
RegTech Copilot — เครื่องมือ Generative‑AI ที่สัญญาว่าจะร่นเวลาในการร่าง ตรวจความสอดคล้อง และอัพเดตเอกสารกฎหมายภายในองค์กร — กลายเป็นหัวข้อร้อนในวงการกฎหมายและการกำกับดูแลในช่วงไม่กี่ปีที่ผ่านมา ด้วยความสามารถในการสร้างร่างสัญญา ปรับเนื้อหานโยบายความเป็นส่วนตัว และสแกนความเสี่ยงเชิงกฎระเบียบอย่างต่อเนื่อง เทคโนโลยีนี้เปิดโอกาสให้หน่วยงานภายในและทีมคอมพลายแอนซ์ทำงานได้รวดเร็วขึ้นและมีความสม่ำเสมอมากขึ้น แต่ในเวลาเดียวกันก็ยกประเด็นเชิงจริยธรรม ความรับผิดชอบ และความโปร่งใสที่หน่วยงานกำกับดูแลต้องการคำตอบอย่างชัดเจน
บทความนี้จะพาอ่านเชิงวิเคราะห์เกี่ยวกับ RegTech Copilot โดยครอบคลุมทั้งศักยภาพเชิงปฏิบัติการ เช่น กรณีใช้งานจริงในองค์กร วิธีลดต้นทุนและปรับปรุงความถูกต้องของเอกสาร รวมถึงความเสี่ยงที่มากับการพึ่งพาโมเดล Generative‑AI — ตั้งแต่การเกิด hallucination ข้อผิดพลาดในการตีความกฎหมาย ไปจนถึงคำถามเรื่องความรับผิดชอบทางกฎหมาย การตรวจสอบย้อนกลับ (auditability) และแนวทางที่หน่วยงานกำกับดูแลอาจต้องกำหนดเพื่อให้เกิดการยอมรับอย่างเป็นรูปธรรม ในบทนำและบทความต่อไป เราจะสำรวจหลักปฏิบัติที่เป็นไปได้ ข้อมูลตัวอย่าง และข้อเสนอเชิงนโยบายเพื่อให้ผู้บริหาร กฎหมาย และผู้กำกับดูแลมีกรอบคิดที่ชัดเจนในการตัดสินใจ
ภาพรวม: RegTech Copilot คืออะไร ทำไมถึงเกิดขึ้นตอนนี้
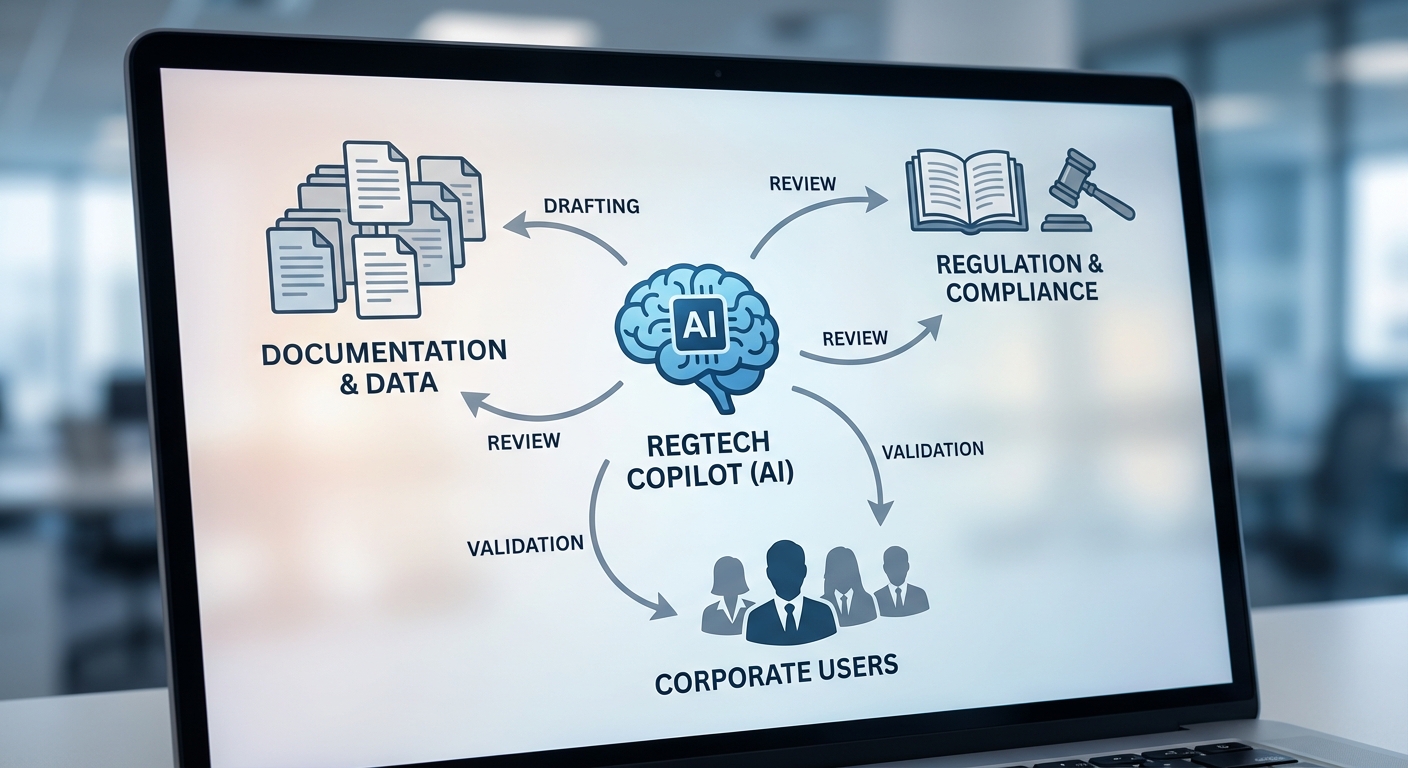
นิยามและบทบาทของ RegTech Copilot
RegTech Copilot หมายถึงระบบหรือเครื่องมือที่ผสานความสามารถของ Generative AI และโมเดลภาษาใหญ่ (Large Language Models, LLMs) เพื่อช่วยองค์กรในการเขียน ตรวจสอบ และให้คำอธิบายเกี่ยวกับเอกสารทางกฎหมายและการปฏิบัติตามกฎระเบียบ (compliance) ภายในองค์กรในรูปแบบที่เป็นภาษาธรรมชาติและสามารถปรับบริบทตามความเสี่ยงของธุรกิจได้ เครื่องมือนี้ไม่ได้เป็นเพียงชุดกฎ (rules-based engine) เหมือนระบบ Compliance แบบดั้งเดิม แต่ยังสามารถสังเคราะห์ข้อความ เสนอร่างสัญญา แปลความหมายข้อกฎหมายในบริบทเฉพาะ และระบุช่องโหว่ในการปฏิบัติตามที่ต้องดำเนินการเพิ่มเติมได้
ความแตกต่างสำคัญจากเครื่องมือ Compliance แบบเดิมคือ RegTech Copilot ให้ความสามารถเชิงภาษาธรรมชาติและการเรียนรู้เชิงบริบท แทนที่จะอาศัยการแม็ปกฎกับเท็มเพลตแบบตายตัว ซึ่งทำให้ผลลัพธ์มีความยืดหยุ่น ครอบคลุมกรณีที่ไม่เคยระบุไว้ล่วงหน้า และสามารถช่วยในการร่างเอกสารได้อย่างรวดเร็ว โดยยังสามารถเชื่อมต่อกับฐานข้อมูลกฎระเบียบภายใน-ภายนอกเพื่อตรวจสอบความสอดคล้องแบบเรียลไทม์
ปัจจัยเร่งการพัฒนา
การเกิดขึ้นของ RegTech Copilot ในช่วงเวลานี้มาจากปัจจัยเชิงโครงสร้างหลายประการที่ทำให้ความต้องการและความเป็นไปได้มาบรรจบกัน:
- ปริมาณและความซับซ้อนของข้อมูลกฎระเบียบเพิ่มขึ้น: ธุรกิจเผชิญกับกฎระเบียบที่ขยายตัวทั้งในระดับประเทศและข้ามพรมแดน เช่น ด้านข้อมูลส่วนบุคคล การต่อต้านการฟอกเงิน (AML) และความยั่งยืน (ESG) ส่งผลให้การติดตามและตีความข้อกำหนดต้องใช้ทรัพยากรมากขึ้น
- ความก้าวหน้าของ LLMs: โมเดลภาษารุ่นใหม่ (เช่น GPT‑4, LLaMA, Claude ฯลฯ) สามารถทำความเข้าใจบริบท สังเคราะห์ข้อความ และเรียนรู้รูปแบบภาษาทางกฎหมายได้ดีขึ้น ซึ่งทำให้การสร้างคำอธิบายเชิงกฎหมายและร่างเอกสารโดย AI เป็นไปได้จริงในปริมาณและคุณภาพที่ใช้งานได้
- ความต้องการ Automation และความกดดันด้านต้นทุน: ภาคการเงินและฝ่ายกฎหมายขององค์กรต้องการลดเวลาในการดำเนินการและค่าใช้จ่ายในการตรวจสอบเอกสารซ้ำซ้อน การใช้ Copilot ช่วยลดงานต้นน้ำ เช่น การร่างสัญญาเบื้องต้น การสแกนความเสี่ยง และการจัดทำรายงานการปฏิบัติตาม ทำให้ทีมงานสามารถมุ่งเน้นงานที่มีมูลค่าสูงกว่าได้
สถิติแนวโน้มตลาดและการนำ AI มาใช้
แนวโน้มการนำ AI มาใช้ในภาคการเงินและกฎหมายชี้ให้เห็นการเติบโตอย่างมีนัยสำคัญ โดยสำนักวิจัยหลายแห่งรายงานการลงทุนและการใช้งาน AI ในระดับที่เติบโตแบบสองหลัก ตัวอย่างเช่น รายงานจากหลายสถาบันพบว่า การลงทุนด้าน AI ในธนาคารและสถาบันการเงินเติบโตเฉลี่ยระหว่าง 20%–30% ต่อปี ในช่วงหลายปีที่ผ่านมา ซึ่งส่วนหนึ่งขับเคลื่อนโดยการใช้งานในงานด้านการปฏิบัติตามกฎระเบียบและการบริหารความเสี่ยง
ตัวอย่างการใช้งานเชิงปฏิบัติ ได้แก่ การใช้ AI ในการสแกนและวิเคราะห์สัญญา (contract review) เพื่อลดเวลาตรวจสอบลงจากหลายชั่วโมงเหลือไม่กี่นาที การสร้างแบบร่างเอกสารอัตโนมัติสำหรับขออนุญาตและรายงานต่อหน่วยงานกำกับดูแล และการตรวจจับความผิดปกติด้าน KYC/AML โดยระบบสามารถกรองเอกสารและให้ข้อเสนอแนะเชิงปฏิบัติได้แบบเรียลไทม์
ด้วยปัจจัยเหล่านี้ RegTech Copilot จึงไม่ได้เป็นเพียงเทรนด์ทางเทคโนโลยี แต่นับเป็นการตอบโจทย์เชิงกลยุทธ์ที่ช่วยให้องค์กรรับมือกับความซับซ้อนของกฎระเบียบได้อย่างมีประสิทธิภาพและคุ้มค่า—แต่พร้อมกันนั้นก็ยกคำถามใหม่ด้านความรับผิดชอบ การตรวจสอบย้อนกลับ และการยอมรับจากหน่วยงานกำกับดูแล ซึ่งจะเป็นประเด็นที่บทความนี้จะขยายความในหัวข้อถัดไป
เทคโนโลยีเบื้องหลัง: Generative AI, LLM และการตรวจสอบความถูกต้องของข้อกฎหมาย
สถาปัตยกรรมพื้นฐานของ RegTech Copilot
RegTech Copilot ในระดับองค์กรมักยึดสถาปัตยกรรมหลายชั้น (multi-layered architecture) ที่รวม Large Language Models (LLMs) กับชั้นข้อมูลภายในและระบบตรวจสอบอัตโนมัติ โดยโครงสร้างหลักประกอบด้วย: โมดูลการดึงข้อมูล (retrieval), โมเดลการสร้างข้อความ (generative LLM), เลเยอร์การตรวจสอบ (validation layers) และส่วนต่อประสานผู้ใช้พร้อมเวิร์กโฟลว์ของมนุษย์ (human-in-the-loop). การออกแบบเช่นนี้ช่วยให้ระบบไม่เพียงแค่ตอบคำถามเชิงภาษาธรรมชาติได้ดี แต่ยังสามารถอ้างอิงเอกสารภายในและแสดงที่มาที่ไป (provenance) เพื่อลดความเสี่ยงจากข้อผิดพลาดเชิงเนื้อหา.
เทคนิคสำคัญ ที่นำมาใช้งานรวมถึงการฝังตัวแทนความหมาย (embeddings) เพื่อทำ similarity search, vector databases สำหรับ retrieval-augmented generation (RAG), การปรับจูนโมเดล (fine-tuning หรือ instruction tuning) บนคอร์ปัสกฎหมายขององค์กร และ prompt engineering เพื่อควบคุมโทน น้ำหนักข้อกฎหมาย และรูปแบบคำตอบให้สอดคล้องกับนโยบายภายใน.
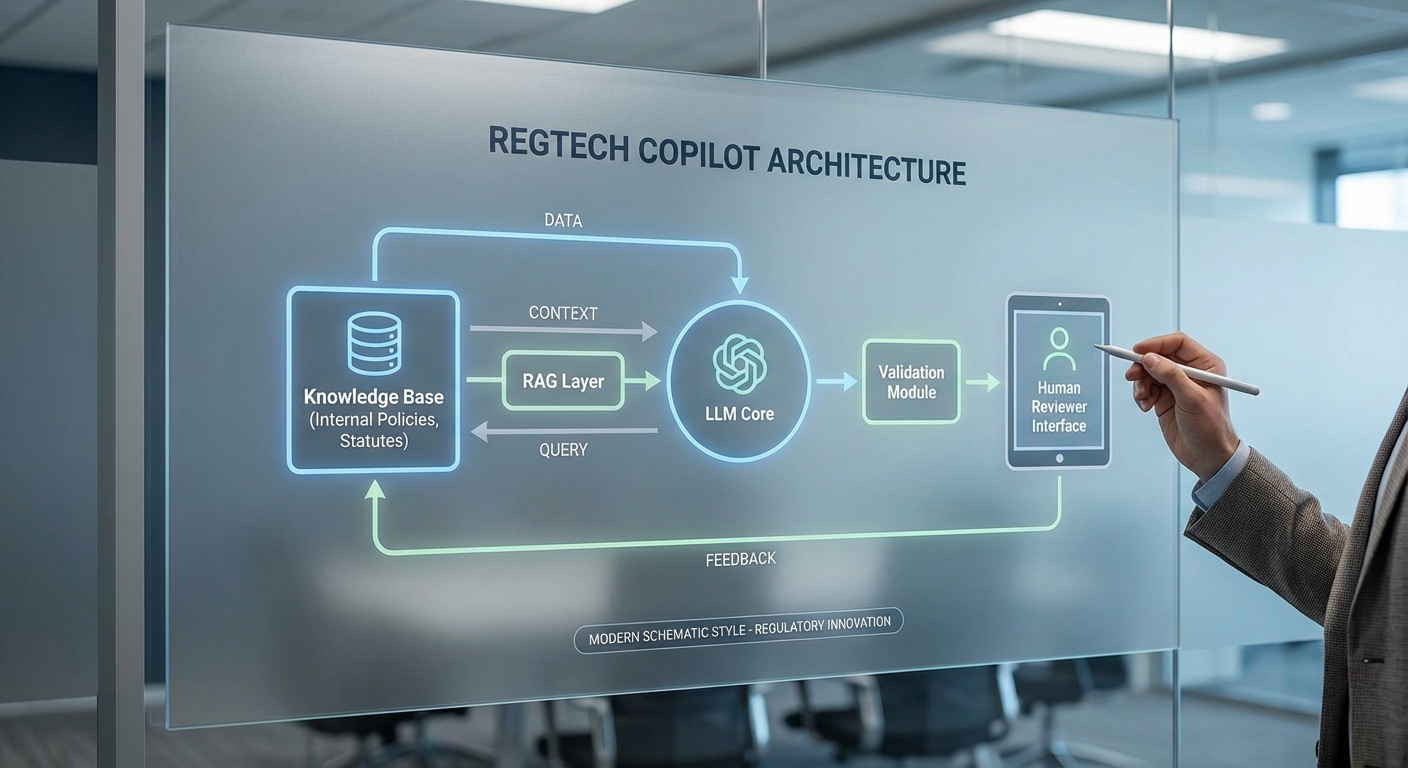
การใช้ RAG และฐานความรู้ภายในองค์กรเพื่อลด Hallucination
RAG (retrieval-augmented generation) เป็นหัวใจสำคัญของ Copilot ทางกฎหมาย เพราะช่วยให้ LLM สร้างคำตอบโดยอาศัยเอกสารที่ดึงมาจริงจากฐานความรู้ขององค์กร เช่น ข้อบังคับภายใน สัญญาตัวอย่าง นโยบายความเป็นส่วนตัว และคำตัดสินที่เกี่ยวข้อง กระบวนการทั่วไปคือ: แปลงข้อความในฐานความรู้เป็น embeddings → ดึงเอกสาร/สเตนช์ที่เกี่ยวข้องด้วยการค้นหาความคล้ายคลึง → ป้อนบริบทที่ดึงได้เข้าไปยัง LLM เพื่อให้โมเดลอ้างอิงหลักฐานแทนการสร้างเนื้อหาแบบลอย ๆ
งานวิจัยและกรณีศึกษาจากภาคอุตสาหกรรมชี้ว่า RAG สามารถลดอัตรา hallucination ได้อย่างมีนัยสำคัญ (ตัวอย่างเช่นการลดในช่วงประมาณ 30–70% ขึ้นกับคุณภาพของฐานข้อมูลและการออกแบบ retrieval). นอกจากนี้ การสร้างดัชนีแบบมีเมตาดาต้า (เช่น หมวดหมู่กฎหมาย วันที่ ผู้เขียน) และการกำหนดนโยบายการอนุญาตเข้าถึงช่วยเพิ่มความแม่นยำและความปลอดภัยของข้อมูลที่ถูกนำมาอ้างอิง.
กลไก Human‑in‑the‑Loop: Reviewer Workflows, Approval Gates และ Versioning
แม้เทคโนโลยีจะก้าวหน้า แต่การมีมนุษย์ร่วมตรวจสอบยังเป็นเงื่อนไขจำเป็นสำหรับการยอมรับจากหน่วยงานกำกับดูแล โดยสถาปัตยกรรมเชิงปฏิบัติการมักรวม:
- Reviewer workflows — ระบุระดับผู้ตรวจ เช่น ผู้ร่าง (junior counsel), ผู้ทบทวน (senior counsel), และกรรมการอนุมัติ พร้อมเครื่องมือกำกับเวลากรอบ SLA และการมอบหมายอัตโนมัติ
- Approval gates — เงื่อนไขที่ต้องผ่านก่อนเอกสารจะถือว่า "อนุมัติ" เช่น คะแนนความเชื่อมั่นของโมเดลเกินเกณฑ์, การยืนยัน citation ครบถ้วน, และการเซ็นรับรองโดยผู้ควบคุมทางกฎหมาย
- Versioning และ audit trail — บันทึกการเปลี่ยนแปลงทุกเวอร์ชันพร้อมเมตาดาต้า (ผู้แก้ไข เวลา เหตุผลการแก้ไข) และการเก็บลายเซ็นดิจิทัลหรือแฮชของเอกสารเพื่อรองรับการตรวจสอบย้อนหลัง
ตัวอย่างเชิงปฏิบัติ: องค์กรสามารถออกแบบระบบให้ข้อความที่สร้างโดย Copilot จะถูกทำเครื่องหมายว่าเป็น "ร่างอัตโนมัติ" และจะไม่สามารถส่งให้ลูกค้าหรือลงนามได้จนกว่า senior counsel จะอนุมัติผ่าน approval gate ซึ่งลดความเสี่ยงด้านความรับผิดชอบและช่วยให้งานสอดคล้องกับมาตรฐานภายใน.
เทคนิคการตรวจสอบเชิงกฎหมาย: Consistency, Citation Verification และ Provenance Tracking
เพื่อให้ผลลัพธ์มีความน่าเชื่อถือ ระบบตรวจสอบของ RegTech Copilot มักประกอบด้วยหลายชั้นดังนี้:
- Consistency checks — ตรวจสอบความสอดคล้องภายในเอกสาร เช่น คำนิยามตัวแปร จำนวนวันในการบอกกล่าว การอ้างอิงมาตรา/ข้อที่ไม่ขัดกัน โดยใช้กฎเชิงสัญลักษณ์ (rule-based) และเทคนิคการจับคู่เชิงตรรกะ (logical validation)
- Citation verification — ยืนยันว่าข้อความที่อ้างอิงมีอยู่จริงในเอกสารต้นฉบับ ตรวจสอบว่าเลขมาตรา/หน้าที่กล่าวถึงตรงกัน ผ่านการแมป snippet-to-source และคำนวณ similarity score ระหว่างข้อความที่สร้างกับข้อความต้นทาง
- Provenance tracking — บันทึกที่มาของทุกบรรทัดที่โมเดลสร้างขึ้น ได้แก่ ID ของแหล่งข้อมูล ช่วงตำแหน่ง (offset) ของข้อความในเอกสารต้นฉบับ และค่าแฮชของสแต็กข้อมูลที่นำเข้า เพื่อให้สามารถย้อนกลับไปตรวจสอบได้แบบไม่เปลี่ยนแปลง
การนำมาตรวัดเชิงตัวเลขเข้ามาช่วย เช่น hallucination rate, citation accuracy, precision/recall ของมาตราอ้างอิง และเวลาที่ใช้ในการทบทวน (time-to-review) ช่วยให้องค์กรสามารถวัดประสิทธิผลของ Copilot ได้อย่างชัดเจน — ในหลายกรณีองค์กรรายงานการลดเวลาในการเตรียมเอกสารเชิงกฎหมายลงได้ถึง 40–60% เมื่อเทียบกับเวิร์กโฟลว์ที่ไม่มีการใช้ RAG และการตรวจสอบอัตโนมัติ
สุดท้าย ระบบที่ดีจะผสานทั้งการฝังตัวเชิงกฎหมาย (fine-tuning บนคอร์ปัสขององค์กร), การออกแบบ prompt ที่ชัดเจนและคาดเดาได้ (prompt engineering), และเลเยอร์การตรวจสอบหลายชั้น ทั้งอัตโนมัติและมนุษย์ เพื่อสร้างสมดุลระหว่างความรวดเร็วและความรับผิดชอบทางกฎหมาย — ซึ่งเป็นหัวใจในการสร้างความเชื่อมั่นต่อหน่วยงานกำกับดูแลและผู้มีส่วนได้เสียในองค์กร.
กรณีใช้งานและประโยชน์เชิงธุรกิจ
กรณีใช้งานและประโยชน์เชิงธุรกิจ
RegTech Copilot ที่ขับเคลื่อนด้วย Generative‑AI สามารถนำไปประยุกต์ใช้ได้ในหลายกรณีที่มีความสำคัญเชิงธุรกิจ ตั้งแต่การร่างและแก้ไขสัญญา (drafting and redlining) การปรับปรุงนโยบายภายใน ไปจนถึงการตรวจสอบความสอดคล้องกับกฎระเบียบข้ามประเทศ และการตอบคำขอจากหน่วยงานกำกับดูแล การใช้งานเหล่านี้ไม่เพียงแต่ช่วยลดระยะเวลาทำงานเชิงปริมาณเท่านั้น แต่ยังเพิ่มความสม่ำเสมอของเนื้อหา สร้าง audit trail สำหรับการตรวจสอบย้อนหลัง และช่วยให้ทีมกฎหมายเปลี่ยนบทบาทจากงานเชิงปฏิบัติไปสู่การให้คำปรึกษาเชิงกลยุทธ์มากขึ้น
การร่างสัญญาและการทำ Redlining: หนึ่งในกรณีใช้งานที่พบผลลัพธ์ชัดเจนที่สุดคือการร่างเอกสารเบื้องต้นและการแก้ไขข้อกำหนดระหว่างฝ่าย (redlining) โดยโมเดลสามารถสร้างร่างมาตรฐานสำหรับสัญญาประเภทต่าง ๆ (เช่น NDA, Master Service Agreement, SLA) และเสนอข้อแก้ไขที่สอดคล้องกับนโยบายองค์กร ในหลายองค์กรพบว่า ลดเวลาร่างเอกสารเบื้องต้นได้หลายสิบเปอร์เซ็นต์ — ตัวอย่างเช่น หากการร่างด้วยมือโดยทั่วไปใช้เวลา 6–12 ชั่วโมง การใช้ Copilot อาจลดเวลาส่วนนี้เหลือเพียง 1–3 ชั่วโมง (ลดได้ประมาณ 50–80%) ซึ่งหากคิดเป็นค่าใช้จ่ายแรงงานและค่าเสียโอกาส จะเท่ากับการลดต้นทุนต่อสัญญาได้หลายพันถึงหลายหมื่นบาท ขึ้นกับเรตชั่วโมงของทีมกฎหมาย
การตรวจสอบความสอดคล้องอัตโนมัติข้ามเขตอำนาจ (Automated compliance checks across multiple jurisdictions): RegTech Copilot สามารถรวมฐานข้อมูลกฎระเบียบจากหลายประเทศ และใช้ NLP/semantic search ในการแม็ปข้อกำหนดที่เกี่ยวข้องกับเนื้อหาเอกสาร ผลที่ได้คือการสแกนความเสี่ยงเชิงกฎเกณฑ์และการระบุช่องว่างที่อาจเกิดขึ้นได้รวดเร็วกว่าเดิมมาก ในการใช้งานจริง องค์กรที่มีธุรกรรมข้ามพรมแดนรายงานว่าเวลาที่ใช้ในการตรวจสอบรายการความเสี่ยงเชิงกฎระเบียบเติบโตจากเป็นสัปดาห์ลงมาสู่ระดับชั่วโมงถึงวัน (ตัวเลขตัวอย่าง: ลดเวลาในการตรวจสอบได้ 60–90%) ซึ่งช่วยให้การตัดสินใจเชิงธุรกิจเป็นไปอย่างทันการณ์และลดความเสี่ยงด้านค่าปรับหรือการดำเนินคดี
การตอบคำถามจากหน่วยงานกำกับดูแล (Regulator requests): เมื่อหน่วยงานกำกับขอข้อมูลหรือขอชี้แจง Copilot สามารถจัดทำร่างคำตอบ รวบรวมเอกสารประกอบ และสร้างรายการอ้างอิงที่ชัดเจนพร้อมทั้งแสดงแหล่งที่มาของข้อมูล ทำให้ เพิ่มความเร็วในการตอบ regulator inquiries จากระดับสัปดาห์ลงมาสู่ระดับวันหรือไม่กี่ชั่วโมงในเคสปกติ นอกจากนี้ระบบยังสามารถสร้าง log ของคำตอบและการแก้ไขเพื่อใช้เป็นหลักฐานในการสื่อสารกับ regulator ซึ่งช่วยลดความเสี่ยงจากการตอบข้อมูลที่ไม่สอดคล้องหรือขาดแคลนข้อมูล
นอกเหนือจากเวลาและต้นทุนที่ลดลงแล้ว ประโยชน์เชิงธุรกิจที่สำคัญอื่น ๆ ได้แก่:
- ลดภาระงานซ้ำซ้อน: งานเช่นการดึงข้อมูลซ้ำ การเทียบข้อกำหนด และการตรวจทานเบื้องต้นสามารถอัตโนมัติ ให้ทีมโฟกัสที่การตัดสินใจเชิงกลยุทธ์มากขึ้น
- ขยายความสามารถของทีมกฎหมาย: แต่ละคนสามารถรองรับงานได้มากขึ้น — องค์กรรายงานการเพิ่ม productivity ของทีมกฎหมายเป็น 2–5 เท่าในงานที่เป็นมาตรฐานและเชิงปริมาณ
- การควบคุมคุณภาพและความสม่ำเสมอ: เทมเพลตและกฎการเขียนที่ฝังในระบบช่วยให้เอกสารทุกฉบับรักษามาตรฐานเดียวกัน ลดความเสี่ยงจากความคลาดเคลื่อนทางภาษาและเนื้อหา
- ประหยัดค่าใช้จ่ายโดยรวม: เมื่อรวมเวลาแรงงานที่ลดลง การลดความเสี่ยงค่าปรับ และการเพิ่มความเร็วในการออกสินค้า/บริการ ผลลัพธ์ทางการเงินอาจสะท้อนเป็นการลดต้นทุนรวมในระดับเปอร์เซ็นต์ของค่าใช้จ่ายด้านกฎหมาย (เช่น ลดได้ 10–40% ขึ้นกับสเกลและประเภทงาน)
สรุปแล้ว RegTech Copilot ให้ประโยชน์เชิงธุรกิจที่จับต้องได้ทั้งในแง่ของเวลา ต้นทุน และความสามารถทางปฏิบัติการ อย่างไรก็ตามเพื่อให้เกิดผลลัพธ์ที่ปลอดภัยและยอมรับได้โดยหน่วยงานกำกับ ควรผสานกระบวนการตรวจสอบโดยผู้เชี่ยวชาญ (human-in-the-loop) และการเก็บบันทึกการตัดสินใจอย่างเป็นระบบเพื่อรองรับประเด็นความรับผิดชอบและการตรวจสอบภายหลัง
ความท้าทายด้านความรับผิดชอบ (Liability) — ใครต้องรับผิดเมื่อเกิดข้อผิดพลาด
ความท้าทายด้านความรับผิดชอบ (Liability) — ใครต้องรับผิดเมื่อเกิดข้อผิดพลาด
เมื่อองค์กรนำ RegTech Copilot ที่ขับเคลื่อนด้วย Generative‑AI มาใช้เขียนหรือประเมินความสอดคล้องของเอกสารกฎหมาย ความเสี่ยงด้านความรับผิดชอบจะขยายตัวทั้งในมิติทางแพ่ง ทางอาญา และทางจริยธรรม โดยเฉพาะกรณีที่โมเดลสร้างคำตอบที่ไม่ถูกต้อง (hallucination) หรือแปลความกฎหมายผิดพลาด งานวิจัยและการทดลองหลายฉบับรายงานว่าอัตรา hallucination ของ LLM อาจอยู่ในช่วงตั้งแต่หลักหน่วยถึงหลักสิบเปอร์เซ็นต์ ขึ้นกับโดเมนและการปรับจูน ซึ่งมีผลโดยตรงต่อความเสี่ยงที่องค์กรจะได้รับคำแนะนำผิดพลาดและตามมาด้วยความเสียหายทางกฎหมายหรือการถูกปรับจากหน่วยงานกำกับดูแล

ความรับผิดทางแพ่ง มักเป็นรูปแบบที่พบได้บ่อยที่สุดเมื่อคำแนะนำของ Copilot ทำให้เกิดความเสียหายทางการเงิน เช่น สัญญาที่ร่างตามคำแนะนำส่งผลให้เกิดความรับผิดหรือการสูญเสียทางการค้า ฝ่ายที่ได้รับผลกระทบอาจฟ้องเรียกค่าเสียหายจากองค์กรผู้ใช้งานหรือในบางกรณีฟ้องผู้พัฒนา/ผู้ให้บริการได้ หากมีคำรับประกัน (warranty) หรือการตลาดที่ให้ความเชื่อมั่นผิดพลาด นอกจากนี้การจัดสรรความรับผิดในสัญญาระหว่าง vendor, integrator และผู้ใช้งานภายในองค์กรจะเป็นตัวกำหนดว่าใครต้องชดใช้ เมื่อเกิดเหตุการณ์ เช่น การกำหนด limits of liability, caps, และข้อยกเว้นสำหรับความบกพร่องที่รู้เท่าไม่ถึงการณ์ จะถูกนำมาใช้ต่อสู้ทางแพ่ง
ความรับผิดทางอาญา อาจเกิดขึ้นในกรณีที่คำแนะนำของ Copilotก่อให้เกิดการละเมิดกฎหมายร้ายแรง เช่น การช่วยเหลือให้หลบเลี่ยงภาษี หรือการละเมิดกฎคุ้มครองข้อมูลส่วนบุคคลจนเข้าข่ายความผิดร้ายแรง ในหลายเขตอำนาจศาล หน่วยงานกำกับดูแลอาจตั้งคำถามต่อความรับผิดชอบของคณะกรรมการบริหารหรือผู้บริหารระดับสูงหากไม่มีมาตรการดูแลที่เหมาะสม (เช่น ขาดการกำกับดูแลของมนุษย์) สถานการณ์เหล่านี้ชี้ให้เห็นว่าแม้ข้อผิดพลาดจะมาจากระบบ AI แต่ผู้คนในห่วงโซ่อุปทานและผู้ใช้งานยังอาจต้องรับผิดตามกฎหมายอาญาในบางกรณี
ความรับผิดทางจริยธรรม เกี่ยวข้องกับความคาดหวังของสังคม หน่วยงานกำกับดูแล และลูกค้า หาก Copilot ให้คำแนะนำที่มีอคติ (bias), เปิดเผยข้อมูลลับโดยไม่ได้ตั้งใจ หรือส่งผลให้บุคคลถูกเลือกปฏิบัติ องค์กรจะเผชิญความเสื่อมเสียชื่อเสียงซึ่งอาจนำไปสู่การสูญเสียทางเศรษฐกิจระยะยาว แม้จะไม่ถูกฟ้องทางกฎหมายก็ตาม
การจัดสรรความรับผิดระหว่างผู้เกี่ยวข้องต้องพิจารณาอย่างรอบคอบและเป็นระบบ โดยทั่วไปแบ่งได้เป็นกลุ่มหลักดังนี้
- ผู้พัฒนา (Vendor) — รับผิดชอบด้านความถูกต้องของโมเดลตามขอบเขตที่ระบุในสัญญา เช่น การให้การรับประกัน (warranties) ว่าโมเดลได้ผ่านการทดสอบในโดเมนที่เกี่ยวข้อง และการรับประกันว่ามีการรักษาความปลอดภัยของซอฟต์แวร์
- Integrator/ระบบงาน (SI) — รับผิดชอบต่อการติดตั้ง ปรับแต่งการทำงาน (prompt engineering, fine‑tuning) และการบูรณาการกับ workflow ขององค์กร รวมถึงความรับผิดชอบในกรณีที่การตั้งค่าหรือการปรับแต่งทำให้เกิดความผิดพลาด
- ผู้ให้บริการคลาวด์ — โดยมากรับผิดชอบระดับโครงสร้างพื้นฐานและความมั่นคงของแพลตฟอร์ม (availability, security) ภายใต้โมเดลการรับผิดชอบร่วมกัน (shared responsibility model) โดยมักจะปฏิเสธความรับผิดต่อผลลัพธ์เชิงเนื้อหา
- หน่วยงานภายในองค์กร (Deployers/End‑users) — รับผิดชอบด้านการตัดสินใจขั้นสุดท้าย การทวนสอบ และการกำกับดูแล เนื่องจาก Copilot เป็นเครื่องมือสนับสนุน การตัดสินใจที่ผิดพลาดที่ไม่ได้ผ่านการตรวจสอบของมนุษย์อาจทำให้องค์กรต้องรับผิดชอบเป็นหลัก
เพื่อจัดการความเสี่ยงอย่างมีประสิทธิภาพ ควรนำมาตรการต่อไปนี้มาบังคับใช้ในทุกขั้นตอนของการนำ AI มาใช้
- Human oversight (มนุษย์เป็นผู้ตรวจสอบขั้นสุดท้าย) — กำหนดระดับการกำกับดูแลที่ชัดเจน เช่น กำหนดว่าเอกสารเชิงกฎหมายใดต้องมีการทบทวนโดยทนายความที่ได้รับอนุญาตก่อนนำไปใช้จริง และกำหนด workflows ที่บังคับให้มีการอนุมัติโดยมนุษย์สำหรับคำแนะนำที่เสี่ยงสูง
- Clear audit trails — บันทึก prompt, เวอร์ชันของโมเดล, ผลลัพธ์, ผู้ใช้ที่เรียกใช้ และการกระทำต่อเนื่องในระบบอย่างเป็นระบบ (timestamps, hashes) เพื่อนำเสนอเป็นหลักฐานเมื่อเกิดข้อพิพาท และรองรับการตรวจสอบจากหน่วยงานกำกับดูแล ตัวอย่างการปฏิบัติที่ดีรวมถึงการเก็บ log ไว้อย่างน้อยตามระยะเวลาที่กฎหมายกำหนดและการเก็บ metadata ของคำตอบ
- Contractual warranties and indemnities — ต่อรองข้อสัญญาที่ชัดเจนระหว่างองค์กรกับ vendor/integrator/คลาวด์ เช่น ข้อรับประกันเรื่องคุณภาพข้อมูล การรับประกันการปรับแต่งตามกฎหมาย (domain‑specific compliance), การชดใช้ค่าเสียหาย (indemnity) สำหรับกรณีที่ความผิดพลาดมาจากความบกพร่องของซอฟต์แวร์ รวมถึงการกำหนดข้อยกเว้นสำหรับเหตุสุดวิสัยและการจำกัดความรับผิด (caps, carve‑outs for gross negligence)
- Continuous monitoring and validation — ตั้งมาตรการทดสอบหลังการใช้งาน (post‑deployment testing), การตรวจวัดอัตรา hallucination ในเวิร์กโฟลว์จริง และการประเมินผลกระทบที่เกี่ยวข้องกับกฎหมายอย่างสม่ำเสมอ
- Insurance and financial risk allocation — พิจารณาประกันความรับผิดทางวิชาชีพ (professional indemnity) และประกันไซเบอร์ที่ครอบคลุมความเสียหายจากคำแนะนำของ AI รวมทั้งการกำหนดกลไกทางการเงิน (escrow, performance bonds) ในสัญญาเมื่อจำเป็น
สรุปแล้ว ความรับผิดชอบเมื่อนำ RegTech Copilot มาใช้ไม่สามารถมองเป็นปัญหาของฝ่ายใดฝ่ายหนึ่งเพียงลำพัง แต่เป็นเรื่องของการออกแบบ governance, สัญญาทางกฎหมาย และกระบวนการปฏิบัติการร่วมกัน ระหว่างผู้พัฒนา integrator ผู้ให้บริการคลาวด์ และหน่วยงานภายในองค์กร การรวมมาตรการเชิงเทคนิค กฎหมาย และจริยธรรมเข้าด้วยกันจึงเป็นวิธีเดียวที่ช่วยลดความเสี่ยงและสร้างความเชื่อมั่นต่อหน่วยงานกำกับดูแลได้อย่างยั่งยืน
การยอมรับจากหน่วยงานกำกับดูแล: มาตรฐาน นโยบาย และการตรวจสอบ
การยอมรับจากหน่วยงานกำกับดูแล: มาตรฐาน นโยบาย และการตรวจสอบ
การนำ RegTech Copilot ซึ่งเป็นระบบ Generative‑AI มาใช้ในการเขียนและตรวจความสอดคล้องของเอกสารกฎหมายภายในองค์กร อยู่ภายใต้กรอบกฎหมายและแนวทางกำกับดูแลที่กำลังถูกพัฒนาและปรับใช้ทั้งในระดับสากลและระดับประเทศ ทั้งนี้กรอบสำคัญที่มีผลโดยตรงได้แก่ EU AI Act (จัดประเภทความเสี่ยงและข้อจำกัดสำหรับระบบ AI ที่มีความเสี่ยงสูง), GDPR (ข้อกำหนดด้านการคุ้มครองข้อมูลส่วนบุคคลและการประเมินผลกระทบข้อมูล), แนวทางเฉพาะอุตสาหกรรมจากหน่วยงานเช่น FCA (สหราชอาณาจักร), SEC (สหรัฐฯ) และ MAS (สิงคโปร์) รวมถึงมาตรฐานความน่าเชื่อถืออย่าง NIST AI Risk Management Framework ที่เน้นการจัดการความเสี่ยงอย่างเป็นระบบ การปฏิบัติตามข้อกำหนดเหล่านี้ไม่เพียงแต่เป็นเงื่อนไขทางกฎหมาย แต่ยังเป็นตัวชี้วัดความพร้อมเชิงองค์กรเมื่อนำ AI มาใช้ในงานกฎหมายและการปฏิบัติตามข้อบังคับ
หน่วยงานกำกับทั้งหมดให้ความสำคัญต่อข้อกำหนดด้านการอธิบายได้ (explainability), การตรวจสอบย้อนหลังได้ (auditability) และการตรวจสอบแหล่งที่มาของข้อมูล (data provenance) ในบริบทของ RegTech Copilot โดยเฉพาะเมื่อระบบมีบทบาทในการร่างหรือยืนยันเนื้อหาเชิงกฎหมาย องค์กรที่ใช้ระบบเหล่านี้จึงมักถูกคาดหวังให้สามารถ:
- อธิบายกระบวนการตัดสินใจ — ระบุได้ว่าโมเดลให้คำแนะนำหรือร่างเนื้อหาอย่างไร และอ้างอิงกฎ ข้อกฎหมาย หรือชุดข้อมูลใดบ้าง
- เก็บบันทึกการสืบย้อน — มี audit trail ที่บันทึกรุ่นของโมเดล ข้อมูลฝึกสอน การตั้งค่าพารามิเตอร์ และการแก้ไขโดยมนุษย์
- พิสูจน์แหล่งที่มาของข้อมูล — ระบุได้ว่าข้อมูลเข้า (input) และข้อมูลอ้างอิง (reference materials) มาจากแหล่งที่น่าเชื่อถือ ถูกต้องตามสิทธิ์การใช้ และไม่ละเมิดข้อจำกัดของ GDPR หรือกฎหมายข้อมูลอื่น
ในเชิงปฏิบัติ หน่วยงานกำกับมักออกแนวทางการตรวจสอบระบบ AI ที่ครอบคลุมทั้งขั้นตอนก่อนนำไปใช้ (pre‑deployment) และการติดตามหลังใช้งาน (ongoing monitoring) ตัวอย่างการปฏิบัติที่เห็นได้บ่อย ได้แก่:
- Pre‑deployment assessment — การจัดประเภทความเสี่ยง (risk classification), การทำ Data Protection Impact Assessment (DPIA) ตาม GDPR เมื่อต้องประมวลผลข้อมูลส่วนบุคคลระดับสูง, การตรวจสอบ bias และการทดสอบความถูกต้องของข้อเสนอแนะทางกฎหมายผ่านชุดทดสอบที่จำลองสถานการณ์จริง รวมถึงการจัดทำเอกสารความเสี่ยงและแผนลดความเสี่ยง (risk mitigation plan)
- Ongoing monitoring — การตรวจจับ drift ของโมเดล การทวนสอบผลลัพธ์แบบเป็นระยะ การทดสอบย้อนกลับ (back‑testing) และการตั้งค่าค่า KPI ด้านความถูกต้องและความสอดคล้อง นอกจากนี้ยังรวมถึงกระบวนการแจ้งเตือนและการรายงานเหตุการณ์เมื่อผลลัพธ์ของระบบส่งผลต่อการตัดสินใจเชิงกฎหมาย
- Governance และ third‑party oversight — แนวทางจากหน่วยงานอย่าง MAS และ FCA เน้นการควบคุมซัพพลายเชนของโมเดล รวมทั้งข้อกำหนดในการตรวจสอบผู้ให้บริการ AI ภายนอกและการจัดทำสัญญาที่ชัดเจนเกี่ยวกับความรับผิดชอบ
หน่วยงานกำกับจะประเมินไม่เพียงแค่เทคนิคของโมเดล แต่ยังคำนึงถึงโครงสร้างการกำกับดูแลภายในองค์กร เช่น นโยบายความรับผิดชอบ (accountability), กลไกการกำกับดูแลโดยมนุษย์ (human‑in‑the‑loop), การฝึกอบรมผู้ใช้ และกระบวนการทางกฎหมาย/นโยบายภายในที่รองรับการใช้ AI ในการร่างหรือยืนยันเอกสาร ตัวอย่างเช่น EU AI Act อาจกำหนดข้อจำกัดเพิ่มเติมสำหรับระบบที่จัดเป็นความเสี่ยงสูง ขณะที่ NIST AI RMF สนับสนุนการวัดผลและการสื่อสารความเสี่ยงเป็นประจำเพื่อให้หน่วยงานภายนอกสามารถตรวจสอบได้
สรุปคือ หน่วยงานกำกับต้องการความโปร่งใส สามารถตรวจสอบได้ และความสามารถในการควบคุมความเสี่ยงอย่างต่อเนื่องสำหรับ RegTech Copilot องค์กรที่เตรียมเอกสารครบถ้วน ได้แก่ model cards, data lineage, DPIA reports, test results และแผนการติดตาม จะมีโอกาสได้รับการยอมรับจาก regulator สูงกว่า โดยเฉพาะเมื่อสามารถแสดงให้เห็นถึงการทดสอบก่อนใช้งานและการติดตามผลแบบเรียลไทม์ตามแนวทางที่ regulator แนะนำ
ความเป็นส่วนตัวและความปลอดภัยของข้อมูล — เส้นเลือกระหว่างข้อมูลภายในกับโมเดลกลาง
ความเป็นส่วนตัวและความปลอดภัยของข้อมูล — เส้นเลือกระหว่างข้อมูลภายในกับโมเดลกลาง
ในบริบทของ RegTech Copilot ที่ใช้ Generative‑AI เพื่อช่วยเขียนและตรวจสอบเอกสารกฎหมาย ความเสี่ยงด้านความเป็นส่วนตัวและการรั่วไหลของข้อมูล (data leakage) เป็นประเด็นศูนย์กลาง เนื่องจากเอกสารกฎหมายมักประกอบด้วยข้อมูลที่มีความลับสูง เช่น ข้อมูลลูกค้า ข้อมูลภายในบริษัท และข้อสรุปทางกฎหมายที่เป็นกรรมสิทธิ์ การเรียกใช้งาน LLM ผ่านผู้ให้บริการคลาวด์สาธารณะหากไม่มีมาตรการป้องกันที่เข้มงวด อาจเกิดกรณีข้อมูลประจำตัวหรือข้อความสำคัญถูกเก็บในแคช ถูกฝังเป็น embeddings หรือถูกใช้เป็นข้อมูลฝึก (training/fine‑tuning) โดยไม่ได้ตั้งใจ ซึ่งเพิ่มความเสี่ยงทั้งเชิงเทคนิคและเชิงกฎหมาย การประเมินความเสี่ยงอย่างเป็นระบบ (DPIA) จึงควรเป็นขั้นตอนเริ่มต้นก่อนนำระบบไปใช้งานจริง
การป้องกัน leakage เมื่อเรียกใช้ LLM ผ่านคลาวด์สาธารณะ ควรผนวกมาตรการเชิงสถาปัตยกรรมและการดำเนินงาน เช่น การใช้ Private Endpoints/VPC, Dedicated Instances หรือโซลูชันแบบ on‑premise สำหรับข้อมูลที่มีความไวสูง รวมทั้งการเปิดใช้งานการจัดการคีย์โดยลูกค้า (Customer‑Managed Keys) และ HSM สำหรับการเข้ารหัส ทั้งในขณะส่งข้อมูล (TLS) และข้อมูลเมื่อจัดเก็บ (AES‑256 หรือมาตรฐานเทียบเท่า) นอกจากนี้ ต้องคำนึงถึงความเสี่ยงจาก model inversion และ prompt injection ที่ทำให้ข้อมูลภายในหลุดออกมาผ่านการตอบของโมเดล จึงควรใช้การทำ input/output sanitization และการจำกัดบริบท (context windows) ที่ส่งให้โมเดล
แนวทางปฏิบัติด้านข้อมูลและการฝึกสอนโมเดล — เพื่อจำกัดการเปิดเผยข้อมูล ควรยึดหลักสำคัญดังต่อไปนี้:
- Data minimization: ส่งเฉพาะข้อมูลที่จำเป็นต่อการตอบคำถามหรือการประมวลผล หลีกเลี่ยงการส่งเอกสารฉบับเต็มหากสามารถส่งเฉพาะสรุปหรือ metadata ได้
- การทำ pseudonymization/anonymization: กำจัดหรือลดข้อมูลระบุตัวบุคคลก่อนส่งให้โมเดล โดยระวังความเสี่ยงการย้อนกลับ (re‑identification)
- Encryption & KMS: เข้ารหัสทั้งข้อมูลต้นทางและ embeddings ใช้ Customer‑Managed Keys และ HSM เพื่อควบคุมคีย์เข้ารหัส
- Secure retrieval: ใช้ Retrieval‑Augmented Generation (RAG) ที่แยกการค้นคืนเอกสารจากการเรียกโมเดล โดยให้ระบบค้นหาเอกสารที่ได้รับอนุญาตเท่านั้นและส่งเฉพาะผลที่ผ่านการกรอง
- Differential privacy สำหรับ training/fine‑tuning: เมื่อต้องฝึกหรือ fine‑tune ควรใช้เทคนิคเช่น DP‑SGD หรือการรวม noise ระดับที่เหมาะสม เพื่อลดความเสี่ยงที่ข้อมูลเฉพาะบุคคลจะถูกกู้คืนจากโมเดล แต่ต้องยอมรับ trade‑off ระหว่างความเป็นส่วนตัวกับประสิทธิภาพของโมเดล
การจัดเก็บ embeddings และ cache ควรแยกออกจากฐานข้อมูลเอกสารหลัก โดยใช้ namespaces ที่มีการควบคุมการเข้าถึงอย่างเข้มงวด และเข้ารหัสไฟล์ embeddings ด้วยคีย์ที่แยกจากฐานข้อมูลทั่วไป นอกจากนี้ควรออกแบบระบบให้สามารถลบหรือระงับข้อมูล (including embeddings and derived artifacts) ตามคำขอของผู้เกี่ยวข้องได้อย่างมีประสิทธิภาพ เพราะการลบข้อมูลต้นทางไม่เท่ากับการลบข้อมูลที่ถูกแอบฝังลงในโมเดล — ในกรณีที่มีการนำข้อมูลไปใช้ฝึกจริง ต้องมีนโยบายที่ชัดเจนว่าอนุญาตให้ใช้ข้อมูลใดสำหรับ fine‑tuning บ้าง และมีการบันทึกการยินยอมหรือภาระหน้าที่ตามสัญญา
ข้อกำหนดด้าน GDPR และกฎหมายคุ้มครองข้อมูลอื่นๆ — การใช้ RegTech Copilot อยู่ภายใต้กรอบกฎหมายคุ้มครองข้อมูลส่วนบุคคล (เช่น GDPR) ซึ่งกำหนดหลักการสำคัญ ได้แก่ ความชอบด้วยกฎหมายและความโปร่งใส, จำกัดวัตถุประสงค์, data minimization, accuracy, retention restriction และความปลอดภัย การนำข้อมูลผู้ใช้ไปใช้ฝึกโมเดลโดยไม่ได้รับพื้นฐานทางกฎหมายที่ชัดเจนอาจนำไปสู่บทลงโทษ ทางปฏิบัติองค์กรต้องจัดทำ Record of Processing Activities (RoPA), ดำเนิน DPIA สำหรับความเสี่ยงสูง และกำหนดฐานทางกฎหมาย (เช่น consent, contract necessity หรือ legitimate interest) สำหรับการประมวลผล นอกจากนี้การถ่ายโอนข้อมูลข้ามพรมแดนอาจต้องพิจารณา SCCs, BCRs หรือข้อจำกัดตามคดีความเช่น Schrems II
การเก็บ logs และ retention policies เพื่อการตรวจสอบย้อนหลัง — สำหรับการตรวจสอบและการรับผิดชอบ จำเป็นต้องมีการบันทึกเหตุการณ์ที่ครอบคลุม เช่น คำขอที่ส่งให้โมเดล, ไอเดนทิตีของผู้ขอ, ผลลัพธ์ที่คืนมา, เวลาที่เกิดเหตุ และการเปลี่ยนแปลงสำคัญของโมเดล แต่ logs เหล่านี้เองก็ควรได้รับการปกป้อง (เข้ารหัสและจำกัดการเข้าถึง) และต้องมีนโยบายการเก็บรักษาที่ชัดเจน เช่น กำหนดระยะเวลาการเก็บ (retention period) ตามความเสี่ยงและข้อกำหนดทางกฎหมาย พร้อมกระบวนการลบที่ตรวจสอบได้ (secure deletion) และการเก็บรักษา logs แบบ immutable สำหรับการตรวจสอบย้อนหลังเมื่อเกิดเหตุ การออกแบบ retention ควรคำนึงถึงสิทธิของเจ้าของข้อมูล (เช่น ขอสั่งลบได้ภายใต้ GDPR) และความจำเป็นขององค์กรในการสำรองข้อมูลเพื่อการปฏิบัติตามกฎหมาย
สรุปแล้ว การรักษาเส้นแบ่งระหว่างข้อมูลภายในกับโมเดลกลางต้องอาศัยทั้งมาตรการทางเทคนิคและกรอบนโยบายที่ชัดเจน ได้แก่ การออกแบบสถาปัตยกรรมที่ปลอดภัย (isolation, encryption, VPC), การปฏิบัติตามหลัก Data Minimization และ Privacy‑by‑Design, การใช้เทคนิคเช่น differential privacy เมื่อฝึกโมเดล รวมถึงการจัดการสิทธิและการเก็บ logs/retention ที่โปร่งใส ทั้งหมดนี้ต้องผนวกกับการประเมินความเสี่ยงทางกฎหมาย (DPIA) และการสื่อสารกับหน่วยงานกำกับดูแลอย่างต่อเนื่องเพื่อให้ RegTech Copilot สามารถให้คุณค่าได้โดยไม่ละเมิดข้อกำหนดด้านความเป็นส่วนตัวและความปลอดภัย
การนำไปใช้จริง: ยุทธศาสตร์การยอมรับในองค์กรและแนวทางปฏิบัติที่แนะนำ
การนำไปใช้จริง: ยุทธศาสตร์การยอมรับในองค์กรและแนวทางปฏิบัติที่แนะนำ
การนำ RegTech Copilot ที่ใช้ Generative‑AI เข้ามาช่วยเขียนและตรวจสอบความสอดคล้องของเอกสารกฎหมายในองค์กรต้องวางแผนเป็นขั้นตอน ตั้งแต่การประเมินความเสี่ยงเชิงธุรกิจและกฎหมาย ไปจนถึงการกำกับดูแลด้านเทคนิคและกระบวนการบริหารการเปลี่ยนแปลง จุดมุ่งหมายคือการลดความเสี่ยงจากข้อผิดพลาดเชิงกฎหมาย ในขณะที่ยังคงรักษามาตรฐานการปฏิบัติตามกฎระเบียบ (compliance) และความรับผิดชอบของหน่วยงานกำกับดูแล (regulator acceptance)
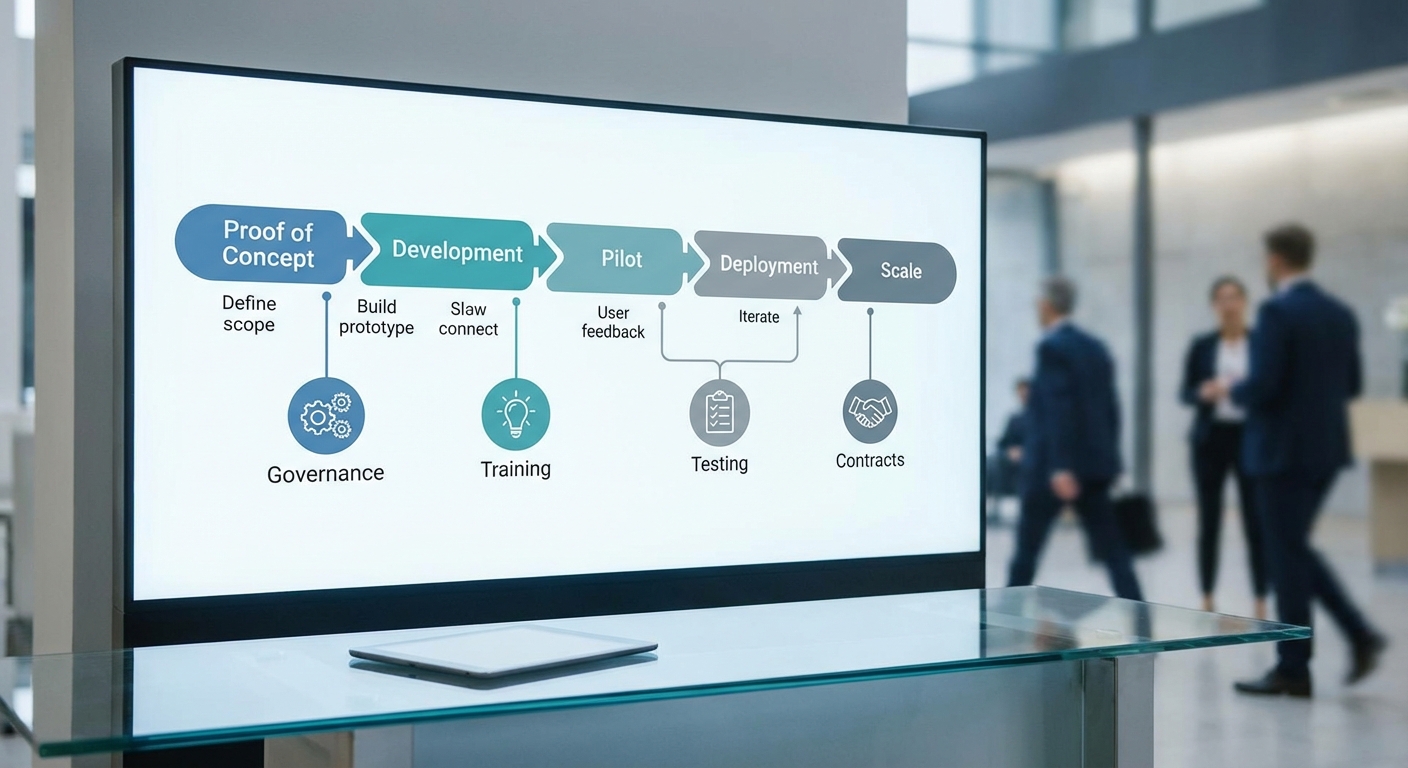
ภาพรวม Roadmap (PoC → Pilot → Scale)
- PoC (Proof of Concept) — ระยะสั้น 4–8 สัปดาห์ เพื่อตรวจสอบความเป็นไปได้ทางเทคนิคและประเมินความแม่นยำเบื้องต้น โดยใช้ชุดเอกสารตัวอย่าง (gold‑standard dataset) ขององค์กรเพื่อวัดอัตราความถูกต้อง (accuracy), อัตราการเกิดข้อมูลเท็จ/สร้างคำตอบผิดพลาด (hallucination rate) และความสอดคล้องกับนโยบายภายใน ตัวชี้วัดตัวอย่าง: ความถูกต้องเชิงกฎหมาย ≥ 85%, hallucination rate < 5%
- Pilot — ขยายสเกลในหน่วยงานที่ควบคุมได้ ระยะ 3–6 เดือน ดำเนินงานในโหมด “human‑in‑the‑loop” เพื่อทดสอบการทำงานร่วมกับกระบวนการจริง เก็บ KPI เพิ่มเติมเช่นเวลาเฉลี่ยในการรีวิวเอกสาร (TTR: time-to‑review), อัตราการยอมรับของผู้ใช้งาน (user acceptance rate) และผลกระทบต่อการปฏิบัติตามกฎระเบียบ (compliance incidents) ตัวอย่างเป้าหมาย: ลด TTR 30–40% ในขณะที่รักษา compliance incidents ไม่เพิ่มขึ้น
- Scale — ขยายไปยังหน่วยงานอื่น ๆ หลังผ่านเกณฑ์การประเมินและ audit การทำงาน ระยะแท้จริงรวมทั้งการจัดตั้งระบบ model monitoring, continuous validation และ governance processes เพื่อจัดการ model drift, data privacy และ contractual SLAs กับผู้ให้บริการ
ในสเตจต่าง ๆ ให้กำหนดชุด KPI ที่ชัดเจน เช่น legal accuracy per clause type, false positive/negative rates ในการแจ้งเตือนการไม่ปฏิบัติตาม, latency และ throughput ของระบบ, อัตราการยกเลิกหรือแก้ไขเอกสารที่สร้างโดย AI เป็นต้น สถิติเชิงภูมิภาคแสดงให้เห็นว่าบริษัทด้านการเงินที่นำ AI เข้ามาช่วยในงานเอกสารสามารถลดเวลารีวิวเอกสารได้ระหว่าง 30–50% ในการทดลองภายใน ซึ่งเป็นตัวอย่างเชิงปฏิบัติที่องค์กรควรใช้เป็นมาตรฐานอ้างอิง
องค์ประกอบของ Governance ที่จำเป็น
การกำกับดูแลต้องผสานทั้งมุมมองทางกฎหมาย เทคนิค และการบริหารความเสี่ยง โดยองค์ประกอบสำคัญประกอบด้วย:
- Legal‑Review Committee — คณะกรรมการข้ามแผนกที่รวม Legal, Compliance, Risk, IT และ Business Owners รับผิดชอบการอนุมัติกรอบการใช้งาน ตรวจสอบผลการทดสอบความถูกต้อง และเป็นจุดติดต่อกับหน่วยงานกำกับดูแลภายนอก
- Model Risk Management (MRM) — กระบวนการประเมินความเสี่ยงของโมเดล ตั้งแต่การ validation ก่อนใช้ การทดสอบ stress test, adversarial testing, monitoring ของ model drift และการประเมิน bias/ความไม่เป็นธรรม (fairness)
- Change Control และ Versioning — นโยบายการเปลี่ยนแปลงโมเดล/พารามิเตอร์/ข้อมูลฝึกอบรมที่เข้มงวด รวมถึงระบบ version control ของโมเดลและเอกสารที่เกี่ยวข้อง เพื่อให้สามารถย้อนกลับ (rollback) และตรวจสอบได้
- Incident Response & Escalation — ขั้นตอนรับมือเมื่อเกิดข้อผิดพลาดทางกฎหมายหรือข้อมูลรั่วไหล กำหนด SLA สำหรับแจ้งเตือน การแก้ไข และการรายงานต่อผู้กำกับดูแล
แนวทางปฏิบัติในการทดลองและการฝึกอบรม
ในระหว่าง PoC และ Pilot ควรดำเนินการแบบ “shadow mode” หรือ “assistive mode” ที่ระบบเสนอคำแนะนำแต่ผู้เชี่ยวชาญยังคงเป็นผู้ตัดสินใจสุดท้าย วิธีนี้ช่วยให้รวบรวม feedback เชิงคุณภาพและปรับปรุงโมเดล โดยมีแนวทางปฏิบัติสำคัญดังนี้:
- ออกแบบชุดทดสอบที่ครอบคลุมกรณีปกติและกรณีขอบ (edge cases) เช่น ข้อตกลงข้ามประเทศ ข้อบังคับเฉพาะอุตสาหกรรม และข้อยกเว้นทางกฎหมาย
- จัดอบรมแบบ role‑based สำหรับผู้ใช้: ทนายความ, เจ้าหน้าที่ compliance และผู้ใช้งานทั่วไป เน้นการตีความผลลัพธ์จาก Copilot, วิธีการตรวจสอบข้อผิดพลาด และขั้นตอนการ eskalate
- ใช้ตัวชี้วัด adoption และ trust เช่น adoption rate, override rate ของผู้เชี่ยวชาญ และความพึงพอใจของผู้ใช้งาน (CSAT)
Checklist สำหรับการรับระบบ (System Acceptance)
รายการตรวจสอบต่อไปนี้เป็นมาตรฐานที่องค์กรควรใช้ก่อนเซ็นรับระบบหรือเปิดใช้งานในสเกลใหญ่:
- Validation Tests
- ชุดทดสอบแบบ hold‑out และ stress tests ครอบคลุม clause types ที่สำคัญ
- วัด metrics เช่น precision, recall, F1‑score แยกตามประเภทข้อกฎหมาย และเกณฑ์ acceptance ที่กำหนด
- ทดสอบความทนทานต่อ adversarial inputs และการจัดการข้อมูลผิดพลาด
- Audit Trail & Logging
- ระบบต้องบันทึกการตัดสินใจของโมเดล เวอร์ชันของโมเดล ข้อมูลอินพุตและผลลัพธ์ (with redaction where necessary)
- ต้องสามารถส่งมอบ logs ให้ regulator หรือทีม audit ภายในได้ตามคำขอ
- User Training & Documentation
- คู่มือการใช้งาน วิธีการตรวจสอบคำแนะนำของ AI และขั้นตอน eskalation
- โปรแกรมอบรมเชิงปฏิบัติและทดสอบความสามารถของผู้ใช้ (certification)
- Contractual Protections กับ Vendor / SLA
- รายละเอียด SLA ด้านความถูกต้อง (accuracy), availability, latency และ incident response
- ข้อกำหนดด้าน data protection และ data residency รวมถึงการเข้าถึงข้อมูลสำหรับการ audit
- clause สำหรับ right to audit, model explainability, และการแจ้งเตือนเมื่อมีการเปลี่ยนแปลง major model updates
- ข้อกำหนดความรับผิดชอบ (liability), indemnity ต่อความเสียหายจากคำแนะนำที่ผิดพลาด และการประกันภัย cyber/AI liability หากจำเป็น
สรุปแล้ว การนำ RegTech Copilot มาใช้ในองค์กรให้สำเร็จต้องอาศัย roadmap ที่ชัดเจน การวัดผลด้วย KPI ที่เกี่ยวข้อง การตั้ง governance ที่รองรับการประเมินความเสี่ยงของโมเดล และการทำสัญญาที่คุ้มครององค์กรต่อความเสี่ยงเชิงกฎหมายและข้อมูล โดยเน้นการทดลองในสเกลเล็ก ปรับปรุงอย่างต่อเนื่อง และการมีมนุษย์เป็นผู้รับผิดชอบขั้นสุดท้ายเพื่อสร้างความเชื่อถือทั้งภายในองค์กรและต่อหน่วยงานกำกับดูแล
บทสรุป
RegTech Copilot มีศักยภาพชัดเจนในการยกระดับประสิทธิภาพการปฏิบัติตามกฎหมายขององค์กร โดยช่วยเร่งการเขียนและตรวจความสอดคล้องของเอกสารกฎหมาย ลดภาระงานเชิงซ้ำซ้อน และเพิ่มความสอดคล้องในการตีความข้อบังคับ ตัวอย่างจากการนำไปใช้เบื้องต้นในภาคการเงินและกฎหมายแสดงให้เห็นว่าการใช้เครื่องมือ Generative‑AI ในกระบวนการตรวจเอกสารสามารถลดเวลาในการตรวจสอบเอกสารได้มากในบางกรณี (ประมาณ 30–50% ในรายงานเชิงกรณีศึกษา) แต่การนำมาใช้ในงานที่มีความเสี่ยงสูงต้องมีการออกแบบมาตรการควบคุมความเสี่ยงและการกำหนดความรับผิดชอบอย่างชัดเจนก่อน เพื่อป้องกันความผิดพลาด การตัดสินใจที่ไม่ถูกต้องตามกฎหมาย และความเสี่ยงด้านความรับผิดทางแพ่งหรืออาญา
เพื่อให้เทคโนโลยีนี้ถูกใช้อย่างปลอดภัยและเป็นไปตามกฎหมาย หน่วยงานกำกับ และ องค์กร ควรร่วมกันสร้างกรอบกำกับดูแลที่เน้นความโปร่งใส (transparency) การตรวจสอบย้อนหลังได้ (auditability) และหลักการ human‑in‑the‑loop โดยกำหนดบทบาทหน้าที่ของมนุษย์ในการตรวจรับผลลัพธ์ การบันทึกหลักฐานการตัดสินใจ และมาตรฐานการทดสอบก่อนนำสู่การใช้งานจริง ในมุมมองอนาคต การพัฒนาแนวปฏิบัติร่วมกัน การทดลองแบบควบคุม (pilot) และการปรับกรอบกฎหมายให้ทันต่อความก้าวหน้าของ AI จะเป็นกุญแจสำคัญที่จะทำให้ RegTech Copilot กลายเป็นเครื่องมือที่เพิ่มประสิทธิภาพเชิงปฏิบัติได้จริง โดยยังคงคุมความเสี่ยงและรักษาความรับผิดชอบของผู้มีอำนาจตัดสินใจในองค์กรได้อย่างชัดเจน



