ช่วยให้จัดการหน่วยความจำบน edge GPU ได้มีประสิทธิภาพ
กรณีใช้งานจริงที่ได้รับประโยชน์อย่างชัดเจนจากข้อเสนอของ Hub ได้แก่:
- ถ่ายทอดสดคอนเสิร์ตพร้อม visual effects แบบเรียลไทม์ — สตาร์ทอัพสื่อสามารถรันโมดูลวิดีโอสังเคราะห์ (portrait synthesis + diffusion แบบเบา) พร้อมเสียงสังเคราะห์/voice conversion เพื่อสร้างเอฟเฟ็กต์ภาพและเปลี่ยนโทนเสียงของนักแสดงแบบออน‑เด‑โฟลว โดย latency ต่ำกว่า 50ms ทำให้เอฟเฟ็กต์สอดคล้องกับการแสดงจริง
- Interactive broadcast และ Q&A แบบโต้ตอบ — โฮสต์สามารถใช้ ASR พร้อม LLM จํานวนเล็กเพื่อทำความเข้าใจคำถามและตอบกลับด้วย TTS แบบ low‑latency หรือแม้แต่เป็น avatar เสียงจริงที่ซิงก์ปากได้เรียลไทม์
- AR/VR event ที่ต้องการ synchronous audio‑visual feedback — ผู้เล่น/ผู้ชมเห็น avatar หรือวัตถุเสมือนตอบสนองต่อเสียงหรือคำสั่งของผู้ใช้แบบทันท่วงที ตัวอย่างเช่น ฟิลเตอร์ AR ในคอนเสิร์ตที่เปลี่ยนตามคีย์เวิร์ดในเสียงผู้ชม
- หลายภาษาและการแปลเสียงในตัว — ระบบแปลแบบเรียลไทม์ (ASR → NMT → TTS) สำหรับการออกอากาศสากล Hub ที่วาง GPU ใกล้ผู้ชมช่วยลดความหน่วงของ pipeline ทั้งหมด ให้การแปลและซิงก์เสียงเป็นธรรมชาติในระดับที่ยอมรับได้ในการส่งสัญญาณสด
สรุปแล้ว 5G‑Edge Generative Hub จะเป็นโครงสร้างพื้นฐานที่เอื้อต่อการรันโมเดลภาพ‑เสียงแบบเรียลไทม์ได้ทั้งในเชิงเทคนิคและเชิงพาณิชย์ โดยการผสมผสานโมเดลที่ปรับแต่งมาเฉพาะ (ASR, TTS, voice conversion, lightweight diffusion/NeRF) กับเทคนิคการเพิ่มประสิทธิภาพเช่น quantization, pruning, distillation และ batching ทำให้สตาร์ทอัพและผู้ประกอบการสื่อสามารถเปิดนวัตกรรมการถ่ายทอดสดที่มีความโต้ตอบสูง ได้โดยยังคงระดับ latency ต่ำและต้นทุนที่เป็นมิตรกับรูปแบบคิดราคาเป็นนาทีของบริการ
5. โมเดลการคิดราคาเป็นนาทีและผลต่อสตาร์ทอัพ
5. โมเดลการคิดราคาเป็นนาทีและผลต่อสตาร์ทอัพ
การคิดราคาเป็นนาที (per‑minute billing) เป็นรูปแบบสแตนด์บายที่ออกแบบมาเพื่อตอบโจทย์งานสั้น ๆ และอีเวนต์สดที่มีความต้องการทรัพยากรชั่วคราวสูง สำหรับสตาร์ทอัพด้านการสื่อสารสด การคิดเป็นนาทีช่วยลดค่าใช้จ่ายเมื่อเทียบกับการเช่าแบบชั่วโมงหรือการจองเครื่องตลอดช่วงเวลา ซึ่งมีผลโดยตรงต่อการวางแผนงบประมาณและความคล่องตัว ตัวอย่างเช่น งานสตรีมสดความยาว 30–120 นาที มักต้องการ GPU ประมวลผลภาพและเสียงแบบเรียลไทม์ การคิดเป็นนาทีทำให้ผู้ประกอบการจ่ายเฉพาะเวลาที่ใช้จริง ลดการเสียเงินกับเวลาว่าง และสนับสนุนการทดลองฟีเจอร์ใหม่ ๆ ด้วยต้นทุนต่ำกว่า
โครงสร้างราคาแบบตัวอย่าง (illustrative pricing tiers)
เพื่อให้เห็นภาพชัดเจน สมมติรูปแบบราคาต่อไปนี้เป็นตัวอย่างประกอบการอธิบาย (สกุลเงิน: บาทไทย, ตัวเลขเพื่อการอธิบายเท่านั้น):
- Base minute rate: คิดขั้นต่ำ 0.50 บาท/นาที สำหรับอินสแตนซ์ขนาดเล็ก (lightweight inference)
- GPU class - Inference (edge‑optimized): 1.50 บาท/นาที — เหมาะสำหรับโมเดลเรียลไทม์ขนาดกลาง เช่น super‑resolution, voice enhancement
- GPU class - High‑performance inference: 5.00 บาท/นาที — สำหรับโมเดลภาพหรือเสียงความละเอียดสูงและหลายสตรีมพร้อมกัน
- GPU class - Training / Large models: 12.00 บาท/นาที — สำหรับ fine‑tuning หรือรันโมเดลขนาดใหญ่แบบ near‑real‑time
- Burst pricing (ช่วงพีค): คิดเพิ่ม +50% ของราคาปกติในช่วงความต้องการสูงสุด (เช่น อีเวนต์ระดับประเทศ หรือ peak hours)
- Network egress: 4.00 บาท/GB (สำหรับเขตภายในประเทศอาจมีราคาถูกกว่าสำหรับ CDN ภายในเครือข่าย)
- Storage: Object storage 2.00 บาท/GB‑เดือน (คำนวณเป็นส่วนนาทีสำหรับไฟล์ชั่วคราวได้) และ SSD ephemeral สำหรับงานชั่วคราวคิดเพิ่มตามขนาดและเวลา
เปรียบเทียบกับการเช่าอินสแตนซ์บน public cloud แบบชั่วโมงหรือ spot instances
การเช่าแบบชั่วโมงมักบังคับให้ต้องจ่ายเป็นรอบเต็ม (เช่น 1 ชั่วโมงขึ้นไป) ซึ่งสำหรับอีเวนต์ความยาว 20–45 นาที จะทำให้เกิดการจ่ายเกินความจำเป็น ตัวอย่างสมมติ: หาก public cloud คิดค่าสำหรับ GPU inference ที่ 10 บาท/นาที (600 บาท/ชั่วโมง) การรันงาน 30 นาทีจะหมดค่าใช้จ่าย 300 บาท ในขณะที่โมเดลคิดเป็นนาทีบน 5G‑Edge ที่ 1.50 บาท/นาที จะใช้เพียง 45 บาท ในทางกลับกัน spot instances อาจเสนอราคาถูกแต่มีความเสี่ยงถูกยกเลิกกลางงาน (preemption) ซึ่งไม่เหมาะกับการสตรีมสดที่ต้องการ SLA สูง
SLA และเงื่อนไขที่เกี่ยวข้อง
ผู้ให้บริการมักเสนอ SLA ที่ครอบคลุมในรูปแบบต่อไปนี้:
- ความพร้อมใช้งาน (availability) เช่น 99.9% สำหรับบริการ edge GPU ในภูมิภาค — หากต่ำกว่า จะมีเครดิตคืนเงินเป็นเปอร์เซ็นต์ของค่าใช้จ่าย
- Latency SLA — รับประกัน latency ภายใน <50ms ภายในพื้นที่ให้บริการ (region) และชดเชยหากเกินเกณฑ์ตามเงื่อนไข
- Billing granularity — การคิดคิดเป็นนาทีจริง (granularity 1 นาที) พร้อม rounding policy ชัดเจน (เช่น ปัดขึ้นเป็น 1 นาทีแรก)
- Burst capacity & throttling — ช่วงพีคอาจมีการคิดราคาพิเศษและมีการจำกัด “burst quota” หากใช้เกินจะต้องตกลงการสำรองทรัพยากรล่วงหน้า
ตัวอย่างสมมติการคำนวณค่าใช้จ่ายสำหรับอีเวนต์สตรีมสด 90 นาที
- ใช้ GPU inference (edge‑optimized) ที่ 1.50 บาท/นาที => 1.50 x 90 = 135 บาท
- Network egress สมมติ 10 GB => 10 x 4.00 = 40 บาท
- Storage ชั่วคราว (pro‑rated) สมมติ 5 GB => 5 x (2.00/30/24/60 x 90) ≈ น้อยกว่าสิบสตางค์ (มักไม่สำคัญในงานชั่วคราว)
- รวมโดยประมาณ = 175 บาท (เทียบกับการเช่าแบบชั่วโมงบน public cloud ที่อาจอยู่ที่ 600–900 บาทสำหรับ 1.5 ชั่วโมง)
คำแนะนำด้านการบริหารต้นทุนสำหรับสตาร์ทอัพ
เพื่อเพิ่มประสิทธิภาพต้นทุน ควรพิจารณาแนวปฏิบัติดังนี้:
- Prewarm pools — จองหรือ prewarm กลุ่มอินสแตนซ์ในช่วงก่อนเริ่มเหตุการณ์ (warm‑standby) เพื่อลด cold start latency และสามารถแปลงเวลาพรีวอร์มเป็น minute‑billing ที่คุ้มค่าเมื่อเทียบกับการเสียประสบการณ์ผู้ใช้
- Autoscaling rules ที่แม่นยำ — ตั้งเกณฑ์ scaling บนตัวชี้วัดเช่น concurrent streams, GPU utilization, queue length และใช้ cooldown period ที่เหมาะสม เพื่อลดการสับเปลี่ยนทรัพยากรบ่อยครั้ง
- Burst management — กำหนดขีดจำกัดการใช้ burst และมีแผน fallback (เช่น ลดความละเอียดวิดีโอแบบอัตโนมัติ) เมื่อโดนบังคับพีคหรือถูกคิดราคาช่วง peak
- Hybrid strategy — ผสมผสานการจองแบบ committed minutes สำหรับงานที่คาดการณ์ได้ (เช่นรายการประจำเดือน) กับ minute‑on‑demand สำหรับอีเวนต์ฉุกเฉิน
- Monitoring และ forecasting — ใช้เครื่องมือวิเคราะห์เพื่อประเมิน minutes_used, egress_GB และ cost_per_event เพื่อสร้างงบประมาณล่วงหน้าและ alert เมื่อแนวโน้มค่าใช้จ่ายเกินกว่าที่คาดการณ์
6. ความปลอดภัย ความเป็นส่วนตัว และการปฏิบัติตามกฎระเบียบ
6. ความปลอดภัย ความเป็นส่วนตัว และการปฏิบัติตามกฎระเบียบ
การนำระบบ 5G‑Edge Generative Hub ไปใช้เพื่อรันโมเดลภาพและเสียงใกล้ผู้ใช้แม้จะให้ประสิทธิภาพด้าน Latency ต่ำกว่า <50ms แต่ก็เพิ่มความซับซ้อนด้านความปลอดภัยและการคุ้มครองข้อมูลส่วนบุคคล ผู้ให้บริการต้องออกแบบสถาปัตยกรรมและนโยบายด้านความปลอดภัยให้ครอบคลุมตั้งแต่ระดับฮาร์ดแวร์จนถึงกระบวนการปฏิบัติการ เพื่อป้องกันความเสี่ยงที่เกิดจากการกระจายทรัพยากรที่ edge และการให้บริการแบบ multi‑tenant
ประเด็นหลักที่ต้องให้ความสำคัญ ได้แก่ data residency (การกำหนดที่ตั้งของข้อมูล), การเข้ารหัสทั้งในระหว่างการส่งข้อมูลและเมื่อจัดเก็บ (encryption in transit & at rest) และการแยกการใช้งานระหว่างผู้เช่า (tenant isolation) เพื่อป้องกันการเข้าถึงข้ามผู้เช่าและการรั่วไหลของข้อมูลเชิงความลับหรือทรัพย์สินทางปัญญา ตัวอย่างมาตรการที่ควรจัดเตรียมมีดังนี้:
- Data residency และการส่งข้ามพรมแดน: ให้ลูกค้าเลือกพื้นที่จัดเก็บ (region/local zone) เพื่อเก็บข้อมูลส่วนบุคคลภายในประเทศไทยสำหรับงานที่ต้องปฏิบัติตาม PDPA โดยตรง หากต้องส่งข้ามพรมแดน ควรมีพื้นฐานทางกฎหมาย (เช่น ความยินยอมที่ชัดเจน ข้อตกลงสัญญาที่มีมาตรการคุ้มครอง หรือมาตรการทางเทคนิคและองค์กรที่เทียบเท่าความคุ้มครอง) และจัดทำ Data Transfer Agreement หรือมาตรการทดแทนที่ยอมรับได้
- Encryption in transit & at rest: บังคับใช้การเข้ารหัสระดับอุตสาหกรรม เช่น TLS 1.3 สำหรับการสื่อสารระหว่างอุปกรณ์-Edge-Cloud และ AES‑256 หรือเทียบเท่าสำหรับข้อมูลที่จัดเก็บ พร้อมใช้ HSM/KMS ในการจัดการคีย์ การหมุนเวียนคีย์ (key rotation) และการแยกหน้าที่ของผู้บริหารคีย์
- Tenant isolation (multi‑tenancy): ใช้การแยกทรัพยากรแบบหลายชั้น เช่น hardware partitioning (SR‑IOV, dedicated NICs), VM/Container isolation พร้อมกับ vTPM และ enforced cgroups, network microsegmentation และนโยบาย Zero Trust เพื่อลดความเสี่ยงการเคาะข้ามคอนเทนเนอร์หรือการโจมตีผ่านช่องว่างของระบบปฏิบัติการ
มาตรการเชิงเทคนิคที่แนะนำ ควรรวมถึงฮาร์ดแวร์และซอฟต์แวร์ร่วมกันเพื่อสร้างความมั่นใจสูงสุด เช่น TPM และ secure boot เพื่อยืนยันความสมบูรณ์ของแพลตฟอร์ม, การใช้เทคโนโลยี enclave (เช่น Intel SGX, AMD SEV หรือ ARM TrustZone) สำหรับการประมวลผลข้อมูลหรือโมเดลที่มีความอ่อนไหว, การป้องกันช่องโหว่เชิง side‑channel และการรองรับ measured boot เพื่อการตรวจสอบสถานะระบบแบบ cryptographic นอกจากนี้เครือข่ายควรสนับสนุนการเชื่อมต่อแบบส่วนตัว (VPN/MPLS, dedicated circuits หรือ private peering) และเทคนิค SD‑WAN ที่จัดเส้นทางทราฟฟิกที่เป็นความลับแยกจากทราฟฟิกสาธารณะ
การคุ้มครองโมเดลและทรัพย์สินทางปัญญา เป็นอีกหัวข้อที่ผู้ให้บริการต้องให้ความสำคัญ ทั้งการป้องกันการคัดลอกโมเดล (weight theft), การห้ามนำโมเดลออกจากสภาพแวดล้อมที่กำหนด และการติดตามการใช้งานเชิงผลลัพธ์ ตัวอย่างแนวทางปฏิบัติได้แก่ การเข้ารหัสน้ำหนักโมเดลในช่วงจัดเก็บและเรียกใช้ (encrypted model weights), การให้บริการโมเดลผ่าน API เท่านั้นเพื่อจำกัดการเข้าถึงระดับไบนารี, การใช้ digital watermarking หรือ fingerprinting ของผลลัพธ์เพื่อตรวจจับการใช้ที่ไม่ได้รับอนุญาต และการบังคับนโยบายลิขสิทธิ์และ license enforcement ใน contract ระหว่างผู้ให้บริการกับลูกค้า
การปฏิบัติตาม PDPA และข้อกำหนดการกำกับดูแล ผู้ให้บริการต้องออกแบบฟังก์ชันสนับสนุนการปฏิบัติตามกฎหมายไทย เช่น การจัดการความยินยอม การปฏิบัติตามหลัก purpose limitation และ data minimization และมีมาตรการรองรับการส่งข้ามพรมแดนตาม PDPA ได้แก่ การจัดทำสัญญาหรือข้อตกลงที่รับประกันระดับการคุ้มครอง การขอความยินยอมจากเจ้าของข้อมูล และการทำ Data Protection Impact Assessment (DPIA) เมื่อมีความเสี่ยงสูงจากการประมวลผลข้อมูลส่วนบุคคล
กระบวนการบริหารจัดการความเสี่ยงและการรับประกันการปฏิบัติการ ควรรวมถึง:
- Audit logs ที่ครอบคลุมทั้งการเข้าถึงข้อมูล การเรียกใช้โมเดล การเปลี่ยนแปลงคอนฟิก และการยกระดับสิทธิ์ — เก็บรักษาอย่างน้อย 90–365 วันขึ้นอยู่กับข้อตกลงและข้อกำหนดการควบคุม
- Access controls แบบละเอียด (RBAC/ABAC) ร่วมกับ MFA และ least privilege เพื่อป้องกันการเข้าถึงโดยไม่ได้รับอนุญาต
- มาตรฐานความปลอดภัยและการรับรอง เช่น ISO 27001, SOC 2 เพื่อเป็นหลักฐานเชิงประจักษ์ของกระบวนการควบคุมความเสี่ยง
- SLA ทางกฎหมายที่ชัดเจนสำหรับการแจ้งเหตุข้อมูลรั่วไหล การตอบสนองต่อเหตุการณ์ (ตัวอย่าง: ระยะเวลา initial response ภายใน 2 ชั่วโมง และรายงานเหตุการณ์เต็มรูปแบบภายในกรอบเวลาเสมือน 72 ชั่วโมงตามแนวปฏิบัติสากล) รวมทั้งการกำหนดข้อผูกมัดเรื่อง availability (เช่น 99.9%) latency (<50ms สำหรับเส้นทางที่กำหนด) และการรับประกันการลบข้อมูลเมื่อหมดอายุ
สรุปแล้ว การเปิดให้เช่า GPU ที่ Edge จำเป็นต้องมาพร้อมกับชุดมาตรการความปลอดภัยเชิงลึก (defense‑in‑depth), นโยบายปฏิบัติตามกฎหมายที่ชัดเจน และการออกแบบสัญญาทางกฎหมายที่ปกป้องทั้งข้อมูลส่วนบุคคลและทรัพย์สินทางปัญญาของลูกค้า ผู้ให้บริการที่สามารถนำเสนอการควบรวมมาตรการฮาร์ดแวร์เช่น TPM/secure boot/enclave กับการจัดการคีย์ระดับองค์กรและการตรวจสอบเชิงปฏิบัติการ จะสามารถสร้างความเชื่อมั่นให้ตลาดสตาร์ทอัพและองค์กรที่ต้องการประมวลผลภาพ‑เสียงเรียลไทม์ได้อย่างยั่งยืน
7. ภาพรวมตลาด คู่แข่ง และแนวโน้มในอนาคต
7. ภาพรวมตลาด คู่แข่ง และแนวโน้มในอนาคต
การเปิดตัวบริการ 5G‑Edge Generative Hub โดยผู้ให้บริการโทรคมนาคมไทยเป็นสัญญาณว่าตลาด Edge AI กำลังก้าวเข้าสู่เฟสการแข่งขันเชิงพาณิชย์อย่างจริงจัง สำหรับภาพรวมด้านตลาดนั้น รายงานหลายแห่งคาดการณ์ว่า ตลาด Edge Computing จะเติบโตด้วยอัตราเฉลี่ยต่อปี (CAGR) ประมาณ 15–20% ภายในทศวรรษหน้า ขณะที่ความต้องการสำหรับการประมวลผลแบบเรียลไทม์ในสื่อและสตรีมมิ่ง (เช่น การประมวลผลภาพ เสียง และเอฟเฟกต์แบบอินเทอร์แอคทีฟ) เพิ่มขึ้นอย่างมีนัยสำคัญ การที่ Latency ถูกลดลงเหลือ <50ms> จะเป็นปัจจัยเร่งให้เกิดการนำเทคโนโลยีนี้ไปใช้ในรูปแบบใหม่ ๆ เช่น live AR overlays, real‑time translation และการโต้ตอบแบบสองทางในรายการสตรีมมิงสด
เมื่อนำผู้ให้บริการโทรคมนาคม (telco edge) มาเปรียบเทียบกับผู้ให้บริการคลาวด์สาธารณะ (public cloud) จะเห็นข้อได้เปรียบและข้อจำกัดที่ชัดเจน:
- จุดแข็งของ Telco Edge: ความใกล้ชิดกับผู้ใช้ (proximity) ทำให้ได้ latency ต่ำและความเสถียรสูง, การบูรณาการกับเครือข่าย 5G/Private 5G ช่วยให้จัดการ QoS และ location‑aware services ได้, รองรับข้อกำหนดด้านการเก็บข้อมูลในประเทศ (data residency) และสามารถให้ SLA แบบใกล้ชิดกับลูกค้าองค์กรได้
- จุดอ่อนของ Telco Edge: ความจุรวมยังจำกัดเมื่อเทียบกับ hyperscalers, ต้นทุนต่อหน่วยอาจสูงกว่าในบางงาน, และระบบนิเวศของ developer tooling กับ marketplace ยังไม่ครบเท่าผู้ให้บริการคลาวด์ขนาดใหญ่
- จุดแข็งของ Public Cloud: ขนาดและความยืดหยุ่นในการจัดสรรทรัพยากรสูง, มีสแตก AI/ML และบริการเสริมครบ (model hosting, MLOps, dataset services), และ ecosystem ของนักพัฒนาและ third‑party integrations เข้มแข็ง
- จุดอ่อนของ Public Cloud: ระยะทางส่งผลให้ latency สูงกว่าเมื่อผู้ใช้ปลายทางต้องการการตอบสนองทันที, ค่า egress และค่าแบนด์วิดท์อาจเป็นภาระเมื่อสตรีมวิดีโอความละเอียดสูง, และมีข้อจำกัดด้านการควบคุมเครือข่ายเชิงลึกเทียบกับการจัดการโดย telco
ในเชิงโมเดลธุรกิจ ปรากฏการณ์ที่น่าสังเกตคือการผลักดันสู่ pay‑per‑minute หรือ micro‑billing สำหรับงานเรียลไทม์ แนวทางนี้สอดคล้องกับลักษณะงานของสื่อสตรีมมิ่งและสตาร์ทอัพที่ต้องการ GPU แบบเป็นช่วง (bursty workloads) มากกว่าการจองเครื่องต่อชั่วโมงหรือเช่าแบบถาวร การคิดค่าบริการเป็นนาทีช่วยลดค่าใช้จ่ายคงที่และเปิดโอกาสให้ผู้ประกอบการขนาดเล็กทดลองฟีเจอร์เรียลไทม์ได้ง่ายขึ้น ตัวอย่างรูปแบบที่ใกล้เคียงคือการคิดค่าบริการแบบมิลลิวินาทีของ serverless (เช่น Lambda) แต่การนำมาประยุกต์กับ GPU และ Edge ต้องคำนึงถึง overhead ในการสตาร์ทโมเดล การจัดการอุ่นเครื่อง (warm‑start) และการประกันคุณภาพการให้บริการ
มีแนวโน้มเชิงเทคนิคและเชิงนโยบายที่ควรจับตามองดังนี้:
- ความร่วมมือกับผู้ให้บริการคลาวด์ (Cooperation with cloud providers): การจับมือระหว่าง telco กับ hyperscalers เช่นกรณีโซลูชัน Edge ของ AWS, Azure หรือ Google (ที่มีรูปแบบ partnership กับผู้ให้บริการเครือข่ายในหลายประเทศ) จะช่วยเติมเต็มช่องว่างด้านสเกลและเครื่องมือ MLOps ทำให้ลูกค้าสามารถโยกโหลดระหว่าง edge และ public cloud ได้อย่างราบรื่น
- มาตรฐานและ interoperability: การยอมรับมาตรฐานเช่น ETSI MEC, มาตรฐาน 3GPP สำหรับการผสาน 5G กับ edge, และแนวทาง cloud‑native (Kubernetes/CNCF) จะเป็นกุญแจสำคัญในการลด fragmentation และสนับสนุนการเคลื่อนย้ายแอปพลิเคชันระหว่างผู้ให้บริการหลายราย
- Developer tooling และ ecosystem: เครื่องมือสำหรับการปรับใช้โมเดลข้าม edge/cloud (เช่น ออร์เคสเตรชัน Hybrid/Multi‑Cloud, edge‑optimized runtimes, remote debugging, observability และ cost‑profiling) ต้องพัฒนาอย่างรวดเร็ว หาก telco สามารถนำเสนอ SDK, CI/CD integration และ catalog ของโมเดล/แพ็กเกจที่พร้อมใช้ จะช่วยเพิ่มการรับรู้และการนำไปใช้ของนักพัฒนา
สรุปคือ การที่ผู้ให้บริการโทรคมนาคมไทยเข้าสู่สนามด้วยบริการให้เช่า GPU ใกล้ผู้ใช้และโมเดลคิดราคาเป็นนาที เป็นการต่อยอดจุดแข็งด้านเครือข่ายและ latency ที่จะเปลี่ยนรูปแบบการให้บริการสื่อสดและสตรีมมิ่งได้จริง อย่างไรก็ตาม ความสำเร็จเชิงพาณิชย์จะขึ้นกับการผนึกกำลังกับผู้ให้บริการคลาวด์ในด้านสเกลและเครื่องมือ, การยอมรับมาตรฐานเพื่อความเข้ากันได้ของระบบ และการพัฒนา tooling ที่รองรับนักพัฒนาและสตาร์ทอัพให้สามารถใช้ประโยชน์จาก Edge AI ได้อย่างคุ้มค่าและมีประสิทธิภาพ
บทสรุป
บริการ 5G‑Edge Generative Hub ของผู้ให้บริการโทรคมนาคมไทยนำเสนอโมเดลธุรกิจใหม่โดยให้เช่า GPU ใกล้ผู้ใช้ (edge) เพื่อรันโมเดลภาพและเสียงแบบเรียลไทม์ ลดข้อจำกัดด้าน latency จากโครงสร้างแบบคลาวด์ส่วนกลางลงเหลือ <50ms ซึ่งเหมาะกับแอปพลิเคชันอย่างการสตรีมสดที่มีเอฟเฟกต์เรียลไทม์, การประมวลผลภาพ AR/VR ฝั่งผู้ใช้, การแปลงเสียงเป็นข้อความและการสร้างเสียงตอบโต้ทันที ตัวเลือกคิดราคาเป็นนาทีช่วยลดค่าใช้จ่ายเริ่มต้นและเพิ่มความยืดหยุ่นให้สตาร์ทอัพสื่อสารสดทดลองนวัตกรรมด้วยต้นทุนที่โปร่งใสและปรับตามการใช้งานจริง ตัวอย่างการใช้งานได้แก่ การผลิตรายการสดแบบเสมือน (virtual production), ระบบช่วยผู้ประกาศข่าวด้วยสคริปต์แบบเรียลไทม์ และบริการแปล/ซับไตเติลสดสำหรับผู้ชมหลายภาษา
ความสำเร็จเชิงพาณิชย์ของ Hub จะขึ้นกับปัจจัยสำคัญ 3 ด้าน: (1) มาตรฐานการวัดประสิทธิภาพจริง—การรายงาน latency และ jitter แบบเจาะจงตามเส้นทางเครือข่าย, ค่าเฉลี่ยและเปอร์เซ็นไทล์ (เช่น p50/p95/p99) เพื่อให้ผู้ใช้ประเมินประสบการณ์จริงได้ (2) ความโปร่งใสของโมเดลการคิดราคา—การแสดงอัตราต่อนาที, ค่าบริการเพิ่มเติม เช่น bandwidth/ingress‑egress และการประกันค่าใช้จ่ายสูงสุด เพื่อให้สตาร์ทอัพวางแผนต้นทุนได้แม่นยำ และ (3) การจัดการด้านความปลอดภัยและการปฏิบัติตามกฎระเบียบ—รวมถึงการเข้ารหัสระหว่างทาง/ที่พักข้อมูล, การกำหนดนโยบาย data residency ตาม PDPA, การตรวจสอบโมเดล (model governance) และการป้องกันการรั่วไหลของข้อมูล หากผู้ให้บริการสามารถตั้ง SLA ชัดเจน, ใช้มาตรฐานทดสอบสาธารณะ และให้เครื่องมือตรวจวัดแบบเรียลไทม์ โซลูชันนี้มีศักยภาพเป็นตัวเร่งนวัตกรรมสื่อสดในประเทศ แต่ต้องเดินควบคู่ไปกับมาตรฐานการวัดและกรอบกำกับดูแลที่เข้มแข็งเพื่อสร้างความเชื่อมั่นและการยอมรับในวงกว้าง



