
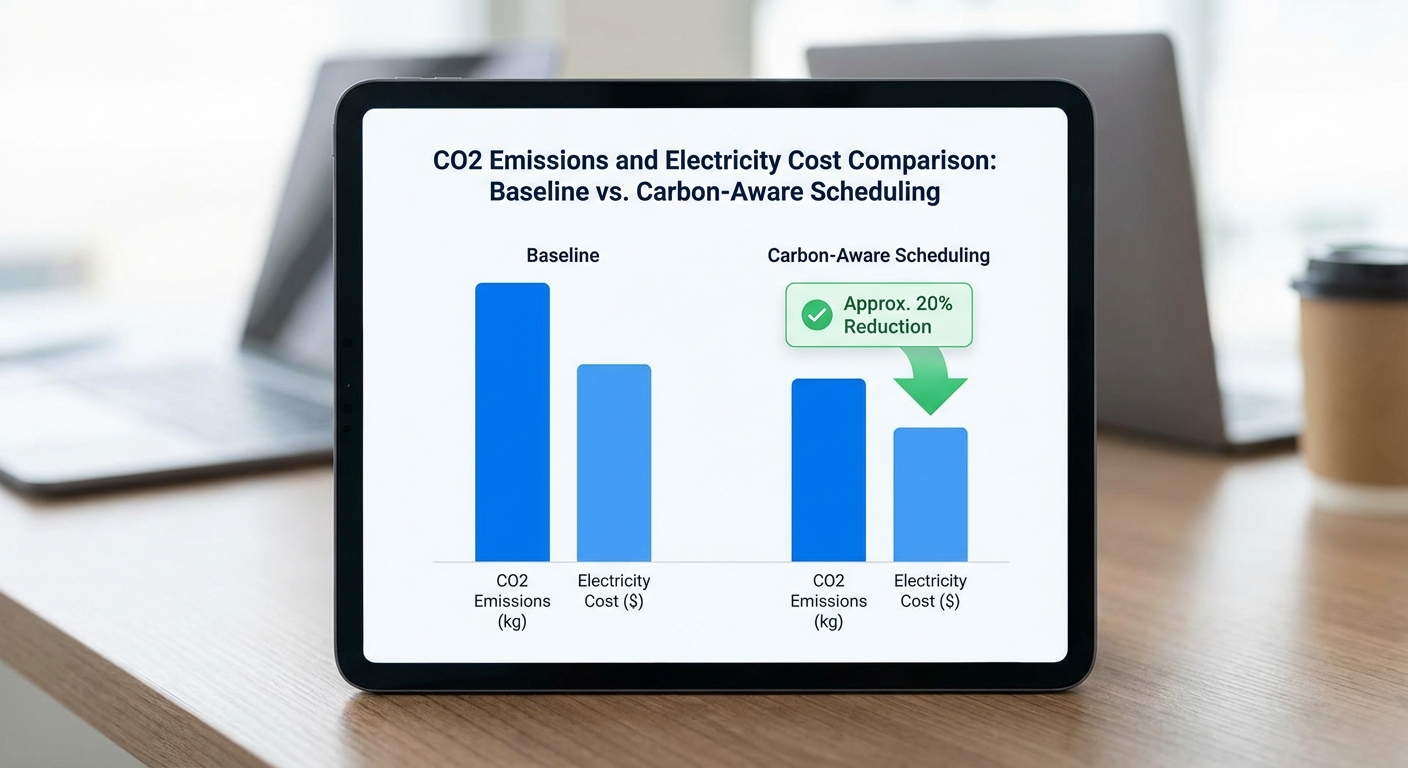
เมื่อการฝึกสอนโมเดลปัญญาประดิษฐ์กลายเป็นหนึ่งในกิจกรรมที่ใช้พลังงานสูง ผู้ให้บริการคลาวด์รายใหญ่ในไทยได้เปิดตัว Carbon‑Aware AI Scheduler เครื่องมือจัดคิวงานการฝึกโมเดลที่ปรับเวลาให้สอดคล้องกับการคาดการณ์สัดส่วนพลังงานหมุนเวียนในกริดไฟฟ้า โดยจากการทดสอบภายในระบุว่าสามารถลดทั้งการปล่อยก๊าซคาร์บอนไดออกไซด์และค่าไฟฟ้าได้สูงสุดถึง 20% — ข้อเสนอที่ผสานประสิทธิภาพทางเทคนิคกับความรับผิดชอบต่อสิ่งแวดล้อมอย่างชัดเจน

บทนำนี้จะชี้ภาพรวมว่าระบบดังกล่าวทำงานอย่างไร ตั้งแต่การคาดการณ์พลังงานหมุนเวียน การจัดคิวและเลื่อนเวลางานฝึก ไปจนถึงผลการทดสอบจริงและตัวอย่างการใช้งานในสภาพแวดล้อมธุรกิจไทย พร้อมวิเคราะห์ข้อดี เช่น ลดต้นทุนและช่วยบรรลุเป้าหมายความยั่งยืน ข้อจำกัดด้านความแม่นยำของการพยากรณ์และเงื่อนไขบริการ (SLA) รวมถึงผลกระทบเชิงกลยุทธ์ที่ธุรกิจไทยอาจได้รับเมื่อนำแนวทาง "carbon‑aware" มาใช้จริง
สรุปข่าว: อะไรใหม่และทำไมสำคัญ
สรุปข่าว: อะไรใหม่และทำไมสำคัญ
ผู้ให้บริการคลาวด์ไทยประกาศเปิดตัวฟีเจอร์ใหม่ในแพลตฟอร์มคลาวด์ของตนภายใต้ชื่อ Carbon‑Aware AI Scheduler ซึ่งเป็นระบบจัดตารางงานฝึกโมเดลที่ออกแบบมาเพื่อคำนึงถึงความเข้มของคาร์บอนในระบบไฟฟ้าและสัดส่วนพลังงานหมุนเวียนในแต่ละช่วงเวลา ฟีเจอร์นี้ช่วยให้การรันงานฝึก (training jobs) ที่เลื่อนเวลาได้สามารถถูกจัดตารางไปยังช่วงเวลาที่มีสัดส่วนพลังงานหมุนเวียนสูงหรือความเข้มคาร์บอนต่ำกว่า ส่งผลให้การปล่อยก๊าซคาร์บอนโดยรวมของงาน AI ลดลงโดยไม่กระทบต่อคุณภาพโมเดลหรือกระบวนการพัฒนาในระยะยาว
ตามการทดสอบภายในที่ผู้ให้บริการรายงาน ฟีเจอร์ดังกล่าวสามารถลดการปล่อยคาร์บอนและค่าไฟฟ้าสำหรับงานฝึกได้สูงสุดประมาณ 20% การทดสอบครอบคลุมงานฝึกแบบ batch, การค้นหาพารามิเตอร์ (hyperparameter sweeps) และงานประมวลผลข้อมูลที่สามารถเลื่อนได้ ผู้ให้บริการระบุว่าการลดนี้มาจากการเลื่อนเวลาไปยังช่วงที่กริดไฟฟ้ามีพลังงานหมุนเวียนมากและ/หรือมีอัตราค่าไฟฟ้าต่ำกว่า รวมถึงการจัดสรรทรัพยากรให้สอดคล้องกับสัญญาณความเข้มคาร์บอนแบบเรียลไทม์
ในเชิงธุรกิจ ฟีเจอร์นี้มีเป้าหมายทั้งด้านต้นทุนและความยั่งยืน: ลดค่าใช้จ่ายพลังงานสำหรับงานฝึกที่กินพลังงานสูง ลดคาร์บอนในการดำเนินงานเพื่อสนับสนุนเป้าหมาย ESG และช่วยให้องค์กรสามารถรายงานตัวชี้วัดการปล่อยคาร์บอนของไอทีได้แม่นยำขึ้น นอกจากนี้ยังเป็นจุดขายเชิงการแข่งขันสำหรับผู้ให้บริการคลาวด์ที่ต้องการตอบโจทย์ลูกค้าองค์กรที่กำลังมองหาโซลูชันที่ช่วยลดผลกระทบด้านสิ่งแวดล้อมโดยไม่ต้องลดประสิทธิภาพการพัฒนา AI
กลุ่มเป้าหมายหลักของฟีเจอร์นี้ได้แก่:
- ทีม Machine Learning (ML) ที่รันงานฝึกแบบ batch หรือการค้นหาพารามิเตอร์ซึ่งสามารถเลื่อนเวลาได้โดยไม่กระทบไทม์ไลน์สำคัญ
- ฝ่ายไอทีองค์กร ที่ต้องการลดค่าใช้จ่ายพลังงานและรายงานการปล่อยคาร์บอนของโครงสร้างพื้นฐานคลาวด์
- ผู้พัฒนาแอปพลิเคชัน และทีม DevOps ที่ต้องการผสานการจัดการงานกับสัญญาณความเข้มคาร์บอนและนโยบายความยั่งยืนขององค์กร
สรุปคือ Carbon‑Aware AI Scheduler เป็นฟีเจอร์ที่ตอบโจทย์งานฝึกแบบที่เลื่อนได้และองค์กรที่มุ่งลดคาร์บอนของไอที โดยการทดสอบภายในชี้ว่ามีศักยภาพลดทั้งการปล่อยคาร์บอนและค่าไฟได้ถึงประมาณ 20% ซึ่งทำให้เป็นเครื่องมือที่มีค่าสำหรับองค์กรที่ต้องการผสานกลยุทธ์ด้านความยั่งยืนเข้ากับการพัฒนา AI อย่างเป็นรูปธรรม
ทำงานอย่างไร: หลักการทางเทคนิคของ Carbon‑Aware AI Scheduler
สัญญาณพลังงานและการคาดการณ์ (Carbon Forecasting)
หัวใจของ Carbon‑Aware AI Scheduler คือการใช้สัญญาณจากแหล่งข้อมูลพลังงานหลายแหล่ง เช่น grid carbon intensity APIs, regional renewable generation forecast, และตลาดพลังงานแบบเรียลไทม์ เพื่อประเมินช่วงเวลาที่ “สะอาด” สำหรับการรันงานฝึกโมเดล ระบบจะดึงข้อมูลจาก API หลัก (เช่น ENTSO‑E, Open‑Grid, ผู้ผลิตพลังงานท้องถิ่น) รวมถึงตัวชดเชยเชิงสถิติ (ensemble forecasting) เพื่อสร้างการคาดการณ์ความเข้มคาร์บอนแบบ horizon ที่ยืดหยุ่นได้ (ตัวอย่าง 6–72 ชั่วโมง) พร้อมค่าความเชื่อมั่นของการทำนาย
ข้อมูลที่ประมวลผลได้แก่ carbon intensity (gCO2e/kWh), สัดส่วนพลังงานหมุนเวียน (% of renewable), และสัญญาณจากตลาด (price signals, demand response events) โดย Scheduler จะเก็บเป็น time series และทำ smoothing/uncertainty quantification เพื่อใช้ในการตัดสินใจจัดเวลาอย่างปลอดภัยสำหรับงานที่มีข้อจำกัดด้าน SLA
การจัดลำดับคิวงานและอัลกอริทึมการจัดเวลา
เมื่อได้รับสัญญาณพลังงาน Scheduler จะนำข้อมูลพลังงานมาผสมกับเมตริกของงาน (job metadata) เช่น estimated runtime, resource request (GPU/TPU/CPU), deadline, priority, และ checkpoint capability เพื่อคำนวณ scheduling window ที่เหมาะสม ระบบใช้กลไก hybrid ระหว่าง rule‑based และ optimizer‑based โดยมีส่วนประกอบหลักดังนี้:
- Window generation: สร้างหน้าต่างเวลาที่เป็นไปได้ (candidate windows) ตาม forecast เช่นช่วงที่ carbon intensity ต่ำสุดภายใน 24 ชั่วโมงถัดไป
- Cost function: ฟังก์ชันเป้าหมายรวมทั้งการปล่อยคาร์บอนและค่าใช้จ่าย (carbon cost + monetary cost) โดยสามารถปรับน้ำหนักเพื่อสะท้อนนโยบายองค์กร
- Constraint handling: บังคับใช้เงื่อนไข deadline, budget cap, resource affinity และ SLA เช่นห้ามรอหาก deadline ใกล้มากกว่า threshold
- Preemption & backfill: รองรับการ preempt งานที่กำลังรัน (ด้วย checkpoint/restore) เพื่อย้ายโหลดไปยังช่วงที่สะอาดกว่า และใช้ backfill สำหรับงานสั้นที่หาช่องว่างได้
ตัวอย่างเชิงตัวเลข: ในการทดสอบภายใน เมื่อใช้ weighting ที่ลด carbon เป็นสำคัญ ระบบสามารถเลื่อนงานฝึกที่ไม่เร่งด่วนไปในช่วงที่ carbon intensity ต่ำกว่าเฉลี่ย 30% และทำให้ค่า CO2e ลดลงได้ประมาณ 18–20% โดยเพิ่ม latency ของงานที่เลื่อนไปเฉลี่ย 1.5–4 ชั่วโมง ขึ้นกับ policy ที่ตั้งไว้
การประเมิน trade‑off ระหว่างเวลาเสร็จงานและการลดการปล่อยคาร์บอน
การตัดสินใจของ Scheduler เป็นการแลกเปลี่ยนระหว่างเวลาเสร็จงาน (latency) กับการลดการปล่อยคาร์บอน (emissions). ระบบประเมิน trade‑off นี้โดยใช้ multi‑objective optimization: หนึ่งแกนเป็น expected completion time และอีกแกนเป็น expected emissions reduction (เช่นกิโลกรัม CO2e ที่ประหยัดได้) พร้อมการคำนวณความเสี่ยงจากความไม่แน่นอนของ forecast
นโยบายองค์กรต่างกันจะนำไปสู่จุดตัดสินใจต่างกัน ตัวอย่างเช่น:
- องค์กรที่เน้น sustainability: ให้ weight การลดคาร์บอนสูงกว่า อาจยอมเพิ่ม latency สูงสุด 6–12 ชั่วโมง
- องค์กรที่เน้น latency/real‑time: กำหนด deadline เข้มงวดและ budget cap ทำให้ Scheduler ต้องใช้ทรัพยากรทันที แม้ carbon intensity จะสูงกว่า
- นโยบาย hybrid: กำหนด SLA tiering — tier ต่ำรอเพื่อประหยัดคาร์บอน ส่วน tier สูงรันทันที
การสื่อสารกับคลัสเตอร์ฝึก (GPU/TPU orchestration)
ในระดับปฏิบัติการ Scheduler ทำหน้าที่เป็น orchestration layer ที่เชื่อมต่อกับระบบจัดการคลัสเตอร์ เช่น Kubernetes, Slurm หรือระบบเฉพาะของผู้ให้บริการคลาวด์ โดยมีคอมโพเนนต์หลักคือ Job Controller, Resource Allocator และ Telemetry Agent ซึ่งทำงานร่วมกันดังนี้:
- Job Controller: รับคำสั่ง schedule/unschedule/ preempt และแปลงเป็นคำสั่งที่ระบบคลัสเตอร์เข้าใจ (เช่น Kubernetes Pod spec หรือ Slurm sbatch)
- Resource Allocator: ทำ placement-aware scheduling (พิจารณา GPU type, memory, NVLink topology) และ energy‑aware placement (เช่นวางงานที่รองรับบนโซนที่มี renewable สูงสุด หรือรวมงานใน rack เดียวเพื่อลด losses)
- Telemetry Agent: เก็บข้อมูลการใช้พลังงานจริงจากเซิร์ฟเวอร์และตัววัดภายใน (PMU, RAPL, PDU) เพื่อย้อนประเมินและปรับโมเดลคาดการณ์
กรณีการ preemption: Scheduler จะสั่งให้ Job Controller ทำ checkpoint และย้ายงานไปยัง node/zone อื่น หรือรอจนถึง window ถัดไป หากงานไม่สามารถ checkpoint ได้ ระบบจะพิจารณาใช้ burst capacity/spot instances เป็นตัวเลือกสำรองเพื่อลด latency โดยเฉพาะเมื่อ budget cap อนุญาต
การบูรณาการกับระบบบิลลิ่งและนโยบายองค์กร
เพื่อให้ใช้งานในระดับองค์กรได้จริง Scheduler ต้องผสานกับระบบบิลลิ่งและการจัดสรรงบประมาณอย่างแนบแน่น โดยมีฟีเจอร์สำคัญคือ:
- Tagging และ chargeback: ติดป้ายข้อมูลงาน (project, team, carbon‑aware flag) เพื่อให้ข้อมูลบิลลิ่งแยกตามโครงการและคำนวณค่าใช้จ่ายพร้อมคาร์บอนคอสต์
- Budget cap enforcement: หากงบประมาณที่กำหนดถูกใช้งานเกิน Scheduler จะปรับ policy อัตโนมัติ เช่น ลดการใช้ instance แบบ on‑demand หรือเลื่อนงานที่ไม่เร่งด่วน
- Audit trail และรายงาน ESG: บันทึกการตัดสินใจทาง scheduling, emissions saved, และ cost impact เพื่อใช้ในการรายงานความยั่งยืนต่อผู้บริหารและหน่วยงานภายนอก
การผนวกรวมนี้ช่วยให้องค์กรสามารถตั้ง policy เช่น "ลดคาร์บอนให้ได้อย่างน้อย 15% โดยไม่เกินค่าใช้จ่าย X%" หรือ "หัวหน้างานสามารถมอบ priority พิเศษแต่จะถูกคิดค่าธรรมเนียมเพิ่มเติม" ซึ่ง Scheduler จะปฏิบัติตามและแสดงผลกระทบทันที
สรุปด้านเทคนิค
โดยสรุป Carbon‑Aware AI Scheduler เป็นชั้นการจัดการเชิงนโยบายและเชิงปฏิบัติการที่เชื่อมโยงการคาดการณ์พลังงาน การจัดคิวอัจฉริยะ การควบคุมการรันบนฮาร์ดแวร์ฝึก (GPU/TPU) และการบูรณาการกับระบบบิลลิ่ง เพื่อให้สามารถลดการปล่อยคาร์บอนได้จริงภายใต้ข้อจำกัดด้านเวลาและงบประมาณ ในการทดลองภาคสนามที่ผู้ให้บริการคลาวด์ไทยอ้างถึง ระบบนี้สามารถลด CO2e และค่าไฟรวมได้สูงสุดราว 20% ขึ้นกับนโยบายและลักษณะงาน ซึ่งแสดงถึงความเป็นไปได้ที่จับต้องได้สำหรับองค์กรที่ต้องการผสานความยั่งยืนเข้ากับงาน AI ระดับองค์กร
ผลการทดสอบ: วิธีวัดและตัวเลข 20% มาจากไหน
ผลการทดสอบ: วิธีวัดและตัวเลข 20% มาจากไหน
ผลการทดสอบของผู้ให้บริการคลาวด์ถูกออกแบบมาเพื่อให้สามารถเปรียบเทียบผลลัพธ์ระหว่างการรันงานแบบ baseline (รันทันที) กับการรันภายใต้ Carbon‑Aware AI Scheduler (เลื่อนรันไปยังช่วงที่มีสัดส่วนพลังงานหมุนเวียนสูง) โดยใช้ชุดระเบียบวิธีที่ชัดเจนและตัวชี้วัดเชิงพลังงานและคาร์บอนที่เป็นมาตรฐาน ทีมทดสอบระบุรายละเอียดดังนี้:

- ชุดงานตัวอย่าง (training workloads): ชุดทดสอบประกอบด้วยงานฝึกโมเดลขนาดกลางเป็นหลัก จำนวนประมาณ 150 งาน โดยแต่ละงานมีขนาด ~100 GPU‑hours (เช่น การฝึกโมเดลวิชัน/ภาษาแบบกลาง) เพื่อให้สอดคล้องกับภาระงานที่ลูกค้ารายองค์กรมักใช้งาน
- ขนาดทรัพยากรและรวมการใช้: งานรวมทั้งหมดคิดเป็น ~15,000 GPU‑hours (150 งาน × 100 GPU‑hours) ที่รันตลอดระยะเวลา 4 สัปดาห์ (1 เดือน)
- ระยะเวลาทดสอบ: การทดลองหลักใช้ระยะเวลา 1 เดือน เพื่อเก็บความผันผวนของสัดส่วนพลังงานหมุนเวียนและราคาไฟฟ้าตามช่วงเวลา
- พื้นที่พลังงาน (regions): ทดสอบครอบคลุม 3 โซนภายในประเทศ (ตัวอย่างเรียกเป็น Region A: ภาคกลาง/กรุงเทพฯ, Region B: ภาคตะวันออก, Region C: ภาคเหนือ) ที่มีโครงสร้างสัดส่วนพลังงานต่างกันและมีรูปแบบการผลิตพลังงานหมุนเวียนต่างกัน
- เมตริกที่วัด: ใช้ตัวชี้วัดหลัก 3 ด้าน — พลังงานไฟฟ้า (kWh), การปล่อยคาร์บอน (kgCO2e) และ ค่าไฟฟ้า (บาท) โดยคำนวณจากข้อมูล telemetry ของคลัสเตอร์ (การใช้พลังงานจริงหรือการประมาณจากโปรไฟล์พลังงานต่อ GPU) ร่วมกับตารางค่าไฟฟ้าเชิงพาณิชย์และตัวชี้วัดความเข้มคาร์บอนของกริดตามโซนและเวลา
ในการคำนวณตัวเลขผู้ทดสอบใช้สมมติฐานการแปลงที่ชัดเจนเพื่อให้สามารถเปรียบเทียบได้อย่างเป็นระบบ เช่น พลังงานต่อ GPU‑hour = 0.7 kWh (ค่าเฉลี่ยของเครื่อง GPU แบบเซิร์ฟเวอร์ที่ใช้งานจริง), และใช้ค่า grid carbon intensity ตามโซนและช่วงเวลา (ตัวอย่างเช่น Region A baseline 0.45 kgCO2e/kWh ลดลงเป็น 0.36 kgCO2e/kWh ในช่วงพลังงานหมุนเวียนสูง) รวมทั้งใช้ราคาค่าไฟเชิงพาณิชย์ตัวอย่าง 4.5 บาท/kWh เพื่อแปลงเป็นต้นทุนค่าไฟ
ตัวอย่างการคำนวณสำหรับงานขนาด 100 GPU‑hours (ตัวอย่างแสดงวิธีที่นำไปสู่ตัวเลขลด ~20%):
- พลังงานรวม = 100 GPU‑hours × 0.7 kWh/GPU‑hour = 70 kWh
- การปล่อยคาร์บอน (baseline) = 70 kWh × 0.45 kgCO2e/kWh = 31.5 kgCO2e
- การปล่อยคาร์บอน (carbon‑aware) = 70 kWh × 0.36 kgCO2e/kWh = 25.2 kgCO2e → ลดได้ 6.3 kgCO2e (~20%)
- ค่าไฟ (baseline) = 70 kWh × 4.5 บาท/kWh = 315 บาท
- ค่าไฟ (carbon‑aware) สมมติช่วงพลังงานหมุนเวียนสูงทำให้ค่าไฟลดลงตามอุปทาน/ราคาเป็น 3.7 บาท/kWh → 70 × 3.7 = 259 บาท → ลดได้ ~17.8%
การรายงานผลทำในลักษณะ เปรียบเทียบเฉลี่ย ระหว่างสภาพรันทันที (baseline) กับสภาพที่เปิดให้ Scheduler เลื่อนงานไปยังช่วงพลังงานหมุนเวียนสูง โดยแยกวิเคราะห์ตามปัจจัยสำคัญ เช่น โซนภูมิศาสตร์ ระดับความยืดหยุ่นของงาน (อนุญาตให้เลื่อนสูงสุดกี่ชั่วโมง) และประเภทงาน ตัวเลขสรุปที่ผู้ให้บริการประกาศคือ การลดค่าไฟและการปล่อยคาร์บอนเฉลี่ยอยู่ในช่วงประมาณ 15–20% โดยรายละเอียดเพิ่มเติมจากการวิเคราะห์พบว่า:
- งานที่มีความยืดหยุ่นสูง (สามารถเลื่อนได้ 12–24 ชั่วโมง) ในโซนที่มีความแปรผันของสัดส่วนพลังงานหมุนเวียนสูง ให้ประสิทธิภาพในการลดได้มากกว่า 20%
- งานที่ต้องรันทันที (latency‑sensitive) แทบไม่ได้ประหยัด เพราะไม่มีการเลื่อนช่วงเวลา
- ผลการลดแตกต่างกันตามโซน — โซนที่มีสัดส่วนพลังงานหมุนเวียนสูงและความผันผวนของราคามาก จะเห็นการลดทั้งค่าไฟและคาร์บอนในระดับสูงสุด
เชิงสถิติ ทีมทดสอบรายงานค่าเฉลี่ยพร้อมช่วงความเชื่อมั่น (เช่น mean ± 95% CI) โดยใช้การสุ่ม bootstrap จากชุดงานทั้งหมดเพื่อตรวจสอบความคงที่ของผลลัพธ์ ผลลัพธ์ที่ได้แสดงความเสถียรว่า การลดเฉลี่ยระหว่าง 15–20% ไม่ได้เกิดจากงานบางส่วนที่ได้ผลมากเพียงไม่กี่งาน แต่เป็นผลสืบเนื่องจากการวางแผนเวลาในระดับกลุ่มงานที่กว้าง
โดยสรุป ตัวเลข ~20% มาจากการทดลองภาคสนามที่ใช้ชุดงานขนาดกลางจำนวนมาก ครอบคลุมหลายโซนและช่วงเวลา วัดทั้งพลังงาน (kWh), การปล่อยคาร์บอน (kgCO2e) และค่าไฟ (บาท) เปรียบเทียบระหว่างการรันทันทีและการรันที่ถูกเลื่อนโดย Carbon‑Aware Scheduler ผลตัวอย่างที่ได้สะท้อนว่า การจัดเวลาให้สอดคล้องกับช่วงที่กริดมีสัดส่วนพลังงานหมุนเวียนสูง สามารถลดการปล่อยคาร์บอนและค่าไฟโดยเฉลี่ยในระดับ 15–20% ขึ้นกับเงื่อนไขโซนและความยืดหยุ่นของงานแต่ละประเภท
ผลกระทบต่อค่าใช้จ่ายและการดำเนินงานขององค์กร
ผลกระทบโดยรวมต่อบิลคลาวด์
การรายงานทดสอบที่ระบุว่าลดการปล่อยคาร์บอนและการใช้ไฟฟ้าได้ ~20% หากตีความอย่างง่าย ๆ จะหมายถึงการลดปริมาณพลังงานที่ใช้โดยคลัสเตอร์สำหรับงานฝึกโมเดลลง 20% ในช่วงเวลาที่ scheduler เลือกทำงาน อย่างไรก็ตาม ผลลัพธ์เชิงการเงินต่อบิลคลาวด์ขึ้นอยู่กับสัดส่วนของต้นทุนพลังงานในบิลรวมขององค์กร (energy cost share) และสัดส่วนการใช้งานที่สามารถเลื่อนเวลาได้จริง
สูตรเชิงสรุปสำหรับการลดบิลโดยประมาณคือ:
- ประหยัดรวม (%) = 20% × สัดส่วนต้นทุนพลังงาน (%) × สัดส่วนงานที่เลื่อนเวลาได้ (%)
- ตัวอย่าง หากต้นทุนพลังงานคิดเป็น 40% ของค่าใช้จ่ายคลาวด์ทั้งหมด และ 75% ของงานเป็น batch/เลื่อนเวลาได้ ผลประหยัดโดยรวม ≈ 0.20 × 40% × 75% = 6.0% ของบิลคลาวด์
ตัวอย่างคำนวณการประหยัดค่าไฟสำหรับองค์กรขนาดต่าง ๆ
ต่อไปนี้เป็นตัวอย่างสมมติที่แสดงให้เห็นถึงผลกระทบเชิงตัวเงิน โดยสมมติการลดพลังงาน 20% สำหรับงานที่เป็นไปได้ตามสัดส่วนงานที่เลื่อนเวลาได้:
- องค์กรขนาดเล็ก — งบคลาวด์ฝึกโมเดลเฉลี่ย 300,000 บาท/เดือน (ประมาณ 8,500 USD): สมมติต้นทุนพลังงานคิดเป็น 30% ของบิล (90,000 บาท) และสัดส่วนงานเลื่อนเวลาได้ 70% → ประหยัดต่อเดือน ≈ 0.20×90,000×0.70 = 12,600 บาท (~357 USD) เท่ากับลดบิลรวม ~4.2%
- องค์กรขนาดกลาง — งบคลาวด์ 3,000,000 บาท/เดือน (ประมาณ 85,000 USD): ต้นทุนพลังงาน 35% (1,050,000 บาท) สัดส่วนงานเลื่อนเวลาได้ 80% → ประหยัดต่อเดือน ≈ 0.20×1,050,000×0.80 = 168,000 บาท (~4,760 USD) ลดบิลรวม ~5.6%
- องค์กรขนาดใหญ่ — งบคลาวด์ 30,000,000 บาท/เดือน (ประมาณ 850,000 USD): ต้นทุนพลังงาน 40% (12,000,000 บาท) สัดส่วนงานเลื่อนเวลาได้ 60% → ประหยัดต่อเดือน ≈ 0.20×12,000,000×0.60 = 1,440,000 บาท (~40,800 USD) ลดบิลรวม ~4.8%
หมายเหตุ: จำนวนจริงจะแตกต่างตามค่าไฟฟ้าพื้นที่, รูปแบบการใช้งาน (GPU vs CPU), และเงื่อนไขการคิดราคาของผู้ให้บริการคลาวด์ (เช่น อัตรา compute vs storage vs network)
การประเมิน ROI และต้นทุนในการนำ scheduler มาใช้
ROI ของการปรับมาใช้ Carbon‑Aware AI Scheduler ขึ้นกับหลายปัจจัยสำคัญ ได้แก่ ต้นทุนการติดตั้ง/พัฒนา (integration), ค่าใช้จ่ายในการดำเนินงานเพิ่มเติม (monitoring, policy management), และสัดส่วนงานที่เป็น batch หรือเลื่อนเวลาได้
- ค่าติดตั้งและบูรณาการ — อาจอยู่ในช่วงตั้งแต่หลักหมื่นบาทสำหรับการเปิดใช้งานแบบบริการ (managed) ไปจนถึงหลักล้านบาทสำหรับองค์กรที่ต้องการผสานกับระบบภายในและ custom policy
- ระยะเวลาคืนทุน — หากการประหยัดรายเดือนอยู่ที่ 168,000 บาท และค่าใช้จ่ายในการติดตั้งรวม 840,000 บาท ระยะคืนทุน ≈ 5 เดือน; สำหรับองค์กรขนาดเล็กที่ประหยัด 12,600 บาท/เดือน และต้นทุนติดตั้ง 200,000 บาท จะคืนทุน ≈ 16 เดือน
- ตัวแปรสำคัญ — หากสัดส่วนงานที่เลื่อนเวลาได้ (f) ต่ำลง เช่น งานเร่งด่วนมากขึ้น ค่า ROI จะลดลงตาม f; นอกจากนี้ความผันแปรของราคาไฟฟ้าและนโยบายราคาแบบ time‑of‑use ในแต่ละภูมิภาคสามารถเพิ่มหรือลดผลตอบแทนได้อย่างมีนัยสำคัญ
ผลต่อ SLA และ trade‑offs ระหว่างความเร็วกับคาร์บอนต่ำ
การเลื่อนเวลาหรือการรันงานในช่วงที่ไฟฟ้าหมุนเวียนสูงสุดมักมีผลข้างเคียงต่อเวลาเสร็จงาน (latency) และ SLA ในการส่งมอบงาน ดังนี้
- งานเร่งด่วน (real‑time / low‑latency) — ไม่เหมาะกับการเลื่อนเวลา การบังคับใช้ scheduler แบบครอบคลุมทั้งหมดอาจทำให้เกิดการละเมิด SLA ได้ ดังนั้นต้องมีนโยบายแยกชั้นความสำคัญ (priority queues) และสำรองความสามารถ (on‑demand capacity) สำหรับงานสำคัญ
- งาน batch และการฝึกซ้ำ (offline training) — เหมาะสมที่สุดสำหรับการ schedule เพื่อประหยัดพลังงานและคาร์บอน การเลื่อนเวลาเป็นชั่วโมงหรือเป็นคืนมักยอมรับได้และให้ผลประหยัดสูงสุด
- ผลกระทบเชิงปริมาณ — หากองค์กรยอมให้ความล่าช้าเฉลี่ยเพิ่มขึ้น 4–12 ชั่วโมงสำหรับงาน batch แต่สามารถประหยัดพลังงานได้ 20% ในสัดส่วนงานที่เลื่อนเวลาได้ 80% ผลที่เกิดขึ้นคือการลดบิลโดยรวมตามตัวอย่างก่อนหน้า แต่จะต้องชั่งน้ำหนักผลประโยชน์ด้านต้นทุนกับความเสี่ยงด้านการปล่อยงานล่าช้า
ข้อเสนอแนะแนวทางปฏิบัติและการลดความเสี่ยง
เพื่อให้ได้ประโยชน์สูงสุดโดยลดความเสี่ยงต่อ SLA แนะนำแนวทางปฏิบัติดังนี้
- จำแนกงานตามความสำคัญ — สร้าง policy ที่ชัดเจนสำหรับงานที่ต้องการความเร็วสูง, งานที่สามารถเลื่อนเวลาได้ และงานที่ต้องการทรัพยากรต่อเนื่อง
- ผสมเป้าหมายค่าใช้จ่ายและคาร์บอน — ใช้ตัวชี้วัดผสม (cost‑adjusted carbon metric) เพื่อให้ scheduler ตัดสินใจทั้งเชิงคาร์บอนและค่าใช้จ่าย โดยเฉพาะในพื้นที่ที่ค่าไฟฟ้ามีความผันผวน
- สำรองความสามารถ — กำหนด capacity buffer หรือใช้ instance แบบ on‑demand เป็น fast‑lane สำหรับงานเร่งด่วน เพื่อลดความเสี่ยงต่อ SLA
- วัดผลเป็นระยะ — ติดตามการลดพลังงานและค่าใช้จ่ายอย่างต่อเนื่องและปรับแต่ง policy ตามข้อมูลจริง (grid carbon intensity, price signals, job profile)
สรุปแล้ว Carbon‑Aware AI Scheduler สามารถสร้างการประหยัดค่าไฟและลดการปล่อยคาร์บอนได้อย่างมีนัยสำคัญ โดยเฉพาะกับองค์กรที่มีสัดส่วนงาน batch สูงและต้นทุนพลังงานในบิลคลาวด์สูง ROI มักจะดี แต่ความสำเร็จเชิงปฏิบัติขึ้นกับการจัดกลยุทธ์การจัดลำดับความสำคัญของงาน การจัดการ SLA และการประเมินต้นทุนการบูรณาการอย่างรอบคอบ
ข้อจำกัด ความเสี่ยง และประเด็นทางเทคนิค
ข้อจำกัด ความเสี่ยง และประเด็นทางเทคนิค
การนำระบบ Carbon‑Aware AI Scheduler มาใช้ในสภาพแวดล้อมการประมวลผลคลาวด์ในไทยมีศักยภาพลดการปล่อยคาร์บอนและค่าไฟฟ้า แต่ต้องยอมรับข้อจำกัดเชิงเทคนิคและความเสี่ยงที่สำคัญก่อนตัดสินใจใช้งานจริง หนึ่งในประเด็นหลักคือความไม่แน่นอนของการพยากรณ์กำลังไฟฟ้าจากแหล่งพลังงานหมุนเวียน เช่น พลังงานแสงอาทิตย์และลม ซึ่งมีความแปรปรวนตามสภาพอากาศและชั่วโมงของวัน งานวิจัยเชิงอุตสาหกรรมรายงานว่า forecast error ของกำลังการผลิตหมุนเวียนในช่วงระยะสั้นถึงกลางอาจอยู่ในช่วงประมาณ 5–25% ขึ้นอยู่กับฮอริซอนและภูมิภาค ซึ่งหมายความว่าผลลัพธ์การลดคาร์บอนที่คาดหวัง (เช่น ตัวเลข "ลดได้ถึง 20%") อาจลดลงเมื่อเผชิญกับความไม่แน่นอนเหล่านี้ ระบบ scheduler จึงต้องออกแบบให้มีการปรับตัวต่อการเปลี่ยนแปลงแบบเรียลไทม์และมีแผนสำรองเมื่อการพยากรณ์เบี่ยงเบนมาก
อีกข้อจำกัดสำคัญคือประเภทของงานคอมพิวต์: งานที่มีข้อกำหนดด้านความหน่วง (latency) หรือ SLA เข้มงวด (เช่น inference แบบเรียลไทม์, งานตอบสนองลูกค้า) มักไม่สามารถเลื่อนเวลาไปช่วงที่มีพลังงานหมุนเวียนสูงได้ งานฝึกโมเดลขนาดใหญ่ที่ยอมรับการหน่วงได้จะได้ประโยชน์มากกว่า ในทางปฏิบัติ ผู้ให้บริการและลูกค้าจำเป็นต้องจำแนกงานตามระดับความยืดหยุ่นและออกแบบนโยบายการจัดตารางแบบผสม (hybrid scheduling) เพื่อไม่ให้กระทบต่อบริการที่ต้องการตอบสนองทันที
การวัดและรายงานการลดคาร์บอนเป็นอีกประเด็นทางเทคนิคและเชิงนโยบายที่ซับซ้อน ในทางปฏิบัติการคำนวณการปล่อยก๊าซเรือนกระจกสำหรับงานประมวลผลคลาวด์เกี่ยวข้องกับการจัดสรร Scope 2 (การบริโภคไฟฟ้า) และการเลือกใช้ปัจจัยการปล่อย (emission factors) ว่าจะเป็นแบบ marginal (การเปลี่ยนแปลงเพิ่มเติมของการปล่อยเมื่อมีการใช้พลังงานเพิ่มขึ้น) หรือแบบ average (ค่าเฉลี่ยของกริด) ซึ่งให้ผลลัพธ์ที่แตกต่างกันอย่างมีนัยสำคัญ ตัวอย่างเช่น การใช้ marginal emission factor อาจแสดงการลดที่มากกว่าในบริบทที่ไฟฟ้าเพิ่มเติมมาจากโรงไฟฟ้าฟอสซิลบางประเภท ขณะที่ average factor ให้มุมมองรวมภาพชุมชน การเลือกวิธีการต้องชัดเจนในรายงานและสอดคล้องกับมาตรฐานที่ยอมรับ เช่น GHG Protocol และ/หรือมาตรฐาน ISO ที่เกี่ยวข้อง เพื่อให้การอ้างอิงความคืบหน้าและการตรวจสอบภายนอกเป็นไปได้และโปร่งใส
สุดท้าย ความเสี่ยงด้านความปลอดภัยและความน่าเชื่อถือเมื่อระบบ scheduler ใช้กลไก preemption หรือการ pause/ resume งานต้องได้รับการจัดการอย่างรอบคอบ การหยุดแล้วเริ่มใหม่ของงานฝึกโมเดลอาจนำไปสู่ปัญหาเช่นข้อมูลไม่สอดคล้อง (data consistency), การสูญเสียความคืบหน้าหากไม่มี checkpointing ที่เพียงพอ, การเพิ่มค่าใช้จ่ายเนื่องจากค่า I/O และ overhead ในการย้ายคอนเทนเนอร์/VM รวมถึงความเสี่ยงด้านความปลอดภัยเมื่อมีการเคลื่อนย้ายสถานะการทำงานระหว่างโนดซึ่งอาจเปิดช่องโหว่ในการรั่วไหลของข้อมูลหรือการถูกโจมตี จึงจำเป็นต้องออกแบบกลไก checkpoint, encryption ของ states, การยืนยันความสมบูรณ์ของข้อมูล (integrity checks) และนโยบายการกู้คืน (recovery) ที่เข้มงวด
- ความไม่แน่นอนของพยากรณ์: ควรใช้หลายแหล่งข้อมูลพยากรณ์, เทคนิค ensemble forecasting และการอัปเดตแบบเรียลไทม์เพื่อลดความเสี่ยงที่ผลลดคาร์บอนจะต่ำกว่าเป้า
- งานที่มี SLA เข้มงวด: จัดประเภทงาน (workload classification) และใช้นโยบาย hybrid scheduling ที่ผสมระหว่าง immediate execution และ opportunistic scheduling
- การวัดและรายงาน: กำหนดนโยบายวัดแบบเป็นมาตรฐานโดยใช้ GHG Protocol/ISO, ระบุว่าคำนวณด้วย marginal หรือ average emission factors และเผยแพร่วิธีการให้ตรวจสอบได้
- ความปลอดภัยและความน่าเชื่อถือ: รองรับ checkpointing, encryption, access control, และมี SLA สำหรับการ preemption รวมถึงการทดสอบความทนทาน (resilience testing)
โดยสรุป แม้ Carbon‑Aware AI Scheduler จะเป็นเครื่องมือที่มีประโยชน์ในการลดการปล่อยคาร์บอนและต้นทุนพลังงาน แต่การนำไปใช้ต้องพิจารณาข้อจำกัดด้านพยากรณ์ กรอบงานการวัดที่ชัดเจนสำหรับ Scope 2 และ emission factors รวมทั้งมาตรการด้านความปลอดภัยและความน่าเชื่อถือ เพื่อให้ผลลัพธ์ที่รายงานมีความน่าเชื่อถือและการดำเนินงานไม่กระทบต่อบริการที่สำคัญ
บริบทสากลและนโยบายไทย: เทียบกับแนวปฏิบัติทั่วโลก
บริบทสากลและนโยบายไทย: เทียบกับแนวปฏิบัติทั่วโลก
ในระดับสากล ผู้ให้บริการคลาวด์รายใหญ่ได้เริ่มนำแนวคิด carbon‑aware มาเป็นฟีเจอร์มาตรฐานเพื่อลดการปล่อยก๊าซเรือนกระจกของงานประมวลผล ตัวอย่างเช่น บริษัทเทคโนโลยีชั้นนำได้เผยแพร่งานวิจัยและเครื่องมือที่ช่วยกำหนดตารางการประมวลผลเมื่อกำลังไฟฟ้าหมุนเวียนมีสัดสวนสูง หรือเมื่อราคาพลังงานและความเข้มต่อคาร์บอนต่ำกว่า ผลการศึกษาภายในและงานวิจัยอิสระชี้ว่าการปรับเวลาการฝึกโมเดลหรือรันงานแบตช์ให้สัมพันธ์กับสัญญาณพลังงานสะอาดสามารถลดการปล่อยคาร์บอนได้ในช่วงกว้าง เช่นประมาณ 10–40% ขึ้นกับสภาพกริดและรูปแบบการใช้งาน ซึ่งสอดคล้องกับกรอบการรายงานคาร์บอนสากล เช่น GHG Protocol, TCFD และมาตรฐาน ISO ที่องค์กรใช้เป็นแนวทางการคำนวณและรายงานผล
สำหรับบริบทไทย สัดส่วนพลังงานหมุนเวียนในส่วนผสมของการผลิตไฟฟ้ากำลังเพิ่มขึ้นอย่างต่อเนื่อง โดยมีการขยายตัวของพลังงานแสงอาทิตย์และพลังงานลมในระบบไฟฟ้า แม้จะยังไม่เทียบเท่าบางประเทศที่มีสัดส่วนสูง แต่ปัจจุบันสัดส่วนพลังงานหมุนเวียนของไทยอยู่ในระดับสองหลัก (>10%) และมีแนวโน้มสูงขึ้นตามนโยบายของกระทรวงพลังงานและแผนพัฒนากำลังผลิตไฟฟ้า (PDP) อย่างไรก็ดี ความผันผวนของกริดเป็นปัจจัยสำคัญ — โดยเฉพาะพลังงานแสงอาทิตย์ที่มีการผลิตสูงในช่วงกลางวันและลดลงในช่วงพลบค่ำ ซึ่งหมายความว่า เวลา (time‑of‑generation) กลายเป็นตัวแปรที่สำคัญสำหรับการตัดสินใจรันงานฝึกโมเดลเพื่อให้ได้ผลลัพธ์ด้านคาร์บอนและต้นทุนที่ดีที่สุด
การผสานข้อมูล real‑time price signals และข้อมูลคาร์บอนอินเทนซิตี้ของกริดเข้ากับ Carbon‑Aware AI Scheduler เป็นโอกาสเชิงปฏิบัติที่สำคัญในไทย โดยสามารถเพิ่มประสิทธิภาพทั้งในมิติของการลดค่าไฟและลดการปล่อยคาร์บอนได้พร้อมกัน การเชื่อมต่อกับแหล่งข้อมูลเรียลไทม์ เช่น สัญญาณราคาจากตลาดไฟฟ้า (real‑time/spot price) ข้อมูลการผลิตจากผู้ผลิตไฟฟ้ารายใหญ่ (เช่น EGAT รวมทั้ง PPA ของผู้ผลิตเอกชน) และการวัดคาร์บอนอินเทนซิตี้ของโครงข่าย จะช่วยให้ Scheduler ตัดสินใจได้แม่นยำขึ้น ตัวอย่างฟีเจอร์ที่เป็นไปได้ได้แก่:
- การเลื่อนเวลางานอัตโนมัติ (auto‑scheduling) ไปยังช่วงที่สัญญาณราคาต่ำหรือปริมาณพลังงานหมุนเวียนสูง
- การปรับขนาดทรัพยากรแบบไดนามิก เพื่อลดการใช้พีคและประหยัดค่าไฟในช่วงราคาแพง
- การผสานข้อมูลรายชั่วโมง จากตลาดไฟฟ้าและผู้ผลิตเพื่อคำนวณความคุ้มค่าระหว่างต้นทุนกับการลดคาร์บอน
ในเชิงนโยบายและความร่วมมือ มีโอกาสชัดเจนสำหรับผู้ให้บริการคลาวด์ไทยในการทำงานร่วมกับหน่วยงานกำกับและผู้ผลิตพลังงานท้องถิ่น ได้แก่ การประสานข้อมูลกับ คณะกรรมการกำกับกิจการพลังงาน (ERC), การเชื่อมต่อข้อมูลการผลิตกับ การไฟฟ้าฝ่ายผลิตแห่งประเทศไทย (EGAT) รวมถึงการร่วมมือกับการไฟฟ้าส่วนภูมิภาค (PEA) และการไฟฟ้านครหลวง (MEA) เพื่อให้เข้าถึงสัญญาณราคาจริงและข้อมูลการผลิตแบบเรียลไทม์ นอกจากนี้ การสร้างกรอบทดลอง (sandbox) ร่วมกับหน่วยงานกำกับหรือการทำโครงการนำร่องร่วมกับผู้ผลิตพลังงานท้องถิ่นและผู้ถือ PPA สามารถช่วยทดสอบและวัดผลทั้งในเชิงเทคนิคและเชิงนโยบายก่อนการขยายผลในวงกว้าง
สรุปแล้ว การเปิดตัว Carbon‑Aware AI Scheduler ในบริบทไทยไม่เพียงเป็นนวัตกรรมทางเทคนิค แต่ยังเป็นโอกาสทางนโยบายและเชิงธุรกิจในการบูรณาการข้อมูลพลังงานจริง (real‑time) กับการบริหารจัดการงานคอมพิวต์ การร่วมมือกับหน่วยงานกำกับและผู้ผลิตพลังงานท้องถิ่นจะช่วยเพิ่มความน่าเชื่อถือของข้อมูล เปิดทางสู่บริการที่ตอบโจทย์ทั้งการลดคาร์บอนและการลดค่าใช้จ่ายให้กับภาคธุรกิจได้อย่างเป็นรูปธรรม
แนวทางปฏิบัติและคำแนะนำสำหรับองค์กรไทย
แนวทางปฏิบัติและคำแนะนำสำหรับองค์กรไทย
การพิจารณาใช้งาน Carbon‑Aware AI Scheduler ควรเริ่มจากการทำสำรวจและจัดประเภท workload ภายในองค์กร เพื่อประเมินว่า workload ใดเป็น deferrable (เลื่อนได้) และ workload ใดต้องการความต่อเนื่องทันที (real‑time/latency‑sensitive) ตัวอย่างงานที่มักเลื่อนได้ ได้แก่ การฝึกโมเดล (training jobs), การค้นหาพารามิเตอร์ (hyperparameter search), งาน batch inference ที่ไม่ต้องให้ผลทันที, งาน ETL/การเตรียมข้อมูลขนาดใหญ่, และงานประมวลผลสำหรับการทดสอบหรือ CI ที่สามารถรันในช่วงเวลาที่ไฟฟ้าหมุนเวียนสูงหรือราคาต่ำได้ การจัดทำ inventory ของงานโดยระบุ SLA, หน่วงเวลา (acceptable delay), dependency, และความสำคัญทางธุรกิจเป็นขั้นตอนแรกที่สำคัญ
แนะนำให้เริ่มด้วยการทดสอบในรูปแบบโปรเจ็กต์นำร่อง (pilot) ก่อนการปรับใช้ทั่วองค์กร โดยกำหนดกรอบเวลาและเกณฑ์การวัดผลที่ชัดเจน เช่น ระยะเวลานำร่อง 4–12 สัปดาห์ ครอบคลุมงานประเภทต่าง ๆ และขนาดตัวอย่างเพียงพอเพื่อให้ผลมีนัยสำคัญ ควรเก็บเมตริกหลักอย่างสม่ำเสมอ ได้แก่:
- CO2e per run (kgCO2e) — คำนวณจาก kWh ที่ใช้ × carbon intensity (kgCO2e/kWh)
- พลังงานรวม (kWh) และ ค่าไฟ (THB หรือสกุลเงินที่เกี่ยวข้อง) ต่อ job/ต่อเดือน
- ผลกระทบต่อ SLA — จำนวน job ที่ล่าช้า, เวลาหน่วงเฉลี่ย
- ประสิทธิภาพต้นทุน — ค่าใช้จ่ายต่อยูนิตงานและการเปรียบเทียบก่อน/หลัง
ตัวอย่างการวัดเชิงปฏิบัติ: หากงานฝึกโมเดลหนึ่งรันใช้พลังงาน 500 kWh และ carbon intensity ลดจาก 0.5 เป็น 0.2 kgCO2e/kWh เมื่อเลื่อนรันไปยังเวลาที่พลังงานหมุนเวียนมากขึ้น จะลดการปล่อยได้ 150 kgCO2e ต่อรัน (30%) นอกจากนี้ หากช่วงเวลาดังกล่าวมีค่าไฟต่ำกว่า 10% องค์กรอาจประหยัดค่าไฟควบคู่ไปด้วย — ข้อมูลเช่นนี้ใช้ประกอบการตัดสินใจเชิงธุรกิจได้ชัดเจน
การตั้งนโยบายงาน (policy) สำหรับ Scheduler ควรเป็นไปตามหลักปฏิบัติด้านการกำหนดลำดับความสำคัญและขอบเขตการเลื่อน เช่น:
- กำหนดกลุ่มงานที่ เลื่อนได้ทันที (e.g., nightly batch, long‑running training without hard deadline)
- ระบุกลุ่มงานที่ เลื่อนได้แต่ต้องการแจ้งเตือน (e.g., validation jobs ที่ส่งผลต่อ release cycle)
- กำหนดกลุ่มงานที่ ห้ามเลื่อน (mission‑critical, latency‑sensitive)
- ตั้งค่า max delay และ blackout windows (ชั่วโมงที่ห้ามเลื่อนตามเหตุผลทางธุรกิจ)
- เพิ่มเมตาดาต้า/แท็กสำหรับงาน เช่น business unit, environment, cost center, carbon sensitivity
การตรวจสอบผลลัพธ์ต้องมีระบบมอนิเตอร์และแดชบอร์ดที่รวบรวมข้อมูลแบบ near‑real time เพื่อให้ทีมดำเนินการปรับแต่งได้รวดเร็ว ประเด็นที่ควรติดตามอย่างต่อเนื่อง ได้แก่ การลด CO2e เป็นเปอร์เซ็นต์เมื่อเทียบกับ baseline, ค่าไฟที่ลดลง, จำนวน SLA violation จากการเลื่อนงาน, และ utilization ของทรัพยากรคลาวด์ แนะนำให้ตั้งการรายงานเป็นรายสัปดาห์/รายเดือน และเก็บข้อมูลเชิงเวลา (time series) เพื่อวิเคราะห์แนวโน้มและฤดูกาลของแรงไฟฟ้าหมุนเวียน
สุดท้าย แนวทางการผสานผลลัพธ์เข้ากับกลยุทธ์ความยั่งยืนโดยรวมควรเชื่อมต่อกับระบบ carbon accounting และนโยบายการจัดซื้อพลังงานหมุนเวียน องค์กรควร:
- บูรณาการข้อมูล CO2e จาก Scheduler เข้ากับระบบรายงานการปล่อยก๊าซเรือนกระจกขององค์กร เพื่อสนับสนุนการคำนวณ Scope 2 และการรายงานตามมาตรฐานสากล เช่น GHG Protocol, ISO 14064 และการรายงานต่อ CDP
- ใช้ผลจาก Scheduler เป็น input ในการตัดสินใจซื้อพลังงานหมุนเวียน (PPA/REC) หรือการจัดการภาระการใช้พลังงาน เพื่อเพิ่มสัดส่วนพลังงานทดแทนและลดปริมาณการชดเชยคาร์บอน (offset)
- กำหนด KPI ทาง ESG ที่ชัดเจน เช่น เป้าหมายลด CO2e จาก IT/ML ภายในปี, เปอร์เซ็นต์ของ workload ที่รันใน low‑carbon window, และการบันทึก savings ทั้งด้านคาร์บอนและค่าใช้จ่าย เพื่อนำไปสู่การรายงานต่อผู้ถือหุ้น
- ตั้งหน่วยงานหรือผู้รับผิดชอบ (sustainability owner) ที่ทำงานร่วมกับทีม ML/DevOps/Finance เพื่อกำกับดูแลการนำ Scheduler ไปใช้ ปรับนโยบาย และตรวจสอบผลลัพธ์อย่างต่อเนื่อง
สรุปคือ การนำ Carbon‑Aware AI Scheduler มาใช้ต้องอาศัยการสำรวจ workload อย่างเป็นระบบ, การทดลองในรูปแบบ pilot ที่มีการวัด CO2e และค่าใช้จ่ายเป็นระยะ, การวางนโยบายที่ชัดเจนสำหรับงานที่เลื่อนได้และข้อยกเว้น, รวมถึงการผสานผลลัพธ์เข้ากับการนับคาร์บอนและกลยุทธ์การจัดซื้อพลังงานหมุนเวียน เพื่อให้การลดการปล่อยก๊าซและการประหยัดต้นทุนเกิดขึ้นอย่างยั่งยืนและสอดคล้องกับเป้าหมาย ESG ขององค์กร
บทสรุป
Carbon‑Aware AI Scheduler เป็นเครื่องมือที่มีศักยภาพในการลดการปล่อยก๊าซเรือนกระจกและค่าไฟฟ้าสำหรับงานด้านการเรียนรู้ของเครื่อง (ML) ที่สามารถเลื่อนเวลาได้ โดยผู้ให้บริการคลาวด์ไทยระบุว่าการทดสอบเชิงปฏิบัติจริงสามารถลดคาร์บอนและค่าไฟได้สูงสุดถึงประมาณ 20% อย่างไรก็ตาม ผลลัพธ์ที่แท้จริงจะแตกต่างกันไปตามรูปแบบงาน — งานแบบแบตช์หรือการฝึกโมเดลที่เลื่อนเวลาได้มีโอกาสได้รับประโยชน์มากกว่า งานเรียลไทม์หรือมีข้อจำกัดด้าน latency — และยังขึ้นกับความแม่นยำของการพยากรณ์พลังงาน (เช่น ค่าความเข้มคาร์บอนของกริดเป็นรายชั่วโมง) รวมถึงความละเอียดของข้อมูลพยากรณ์และความถี่ในการปรับตารางงาน
องค์กรที่สนใจควรเริ่มจากการทดลองด้วยงานนำร่อง (pilot) ที่เป็นตัวแทนของเวิร์กโหลดจริง เพื่อเก็บข้อมูลเปรียบเทียบ (baseline) ทั้งด้านการปล่อยคาร์บอน (gCO2e/kWh), การใช้พลังงาน, เวลาในการประมวลผล และค่าใช้จ่ายไฟฟ้า จากนั้นกำหนดนโยบาย SLA ที่ชัดเจนเกี่ยวกับความยืดหยุ่นของเวลาในการประมวลผลและระดับผลการทำงานที่ยอมรับได้ (เช่น ระยะเวลาตอบสนองสูงสุดหรือคุณภาพโมเดล) พร้อมทั้งวัดผลตามมาตรฐานสากล เช่น GHG Protocol หรือ ISO 14064 และใช้เมตริกที่ยอมรับในวงการก่อนขยายการใช้งานเพื่อให้มั่นใจว่าผลประโยชน์ทางสิ่งแวดล้อมและเศรษฐกิจเป็นไปตามคาด
มุมมองอนาคตชี้ว่าโอกาสในการเพิ่มประสิทธิภาพจะขึ้นกับการปรับปรุงความแม่นยำของการพยากรณ์พลังงาน การขยายสัดส่วนพลังงานหมุนเวียนในกริด และการบูรณาการตัวจัดตารางกับระบบจัดการเวิร์กโหลด (orchestration) และนโยบายพลังงาน หากเทคโนโลยีพยากรณ์ดีกว่าและนโยบายสนับสนุน (เช่น ค่าวิชาชีพคาร์บอนหรือแรงจูงใจด้านพลังงานหมุนเวียน) ผลประโยชน์ทั้งด้านการลดคาร์บอนและการประหยัดค่าไฟมีแนวโน้มเพิ่มขึ้น แต่ต้องอาศัยการทดสอบเชิงปฏิบัติ ข้อกำหนด SLA ที่ชัดเจน และการวัดผลอย่างเป็นระบบก่อนการนำไปใช้ในวงกว้าง



