
OpenAI ประกาศเปิดรับตำแหน่งผู้นำด้านความปลอดภัย (Head of Safety) ท่ามกลางกระแสความกังวลเกี่ยวกับความเสี่ยงจากปัญญาประดิษฐ์—จากการใช้งานในทางที่ผิด ไปจนถึงปัญหาเชิงจริยธรรมและความไม่เสถียรของระบบข่าวสาร การเคลื่อนไหวครั้งนี้ไม่ได้เป็นเพียงการสรรหาตำแหน่งผู้บริหารใหม่ แต่ยังสะท้อนถึงการยกระดับนโยบายเชิงกลยุทธ์เพื่อควบคุมความเสี่ยงทั้งทางเทคนิคและสังคม โดยบทบาทดังกล่าวจะต้องผสานความรู้ด้านวิศวกรรมการเรียนรู้ของเครื่อง การประเมินความเสี่ยง การกำกับดูแล และการประสานงานกับหน่วยงานกำกับดูแลและองค์กรภายนอกเพื่อสร้างมาตรฐานการปฏิบัติที่ปลอดภัยยิ่งขึ้น
บทนำนี้จะชวนผู้อ่านสำรวจประเด็นสำคัญที่บทความจะกล่าวถึง ได้แก่ ขอบเขตหน้าที่ของ Head of Safety และการตั้งความคาดหวังต่อบทบาทดังกล่าว ความท้าทายเชิงเทคนิคที่ต้องเผชิญ เช่น การปรับจูน alignment การทดสอบความทนทานต่อการโจมตี (robustness & red-teaming) ผลกระทบต่อโครงสร้างองค์กรและวัฒนธรรมความปลอดภัย รวมถึงแนวทางการทำงานร่วมกับผู้กำกับดูแลและภาคสังคมเพื่อเพิ่มความโปร่งใสและความเชื่อมั่นของสาธารณะ บทความฉบับเต็มจะให้ภาพรวมเชิงวิเคราะห์พร้อมตัวอย่างและข้อเสนอแนะแนวปฏิบัติที่เป็นประโยชน์สำหรับทั้งภาคอุตสาหกรรมและหน่วยงานกำกับดูแล
บทนำ: ข่าวสำคัญและความหมายเชิงกลยุทธ์
บทนำ: ข่าวสำคัญและความหมายเชิงกลยุทธ์

OpenAI ประกาศเปิดรับตำแหน่ง ผู้นำด้านความปลอดภัย (Head of Safety) ซึ่งเป็นตำแหน่งบริหารระดับสูงที่รับผิดชอบกำหนดแนวทางนโยบายด้านความปลอดภัยของการพัฒนาและการใช้งานปัญญาประดิษฐ์ โดยประกาศดังกล่าวเผยแพร่ในช่วงกลางปี 2024 พร้อมกรอบเวลาเบื้องต้นที่คาดว่าจะสรรหาและแต่งตั้งผู้ดำรงตำแหน่งภายในระยะเวลา 3–6 เดือนข้างหน้า รายละเอียดของตำแหน่งระบุความรับผิดชอบหลักรวมถึงการประสานงานระหว่างทีมวิจัย การปฏิบัติการเชิงวิศวกรรม และหน่วยงานกำกับดูแลภายนอก เพื่อออกแบบมาตรการป้องกันความเสี่ยงเชิงเทคนิคและเชิงนโยบายเมื่อเทคโนโลยีถูกนำไปใช้งานในสเกลกว้าง
สรุปประกาศของ OpenAI โดยย่อมีดังนี้:
- ตำแหน่ง: ผู้นำด้านความปลอดภัย (Head of Safety) — บทบาทบริหารระดับสูง
- ความรับผิดชอบหลัก: วางกรอบนโยบายความปลอดภัย การประเมินความเสี่ยงเชิงระบบ การพัฒนามาตรการลดความเสี่ยงในการใช้งานจริง และการประสานงานกับหน่วยงานกำกับดูแลและพันธมิตรเชิงนโยบาย
- เป้าหมายเชิงกลยุทธ์: ลดความเสี่ยงจากการใช้งาน AI ในระดับองค์กรและสาธารณะ เพิ่มความโปร่งใส และฟื้นฟู/เสริมสร้างความเชื่อมั่นของผู้ใช้และพันธมิตร
- กรอบเวลาเบื้องต้น: การสรรหาเริ่มทันทีและคาดว่าจะมีการแต่งตั้งภายใน 3–6 เดือนหลังประกาศ
สาเหตุเชิงกลยุทธ์ที่ทำให้ OpenAI เร่งแต่งตั้งตำแหน่งนี้ในช่วงเวลานี้มีหลายประการรวมกัน: ปริมาณการนำ AI ไปใช้งานเชิงพาณิชย์และภาครัฐเพิ่มขึ้นอย่างรวดเร็ว ทำให้ความเสี่ยงทั้งด้านความปลอดภัยเชิงเทคนิค (เช่น การใช้งานโมเดลผิดวัตถุประสงค์) และความเสี่ยงเชิงสังคม (เช่น ข้อมูลผิด/บิดเบือน ความเป็นส่วนตัว) มีความสำคัญมากขึ้น นอกจากนี้ ความกดดันจากหน่วยงานกำกับดูแลในหลายประเทศและความคาดหวังจากพันธมิตรองค์กรที่ต้องการมาตรฐานความปลอดภัยที่ชัดเจน ทำให้ OpenAI ต้องมีผู้นำที่รวมทั้งทักษะเชิงเทคนิคและเชิงนโยบายเพื่อจัดการความเสี่ยงในระดับองค์กร
ผลกระทบทันทีที่คาดว่าจะเกิดขึ้นจากการประกาศนี้ต่อความเชื่อมั่นของสาธารณะและพันธมิตรมีทั้งเชิงบวกและความคาดหวังที่เพิ่มขึ้นในเวลาเดียวกัน โดยในเชิงบวก การมีผู้นำด้านความปลอดภัยอย่างชัดเจนช่วยส่งสัญญาณว่า OpenAI ให้ความสำคัญกับการบริหารความเสี่ยงและพร้อมรับผิดชอบต่อการใช้งานเทคโนโลยี ซึ่งอาจช่วยฟื้นฟูความเชื่อมั่นของผู้ใช้บางส่วนและทำให้พันธมิตรภาคธุรกิจและหน่วยงานกำกับดูแลเปิดรับการร่วมมือมากขึ้น ขณะเดียวกัน ผู้มีส่วนได้ส่วนเสียจะจับตากรอบเวลาและมาตรการที่ประกาศจริงเพื่อประเมินว่าการสรรหาและนโยบายที่ออกมาสามารถลดความเสี่ยงเชิงปฏิบัติได้หรือไม่
โดยสรุป การสรรหาผู้นำด้านความปลอดภัยของ OpenAI ไม่เพียงเป็นการเติมตำแหน่งบริหาร แต่ยังเป็นสัญญาณเชิงกลยุทธ์ที่ชี้ให้เห็นถึงการเปลี่ยนผ่านจากการวิจัยเชิงทดลองสู่การบริหารจัดการความเสี่ยงในระดับองค์กรและสาธารณะ — ขณะที่ผู้มีส่วนได้ส่วนเสียทั้งภายในและภายนอกองค์กรเฝ้าดูว่าจะเกิดการเปลี่ยนแปลงเชิงนโยบายและการปฏิบัติอย่างเป็นรูปธรรมตามมาหรือไม่
บริบทเชิงสถิติ: ทำไมความปลอดภัยของ AI ถึงเป็นเรื่องเร่งด่วน
บริบทเชิงสถิติ: ทำไมความปลอดภัยของ AI ถึงเป็นเรื่องเร่งด่วน
การพัฒนา AI ในช่วงไม่กี่ปีที่ผ่านมาไม่ได้เป็นเพียงความก้าวหน้าทางเทคนิคเท่านั้น แต่ยังหมายถึงมูลค่าเชิงเศรษฐกิจและความเสี่ยงเชิงสังคมที่เพิ่มขึ้นอย่างรวดเร็ว ด้วยการประเมินจากหน่วยงานต่างประเทศที่ได้รับความนิยมสูง PwC คาดการณ์ว่า AI อาจเพิ่มมูลค่าต่อผลิตภัณฑ์มวลรวมโลก (GDP) ได้สูงสุดถึง ประมาณ 15.7 ล้านล้านดอลลาร์สหรัฐภายในปี 2030 ซึ่งสะท้อนว่าผลกระทบของ AI จะกระจายไปยังทุกอุตสาหกรรม ตั้งแต่การดูแลสุขภาพ การเงิน ไปจนถึงการผลิต นั่นเป็นเหตุผลว่าการลงทุนเพื่อให้เทคโนโลยีเหล่านี้ใช้งานได้อย่างปลอดภัยและเชื่อถือได้จึงเป็นเรื่องที่ไม่สามารถเลื่อนออกไปได้
ด้านการลงทุนและการวิจัยด้านความปลอดภัยของ AI มีทิศทางเพิ่มขึ้นชัดเจน ทั้งจากภาคเอกชนและสถาบันวิจัย รายงานต่าง ๆ ชี้ว่า การระดมทุนในสตาร์ทอัพด้าน AI และโครงสร้างพื้นฐานที่เกี่ยวข้อง อยู่ในระดับหลายหมื่นล้านดอลลาร์ต่อปี โดยบริษัทเทคฯ รายใหญ่และกองทุนความเสี่ยงได้จัดสรรงบจำนวนมากให้กับโมเดลขนาดใหญ่และการทดสอบความปลอดภัย ตัวอย่างเช่น การลงทุนในบริษัทด้านโมเดลภาษาและการประมวลผลความเร็วสูงจากผู้เล่นรายใหญ่ในตลาดมีมูลค่าตั้งแต่ระดับร้อยล้านถึงพันล้านดอลลาร์ ซึ่งแสดงให้เห็นว่า ทั้งโอกาสทางเศรษฐกิจและความเสี่ยงทางเทคนิค ถูกมองว่าเป็นประเด็นสำคัญในวงการ
ในเชิงเหตุการณ์และการทดสอบเชิงปฏิบัติ การค้นพบช่องโหว่ของระบบ AI มีอยู่เป็นประจำ ตัวอย่างที่เป็นที่รู้จักได้แก่:
- การโจมตีแบบ adversarial: งานวิจัยหลายชุดแสดงให้เห็นวาการเพิ่มสัญญาณรบกวนขนาดเล็กในภาพหรือสัญญาณเสียงสามารถทำให้โมเดลจัดประเภทผิดได้อย่างรุนแรง — เช่น การเปลี่ยนแปลงป้ายจราจรที่ทำให้รถขับเคลื่อนด้วยตัวเองตีความผิด
- การใช้งานผิดวัตถุประสงค์ (misuse & jailbreak): มีการสาธิตการ “เจลเบรก” โมเดลภาษาเพื่อหลีกเลี่ยงมาตรการความปลอดภัยและดึงข้อความหรือคำแนะนำที่เป็นอันตรายออกมาได้อย่างสำเร็จ
- การรั่วไหลของข้อมูลและการโจมตีเชิงย้อนกลับ (model inversion, data extraction): งานทดลองบางชิ้นแสดงว่าโมเดลบางประเภทสามารถเปิดเผยข้อมูลฝึกสอนที่มีความเป็นส่วนตัวได้ หากไม่ได้มีมาตรการป้องกันเพียงพอ
- กรณีตัวอย่างจากอดีต: เช่น กรณีบอทโต้ตอบสาธารณะที่ถูกจัดการให้เผยพฤติกรรมไม่เหมาะสมหรือการตอบสนองที่ผิดพลาดเมื่อได้รับอินพุตที่ผิดปกติ ซึ่งสะท้อนช่องว่างในด้านการควบคุมและการทดสอบเชิงความปลอดภัย
แนวโน้มการกำกับดูแลทั่วโลกสะท้อนความเร่งด่วนเช่นกัน สหภาพยุโรป (EU) ได้ผลักดัน EU AI Act ซึ่งเป็นกรอบกฎหมายเชิงป้องกันที่มุ่งควบคุมการใช้งาน AI ตามระดับความเสี่ยง — เป็นหนึ่งในการตอบสนองเชิงนโยบายที่ชัดเจนที่สุดต่อความกังวลด้านความปลอดภัย ขณะเดียวกันหน่วยงานในสหรัฐฯ เช่น NIST ได้ออกแนวทาง (AI Risk Management Framework) และรัฐบาลกลางได้ประกาศนโยบายต่างๆ เพื่อตอบสนองต่อความเสี่ยงที่อาจเกิดขึ้น จากระดับการป้องกันข้อมูลไปจนถึงการกำกับดูแลการใช้งานระบบอัตโนมัติในภาคบริการสาธารณะ
สรุปได้ว่า เมื่อตัวเลขทางเศรษฐกิจชี้ว่ามูลค่าและการลงทุนใน AI เติบโตอย่างรวดเร็ว ทั้งยังมีเหตุการณ์การทดสอบและการโจมตีที่เผยให้เห็นช่องโหว่ในเชิงปฏิบัติ พร้อมกับแรงกดดันด้านกฎระเบียบที่เพิ่มขึ้น — ทั้งหมดนี้ชี้ชัดว่า ความปลอดภัยของ AI เป็นประเด็นเชิงกลยุทธ์และเชิงนโยบายที่ต้องได้รับการเร่งจัดลำดับความสำคัญ หากต้องการให้เทคโนโลยีสร้างประโยชน์ได้อย่างยั่งยืนและลดผลกระทบเชิงลบต่อสังคมและเศรษฐกิจ
บทบาทและความรับผิดชอบของผู้นำด้านความปลอดภัย
บทบาทและความรับผิดชอบของผู้นำด้านความปลอดภัย
ผู้นำด้านความปลอดภัยขององค์กรที่พัฒนาและนำระบบปัญญาประดิษฐ์ไปใช้งาน มีบทบาทสำคัญเชิงกลยุทธ์และปฏิบัติการ โดยต้องกำหนดทิศทางการบริหารความเสี่ยงจาก AI ทั้งในระดับนโยบายและการปฏิบัติจริง นโยบายความปลอดภัย (safety policy) และ deployment guardrails จะต้องถูกออกแบบให้สอดคล้องกับมาตรฐานสากล เช่น NIST AI RMF, ISO/IEC 27001 และกรอบกฎหมายระดับภูมิภาค (เช่น EU AI Act) เพื่อให้การพัฒนาและการนำระบบออกสู่ตลาดเป็นไปอย่างปลอดภัยและสามารถตรวจสอบได้ โดยผู้นำจะรับผิดชอบในการอนุมัติแนวปฏิบัติ การกำหนดขอบเขตความเสี่ยงที่ยอมรับได้ และการตั้งเกณฑ์การบังคับใช้ก่อนการปล่อยระบบสู่ผู้ใช้
ในเชิงปฏิบัติ ผู้นำต้องจัดตั้งและบริหารทีมทดสอบ (red-team) และกระบวนการประเมินก่อนปล่อยใช้งาน (pre-deployment assessment) อย่างเป็นระบบ ทีม red-team จะทำหน้าที่จำลองการโจมตีเชิงกลยุทธ์ การค้นหารูปแบบการใช้งานที่เสี่ยง การทดสอบช่องโหว่เชิงอัลกอริธึม และการตรวจสอบผลกระทบต่อผู้ใช้ (adversarial testing, scenario-based stress tests) ขณะเดียวกันต้องมีการจัดตั้งกระบวนการตรวจสอบร่วมกับทีมพัฒนา (purple-team) เพื่อให้ผลการทดสอบถูกป้อนกลับเข้าสู่วงจรการพัฒนาอย่างต่อเนื่อง ตัวอย่างการปฏิบัติรวมถึงการตั้งเกตการปล่อย (deployment gates), รายการตรวจสอบความเสี่ยง (risk checklist) และการทดสอบแบบอัตโนมัติที่รันบนสายงาน CI/CD
อีกหนึ่งความรับผิดชอบสำคัญคือการประสานงานกับหน่วยงานภายนอกทั้งในเชิงกฎหมายและเชิงเทคนิค ได้แก่ หน่วยงานกำกับดูแล ผู้เชี่ยวชาญทางวิชาการ องค์กรมาตรฐาน อุตสาหกรรม และศูนย์ตอบสนองเหตุการณ์ไซเบอร์ (CERT) เพื่อแลกเปลี่ยนข้อมูลภัยคุกคาม จัดทำแนวทางปฏิบัติร่วม และรับมือกับเหตุการณ์ข้ามองค์กรได้อย่างรวดเร็ว การทำงานร่วมกับภายนอกยังรวมถึงการจัดให้มีการประเมินอิสระ (third‑party audits) และการเผยแพร่รายงานความปลอดภัยที่สร้างความเชื่อมั่นแก่ผู้ใช้และผู้กำกับดูแล
การวัดผลความปลอดภัยและตัวชี้วัดความสำเร็จ (KPI)
ผู้นำต้องกำหนดชุด KPI เพื่อวัดประสิทธิภาพของมาตรการความปลอดภัยและแสดงความคืบหน้าแก่ผู้บริหาร ตัวอย่าง KPI ที่มักใช้ได้แก่:
- อัตราการลดเหตุการณ์ความเสี่ยง: เป้าหมายเชิงปริมาณ เช่น ลดเหตุการณ์ที่มีผลกระทบต่อผู้ใช้ลง 30–50% ภายใน 12 เดือน หลังนำมาตรการใหม่มาใช้
- อัตราการผ่านเกตการปล่อย (pass rate): สัดส่วนของโมเดลหรือฟีเจอร์ที่ผ่านการประเมินความปลอดภัยก่อนปล่อยใช้งาน (เช่น >95% pass rate)
- เวลาเฉลี่ยในการตรวจจับและตอบสนอง (MTTD / MTTR): ย่อเวลาการตรวจจับและการแก้ไขเหตุการณ์ ตัวอย่างเช่นลด MTTD ลงเหลือภายในไม่กี่ชั่วโมง และ MTTR ภายใน 24–72 ชั่วโมง
- จำนวนข้อค้นพบจาก red-team ต่อการปล่อยใช้งาน: ลดจำนวนข้อค้นพบร้ายแรงต่อปล่อย (severe findings per release) หรือลดจำนวนข้อค้นพบที่ต้องรีคอล (recalls)
- ดัชนีความโปร่งใสและการรายงาน: สัดส่วนของการเผยแพร่ model cards, datasheets และรายงานการประเมินความเสี่ยงสาธารณะ เช่น >80% ของระบบหลักมีเอกสารความโปร่งใสครบถ้วน
- ความพร้อมด้านการปฏิบัติตามกฎระเบียบ: เวลาตอบสนองต่อการร้องขอจากหน่วยงานกำกับดูแลหรือตรวจสอบ (เช่น ตอบภายใน 30 วัน) และจำนวนการตรวจสอบที่ผ่าน
การตั้ง KPI ควรมีการกำหนดเกณฑ์เป้าหมายที่ชัดเจน ระยะเวลาเป้าหมาย และกลไกการรายงาน เช่น แดชบอร์ดความปลอดภัยรายสัปดาห์และรายไตรมาส เพื่อให้คณะผู้บริหารสามารถติดตามผลและจัดสรรทรัพยากรได้ตรงจุด นอกจากนี้ผู้นำควรสนับสนุนวัฒนธรรมการเรียนรู้เชิงรุก โดยใช้ผลลัพธ์จาก KPI เป็นข้อมูลป้อนกลับในการปรับปรุงนโยบาย กระบวนการทดสอบ และมาตรการทางเทคนิคอย่างต่อเนื่อง
ความท้าทายทางเทคนิคและแนวทางลดความเสี่ยง
ความท้าทายทางเทคนิคและแนวทางลดความเสี่ยง
การนำระบบปัญญาประดิษฐ์ไปใช้ในเชิงพาณิชย์และสังคมก่อให้เกิดความท้าทายเชิงเทคนิคหลายด้านที่ส่งผลต่อความปลอดภัยและความน่าเชื่อถือของระบบ โดยประเด็นหลักได้แก่ ปัญหา alignment ที่โมเดลไม่สอดคล้องกับเป้าประสงค์ของผู้ใช้งาน (specification gaming / reward hacking), ความเปราะบางต่อการโจมตีแบบ adversarial ที่สามารถเปลี่ยนผลลัพธ์ได้ด้วยการปรับอินพุตเพียงเล็กน้อย, data poisoning ที่ผู้โจมตีปนเปื้อนข้อมูลการฝึกเพื่อฝัง backdoor หรือบิดเบือนพฤติกรรม, และ model extraction ที่ผู้โจมตีสามารถสังเคราะห์หรือขโมยความสามารถของโมเดลผ่านการสอบถาม API จำนวนมาก งานวิจัยชี้ให้เห็นว่าการโจมตีด้วยตัวอย่าง adversarial สามารถทำให้อัตราความผิดพลาดของโมเดลภาพเพิ่มขึ้นอย่างมีนัยสำคัญ และ backdoor poisoning บางรูปแบบสามารถฝังกุญแจพฤติกรรมได้แม้จะใช้ข้อมูลปนเปื้อนเพียง สัดส่วนน้อยกว่า 1% ของชุดฝึก
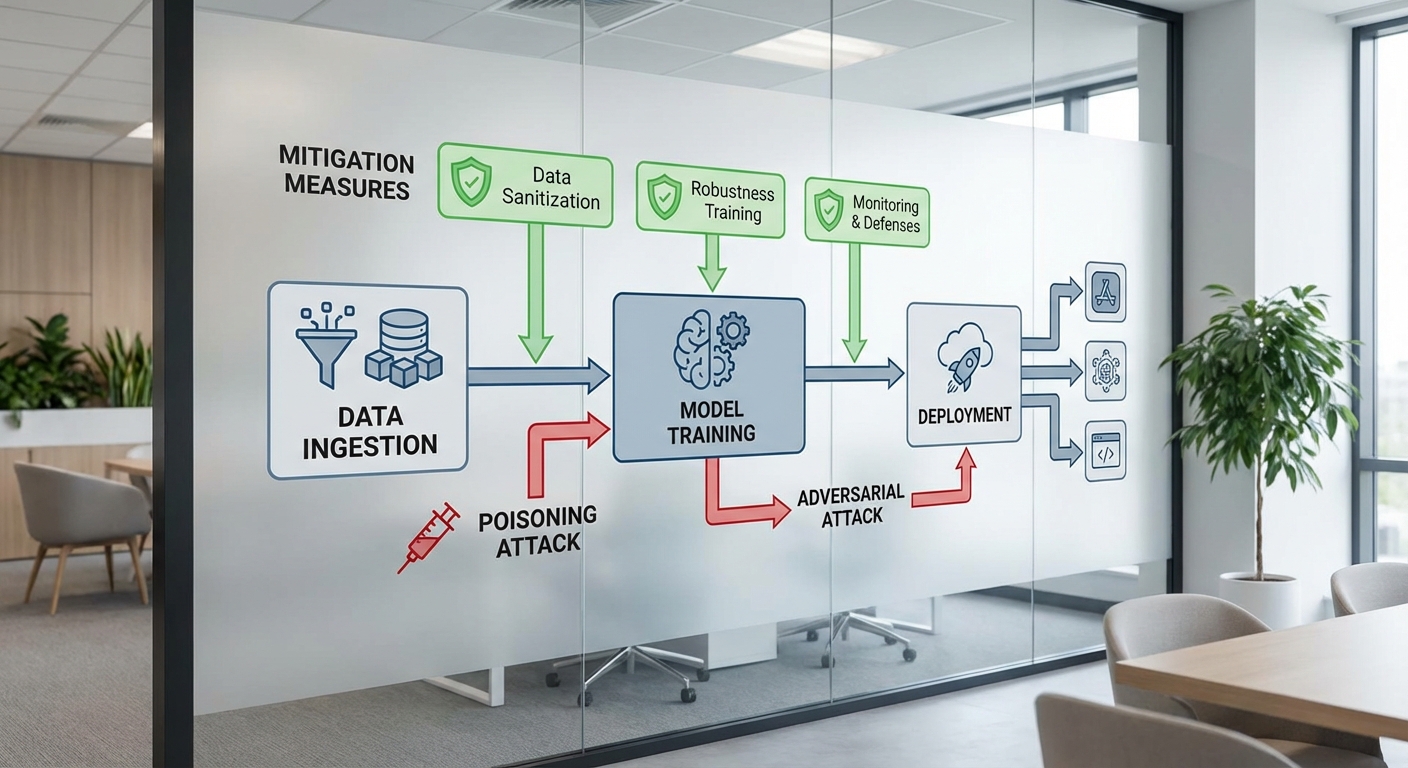
เพื่อรับมือกับความเสี่ยงเหล่านี้ จำเป็นต้องใช้แนวทางเชิงวิศวกรรมและกระบวนการผสานกันหลายชั้น (defense-in-depth) เริ่มจากการออกแบบความปลอดภัยตั้งแต่ต้น (secure-by-design): ทำ threat modelling สำหรับโมเดลและข้อมูล, กำหนดขอบเขตการใช้งานที่ชัดเจน, และบังคับหลักการ least privilege สำหรับการเข้าถึงข้อมูลและแบบจำลอง นอกจากนี้เทคนิคลดความเสี่ยงที่ได้ผลรวมถึงการทำ adversarial training เพื่อเพิ่มความทนต่อการโจมตีเชิงตัวอย่าง, การใช้ differential privacy (เช่น DP-SGD) และการจำกัดการตอบกลับของ API เพื่อป้องกันการสกัดโมเดล (model extraction)
ในเชิงปฏิบัติ การทดสอบและตรวจสอบอย่างต่อเนื่องเป็นสิ่งจำเป็น: red-teaming และการทดสอบเชิงโจมตีแบบอัตโนมัติ (adversarial testing) ควรถูกวางไว้เป็นส่วนหนึ่งของวงจรการพัฒนา โดยกลุ่ม red team จะทดลองโจมตีทั้งในระดับอินพุต (adversarial examples), ระดับข้อมูล (poisoning/backdoor) และระดับแอปพลิเคชัน (API abuse, prompt injection) เพื่อค้นหาช่องโหว่ก่อนเปิดใช้งานจริง นอกจากนี้ควรมี continuous monitoring ของเมตริกการทำงาน — เช่น drift detection, distribution shift alerts, prediction uncertainty และการตรวจจับพฤติกรรมผิดปกติของผู้เรียก API — เพื่อให้สามารถตอบสนองแบบเรียลไทม์ด้วย measures เช่น canary rollback, rate limiting และ circuit breakers
ตัวอย่างเครื่องมือและแนวปฏิบัติที่องค์กรสามารถนำไปใช้ได้จริง ได้แก่:
- Adversarial testing / libraries: IBM Adversarial Robustness Toolbox (ART), Foolbox, CleverHans สำหรับสร้างและประเมินตัวอย่าง adversarial
- Privacy & robustness: TensorFlow Privacy, PyTorch Opacus สำหรับการฝึกด้วย differential privacy; Certifiable robustness frameworks สำหรับการประเมินความทนทาน
- Data provenance & ingestion: ระบบบันทึกแหล่งข้อมูล (data lineage) และการตรวจสอบความสมบูรณ์ของข้อมูล เช่น Great Expectations หรือ Evidently AI เพื่อลดความเสี่ยงจาก data poisoning
- Deployment & runtime security: Seldon Core, BentoML, Kubeflow + Istio/Envoy สำหรับการ deploy แบบปลอดภัย พร้อม rate limiting, authentication, และ mTLS; ใช้ secure enclaves (เช่น Intel SGX) หรือการเข้ารหัสแบบ homomorphic เมื่อจำเป็นสำหรับข้อมูลที่มีความเสี่ยงสูง
- Model governance & auditing: MLflow, Pachyderm หรือระบบบันทึกเวอร์ชันโมเดลและเมตาดาต้า ร่วมกับการลงนามดิจิทัลของโมเดลและการจัดการคีย์ (KMS) เพื่อตรวจย้อนกลับและป้องกันการแก้ไขโมเดลโดยมิชอบ
- Operational practices: การทำ red-team / purple-team exercises, การตั้ง bug bounty สำหรับช่องโหว่โมเดล, playbook สำหรับ incident response และการฝึกซ้อมแผนฉุกเฉิน
สุดท้าย การสร้างวัฒนธรรมความปลอดภัยภายในองค์กรเป็นกุญแจสำคัญ — นอกเหนือจากเทคนิคแล้วต้องมีนโยบายชัดเจนสำหรับการทดสอบก่อนปล่อย, การจัดการสิทธิ์การเข้าถึง, รวมถึงการรายงานและแก้ไขช่องโหว่อย่างโปร่งใส การลงทุนในกระบวนการเหล่านี้ไม่เพียงลดความเสี่ยงเชิงเทคนิค แต่ยังปกป้องความเชื่อมั่นของลูกค้าและภาพลักษณ์ขององค์กรเมื่อเทคโนโลยี AI ถูกนำมาใช้ในระดับการผลิต
ผลกระทบต่อองค์กร การกำกับดูแล และความร่วมมือระหว่างภาคส่วน
ผลกระทบต่อองค์กร การกำกับดูแล และความร่วมมือระหว่างภาคส่วน
การแต่งตั้งผู้นำด้านความปลอดภัย (Chief AI Safety Officer หรือเทียบเท่า) จะส่งผลกระทบทันทีต่อโครงสร้างการกำกับดูแลภายในองค์กร โดยทำให้เรื่องความเสี่ยงจากระบบปัญญาประดิษฐ์ถูกยกระดับจากการเป็นหน้าที่ของฝ่ายเทคนิคเพียงฝ่ายเดียวสู่การเป็นประเด็นเชิงกลยุทธ์ที่ต้องมีการติดตามจากระดับผู้บริหาร และคณะกรรมการกำกับดูแล (board-level oversight) ในทางปฏิบัติ องค์กรมักต้องสร้างหรือปรับรูปแบบคณะกรรมการย่อยด้านความเสี่ยง AI (AI risk committee), ระบุบทบาทความรับผิดชอบข้ามหน่วยงาน (เช่น กฎหมาย นโยบายผลิตภัณฑ์ ความเป็นส่วนตัว และความปลอดภัยไซเบอร์) และกำหนดวัฏจักรการประเมินความเสี่ยงที่มีระยะเวลาเป็นรูปธรรม เช่น การทบทวนโมเดลเชิงนโยบายทุกไตรมาส หรือการทดสอบ red-team เชิงอิสระปีละครั้ง
ในด้านกระบวนการปฏิบัติ การมีผู้นำด้านความปลอดภัยช่วยให้เกิดระบบกำกับภายในที่ชัดเจนมากขึ้น ได้แก่ การบังคับใช้การทำ model documentation (เช่น model cards), การจัดทำการประเมินผลกระทบด้านจริยธรรมและความเป็นส่วนตัวก่อนนำสู่การใช้งานจริง (pre-deployment impact assessment) และการตั้งเกณฑ์ชี้วัด (KPIs) สำหรับความเสี่ยงที่วัดได้ เช่น เป้าหมายลดจำนวนเหตุการณ์ความปลอดภัยที่เกี่ยวข้องกับ AI ลงร้อยละ X ภายในหนึ่งปีหรือกำหนดเวลาเฉลี่ยในการตอบสนองต่อเหตุการณ์ (mean time to detect/mean time to remediate)
ความร่วมมือกับภาครัฐและหน่วยงานกำกับดูแลเป็นสิ่งจำเป็นเพื่อให้การดำเนินงานสอดคล้องกับนโยบายภายนอกและมาตรฐานที่กำลังพัฒนา องค์กรต้องมีช่องทางสื่อสารและประสานงานกับหน่วยงานกำกับดูแลระดับชาติและระหว่างประเทศ, กระทรวงที่เกี่ยวข้องกับดิจิทัลและความมั่นคง, รวมถึงหน่วยงานคุ้มครองข้อมูลส่วนบุคคล ตัวอย่างความร่วมมือเชิงนโยบายอาจรวมถึงการแบ่งปันข้อมูลเชิงเทคนิคสำหรับการประเมินความเสี่ยงระดับระบบ การตอบสนองต่อคำถามกำกับดูแล (regulatory inquiries) และการเข้าร่วมการทดลองนโยบาย (regulatory sandboxes) ซึ่งช่วยให้ทั้งภาครัฐและภาคเอกชนสามารถทดสอบกรอบการกำกับดูแลที่เหมาะสมก่อนใช้งานจริง
นอกจากภาครัฐแล้ว การทำงานร่วมกับสถาบันวิจัยและภาคประชาสังคมมีบทบาทสำคัญในการกำหนดมาตรฐานร่วมและเพิ่มความเชื่อถือของสาธารณะ สถาบันวิจัยสามารถให้การประเมินอิสระ เช่น การตรวจสอบโดย third‑party audits, การประเมินความเสี่ยงเชิงวิชาการ หรือการเผยแพร่ผลการทดสอบเชิงเทคนิค ส่วนองค์กรภาคประชาสังคมช่วยเติมมุมมองเชิงสังคม จริยธรรม และสิทธิมนุษยชน ทำให้นโยบายของบริษัทไม่เพียงมุ่งเน้นเชิงเทคนิค แต่ยังคำนึงถึงผลกระทบต่อชุมชนและกลุ่มผู้เปราะบางด้วย
- การปรับโครงสร้างภายใน: สร้างบทบาทผู้รับผิดชอบเชิงกลยุทธ์ ระบุคณะกรรมการย่อยและช่องทางรายงานถึงบอร์ด เพิ่มกระบวนการประเมินและการทดสอบเป็นวัฏจักร
- การประสานกับหน่วยงานกำกับ: ตั้งช่องทางสื่อสารกับหน่วยงานกำกับดูแล เข้าร่วม sandboxes และปฏิบัติตามกรอบกฎหมายระดับประเทศและระหว่างประเทศ (เช่น กรอบ EU AI Act และมาตรฐานสากลที่เกี่ยวข้อง)
- การร่วมมือกับภาควิชาการและภาคประชาสังคม: เปิดรับการตรวจสอบอิสระ ใช้มาตรการประเมินภายนอก และร่วมพัฒนามาตรฐานร่วมเพื่อความโปร่งใสและยอมรับทางสังคม
- ความโปร่งใสและการสื่อสารสาธารณะ: ปล่อยรายงานความปลอดภัย, model cards, และการแจ้งเหตุการณ์สำคัญต่อสาธารณะอย่างเหมาะสมเพื่อสร้างความไว้วางใจ
สุดท้ายนี้ ความโปร่งใสและการสื่อสารสาธารณะเป็นกลไกสำคัญในการสร้างและรักษาความไว้วางใจจากผู้ใช้งาน นักลงทุน และหน่วยงานกำกับดูแล องค์กรควรกำหนดนโยบายการเปิดเผยข้อมูลที่สมดุล ระบุระดับรายละเอียดที่เหมาะสมสำหรับสาธารณะและผู้เชี่ยวชาญ เช่น การเผยแพร่รายงานความเสี่ยงประจำปี การประกาศแนวนโยบายเมื่อเกิดเหตุการณ์ที่มีผลกระทบสูง และการจัดเวทีให้ผู้มีส่วนได้เสียได้มีส่วนร่วม ซึ่งงานวิจัยหลายชิ้นแสดงให้เห็นว่าองค์กรที่มีการสื่อสารเชิงโปร่งใสมีแนวโน้มจะได้รับความไว้วางใจจากประชาชนและหน่วยงานกำกับดูแลมากขึ้นเมื่อเทียบกับองค์กรที่ปิดข้อมูล
เสียงจากผู้เชี่ยวชาญและการตอบรับจากวงการ
เสียงจากผู้เชี่ยวชาญและการตอบรับจากวงการ
ผู้เชี่ยวชาญด้านความปลอดภัย AI ให้การต้อนรับการประกาศของ OpenAI ด้วยท่าทีที่หลากหลาย โดยส่วนใหญ่ชื่นชมแนวคิดในการแต่งตั้งผู้นำด้านความปลอดภัยระดับสูงซึ่งจะเป็นแกนกลางในการกำหนดมาตรฐานและวางกรอบการทำงานเชิงนโยบาย ตัวแทนจากสถาบันวิจัยด้านความเสี่ยงเทคโนโลยีกล่าวว่า "การมีผู้นำด้านความปลอดภัยที่ชัดเจนช่วยเพิ่มความเป็นไปได้ในการประสานงานระหว่างทีมวิจัย วิศวกรรม และผู้กำกับดูแล ทั้งยังเป็นสัญญาณเชิงบวกต่อนักพัฒนาภายนอกและผู้มีส่วนได้ส่วนเสีย" ในทางเดียวกัน นักวิชาการบางท่านเตือนว่าการแต่งตั้งเพียงอย่างเดียวไม่เพียงพอ หากไม่มีความโปร่งใสในการดำเนินงานและการรายงานผลที่ชัดเจน ความเสี่ยงเชิงระบบยังคงอยู่
ผู้กำกับนโยบายและหน่วยงานกำกับดูแล ให้ความสำคัญกับการริเริ่มนี้ในฐานะส่วนหนึ่งของการยกระดับการกำกับดูแลภาคเอกชน หลายหน่วยงานระบุว่าการมีผู้นำด้านความปลอดภัยของบริษัทเทคโนโลยีระดับสูงอาจช่วยลดช่องว่างระหว่างแนวปฏิบัติของภาคเอกชนกับกรอบกฎหมาย เช่นกฎของสหภาพยุโรป (AI Act) และแนวทางการกำกับดูแลในสหรัฐฯ แต่ก็มีข้อเรียกร้องจากผู้กำกับดูแลให้มีการตรวจสอบอิสระและมาตรฐานการรายงานเหตุการณ์ความปลอดภัยอย่างเป็นรูปธรรมเพื่อป้องกันการพึ่งพาการประเมินภายในเพียงอย่างเดียว
การเปรียบเทียบกับแนวปฏิบัติของบริษัทเทคโนโลยีอื่น แสดงให้เห็นรูปแบบที่แตกต่างกันแต่มีจุดร่วมด้านการยกระดับความปลอดภัย:
- Google DeepMind: โฟกัสที่การวิจัยเชิงลึกด้าน alignment และการทดสอบทางวิทยาศาสตร์ มีการเผยแพร่ผลงานด้าน safety เป็นประจำและร่วมมือกับชุมชนวิชาการเพื่อพัฒนาเกณฑ์การประเมินความเสี่ยง
- Anthropic: ให้ความสำคัญกับแนวทางเชิงนโยบายและกระบวนการด้านการออกแบบโมเดล (เช่น Constitutional AI) เพื่อสร้างพฤติกรรมที่สอดคล้องกับค่ามนุษยธรรมและลดพฤติกรรมที่ไม่พึงประสงค์
- OpenAI: การประกาศหาผู้นำด้านความปลอดภัยสะท้อนการมุ่งสู่การรวมงานด้าน governance, red-team และการประเมินความเสี่ยงเชิงระบบเข้าด้วยกัน หากดำเนินควบคู่กับการเผยแพร่รายงานความปลอดภัยและการตรวจสอบอิสระ จะสอดคล้องกับแนวทางของคู่แข่งที่ให้ความสำคัญกับความโปร่งใส
การประเมินจากตลาดและนักลงทุน แสดงให้เห็นว่าการลงทุนในองค์ประกอบด้านความปลอดภัยของ AI ถูกมองว่าเป็นปัจจัยสำคัญต่อมูลค่าและความน่าเชื่อถือ ผู้ลงทุนสถาบันและพันธมิตรธุรกิจมักประเมินความเสี่ยงด้านการกำกับดูแลและโอกาสการนำไปใช้เชิงพาณิชย์ เมื่อบริษัทสามารถนำเสนอกรอบการทำงานด้านความปลอดภัยที่ชัดเจนและมาตรฐานการตรวจสอบที่เชื่อถือได้ จะช่วยลดความไม่แน่นอนทางการลงทุนและเอื้อต่อการขยายธุรกิจสู่ลูกค้าองค์กร ตัวอย่างเช่น ลูกค้าองค์กรขนาดใหญ่มักมีข้อกำหนดด้าน compliance ก่อนสัญญาซื้อขาย ทำให้การแสดงความมุ่งมั่นด้าน safety กลายเป็นปัจจัยแข่งขันทางการตลาด
สรุปได้ว่าแม้การประกาศของ OpenAI จะได้รับการตอบรับเชิงบวกจากหลายฝ่าย แต่ความคาดหวังที่แท้จริงขึ้นอยู่กับรายละเอียดการปฏิบัติ ได้แก่ การแต่งตั้งบุคลากรที่มีความเชี่ยวชาญ การกำหนดตัวชี้วัดความสำเร็จที่ชัดเจน การร่วมมือกับชุมชนวิจัยและหน่วยงานกำกับดูแล และการเปิดเผยข้อมูลแก่สาธารณะ เพื่อให้ความพยายามด้านความปลอดภัยเปลี่ยนเป็นความเชื่อมั่นในเชิงธุรกิจและลดความเสี่ยงต่อระบบนิเวศ AI ในภาพรวม
มองไปข้างหน้า: ผลลัพธ์ที่คาดหวังและขั้นตอนต่อไป
มองไปข้างหน้า: ผลลัพธ์ที่คาดหวังและขั้นตอนต่อไป
การสรรหาผู้นำด้านความปลอดภัยของ OpenAI จะเป็นจุดเปลี่ยนสำคัญที่ควรติดตามทั้งในระยะสั้นและระยะยาว ในระยะสั้น (3–12 เดือน) ผู้มีบทบาทนี้น่าจะเร่งปรับโครงสร้างกระบวนการประเมินความเสี่ยง เช่น การจัดตั้งทีม red-team ที่มีความเชี่ยวชาญเฉพาะด้าน การออกมาตรฐานภายในสำหรับการทดสอบก่อนการปล่อยระบบ (pre-deployment testing) และการกำหนดขั้นตอนการระงับการใช้งานชั่วคราว (deployment pauses) เมตริกที่ชัดเจนและสามารถวัดผลได้ในระยะสั้น ได้แก่ จำนวนการทดสอบ red-team ที่ดำเนินการ ตัวเลขจุดบกพร่องที่ค้นพบ (vulnerabilities found) และเวลาที่ใช้ในการแก้ไข (time-to-fix)
ในระยะยาว (1–3 ปีขึ้นไป) ผลลัพธ์ที่คาดหวังคือการยกระดับวัฒนธรรมความปลอดภัยให้ฝังอยู่ในวงจรการพัฒนาผลิตภัณฑ์ (safety-by-design) และการสร้างความโปร่งใสต่อสาธารณะมากขึ้น ตัวชี้วัดเช่นรายงานการตรวจสอบภายนอก (audit results), การเผยแพร่รายงานความปลอดภัยเป็นระยะ (quarterly or annual safety reports), และการมีส่วนร่วมของผู้ตรวจสอบอิสระจะเป็นตัวบ่งชี้ถึงความเป็นผู้รับผิดชอบ นอกจากนี้ คาดว่าจะเห็นการนำมาตรฐานด้านความปลอดภัยไปใช้อย่างกว้างขวางในอุตสาหกรรม ซึ่งช่วยลดความเสี่ยงเชิงระบบและเพิ่มความเชื่อมั่นของลูกค้าและหน่วยงานกำกับดูแล
มีตัวชี้วัดและหลักฐานที่ผู้ติดตามควรสังเกตอย่างใกล้ชิด รวมถึงรูปแบบการเปิดเผยข้อมูลที่เป็นรูปธรรม ตัวอย่างเช่น:
- รายงาน red-team: จำนวนการทดสอบ รายละเอียดช่องโหว่ที่ค้นพบ ระดับความรุนแรง และการแก้ไขที่ทำแล้ว
- ผลการตรวจสอบ (audit results): รายงานจากผู้ตรวจสอบภายนอกที่ชี้วัดการปฏิบัติตามมาตรฐานความปลอดภัยและความสามารถในการจัดการความเสี่ยง
- การระงับการนำระบบขึ้นใช้งาน (deployment pauses): บันทึกเหตุการณ์ การตัดสินใจยับยั้งการเปิดตัว และมาตรการแก้ไขที่ตามมา
- ตัวชี้วัดการตอบสนอง: เวลาตั้งแต่ค้นพบปัญหาไปจนถึงการแก้ไข (mean time to remediate) และอัตราการเกิดซ้ำของช่องโหว่
- ความโปร่งใสต่อสาธารณะ: การเผยแพร่รายงานความปลอดภัยแบบสรุปหรือฉบับเต็มอย่างสม่ำเสมอ
เพื่อให้การดำเนินการมีประสิทธิผล ขอเสนอแนวทางปฏิบัติสำหรับผู้มีส่วนได้ส่วนเสียหลัก:
- สำหรับผู้บริหาร (Executives): ตั้งเป้าหมายเชิงปริมาณด้านความปลอดภัยเป็น KPI ระบุงบประมาณและทรัพยากรสำหรับการทดสอบเชิงรุก สนับสนุนความโปร่งใสและการตรวจสอบภายนอก และกำหนดกรอบการตัดสินใจในกรณีที่ต้องยับยั้งการปล่อยระบบ
- สำหรับนักพัฒนาและทีมวิจัย: นำแนวคิด safety-by-design เข้าสู่วงจรพัฒนา ตั้งกระบวนการ red-team และ bug bounty เป็นมาตรฐานก่อนการ deploy จัดทำเอกสารการตัดสินใจเชิงความปลอดภัยและบันทึกการทดสอบเพื่อนำไปสู่การตรวจสอบย้อนหลังได้
- สำหรับผู้กำหนดนโยบายและหน่วยงานกำกับ: สนับสนุนมาตรฐานการรายงานความเสี่ยงที่เป็นรูปธรรม ส่งเสริมการตรวจสอบอิสระ และสร้างช่องทางความร่วมมือสาธารณะ-เอกชนเพื่อแลกเปลี่ยนแนวปฏิบัติที่ดีที่สุด
จุดที่ควรจับตามองในช่วงการสรรหาและหลังการแต่งตั้ง ได้แก่: วันที่ประกาศการแต่งตั้งและขอบเขตอำนาจของผู้นำ ความถี่ของการเผยแพร่รายงานความปลอดภัย (เช่น รายไตรมาส) รายละเอียดของรายงาน red-team และผลการตรวจสอบจากภายนอก รวมถึงนโยบายการยับยั้งการเปิดตัวที่ชัดเจน การมีมาตรการเหล่านี้และการรายงานที่สม่ำเสมอจะเป็นหลักฐานที่ชัดเจนว่าองค์กรกำลังก้าวไปสู่ระบบ AI ที่มีความปลอดภัยและมีความรับผิดชอบมากขึ้น
สรุปคือ การแต่งตั้งผู้นำด้านความปลอดภัยที่มีอำนาจเชิงนโยบายและทรัพยากร จะช่วยสร้างมาตรฐานภายในและส่งสัญญาณเชิงบวกต่ออุตสาหกรรม แต่ความสำเร็จจริงจะวัดได้จากความโปร่งใสของรายงาน ผลลัพธ์จากการทดสอบภายในและภายนอก และระดับการร่วมมือระหว่างผู้บริหาร นักพัฒนา และผู้กำหนดนโยบาย การติดตามตัวชี้วัดเชิงปริมาณและการเรียกรายงานที่เป็นรูปธรรมเป็นสิ่งจำเป็นสำหรับผู้ที่ต้องการประเมินความก้าวหน้าอย่างรอบคอบและเป็นมืออาชีพ
บทสรุป
การแต่งตั้งผู้นำด้านความปลอดภัยของ OpenAI ถือเป็นสัญญาณชัดเจนว่าองค์กรชั้นนำในวงการปัญญาประดิษฐ์ให้ความสำคัญกับการบริหารความเสี่ยงเชิงรุกและความโปร่งใสในการพัฒนา AI มากขึ้น ตำแหน่งดังกล่าวจะมีบทบาทประสานงานระหว่างทีมวิศวกรรมความปลอดภัย การกำหนดนโยบายภายใน และการสื่อสารกับภาคประชาสังคมและหน่วยงานกำกับดูแล เพื่อจำกัดความเสี่ยงเชิงเทคนิคและสังคม เช่น การทำ red‑teaming, การตรวจสอบโมเดล (model audits) และการรายงานข้อมูลความปลอดภัยสู่สาธารณะ เพื่อสร้างความเชื่อมั่นและลดความเสี่ยงจากการนำระบบไปใช้ในวงกว้าง
ความสำเร็จของการริเริ่มนี้ขึ้นกับการผสานกันของมาตรการทางเทคนิค นโยบายองค์กร การร่วมมือจากภายนอก และกรอบการกำกับดูแลที่ชัดเจน ผู้สังเกตการณ์และผู้มีส่วนได้ส่วนเสียควรติดตามผลเป็นรายไตรมาสโดยใช้ตัวชี้วัด เช่น จำนวนเหตุการณ์ความปลอดภัยที่รายงาน ผลการตรวจสอบอิสระ การตัดสินใจระงับการปล่อยใช้งาน และรายงานความคืบหน้าด้านการป้องกันเชิงเทคนิค หากรายงานไตรมาสต่อไตรมาสแสดงถึงความก้าวหน้าเชิงระบบ การแต่งตั้งนี้อาจเป็นก้าวสำคัญสู่วงการ AI ที่ปลอดภัยขึ้น แต่หากขาดความโปร่งใสหรือการลงมือปฏิบัติอย่างจริงจัง ผลลัพธ์อาจเป็นเพียงสัญลักษณ์เท่านั้น
📰 แหล่งอ้างอิง: CBS News